
AUTO_INCREMENT Is Silently Throttling Your Writes
Why MySQL's oldest ID generator becomes a bottleneck at scale and what to replace it with


For years, AUTO_INCREMENT has been the boring, obvious choice. You declare id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY, and MySQL hands out unique numbers. Nobody questions it because it just works.
Then your write volume crosses some invisible line - usually in the tens of thousands of inserts per second - and things get strange. Your p99 insert latency starts climbing. Your CPU looks fine. Your I/O looks fine. But inserts are queueing, and you can’t figure out why.
The culprit is the auto-increment counter itself. Under the hood, it’s a lock. And locks don’t scale.
The hidden mechanism
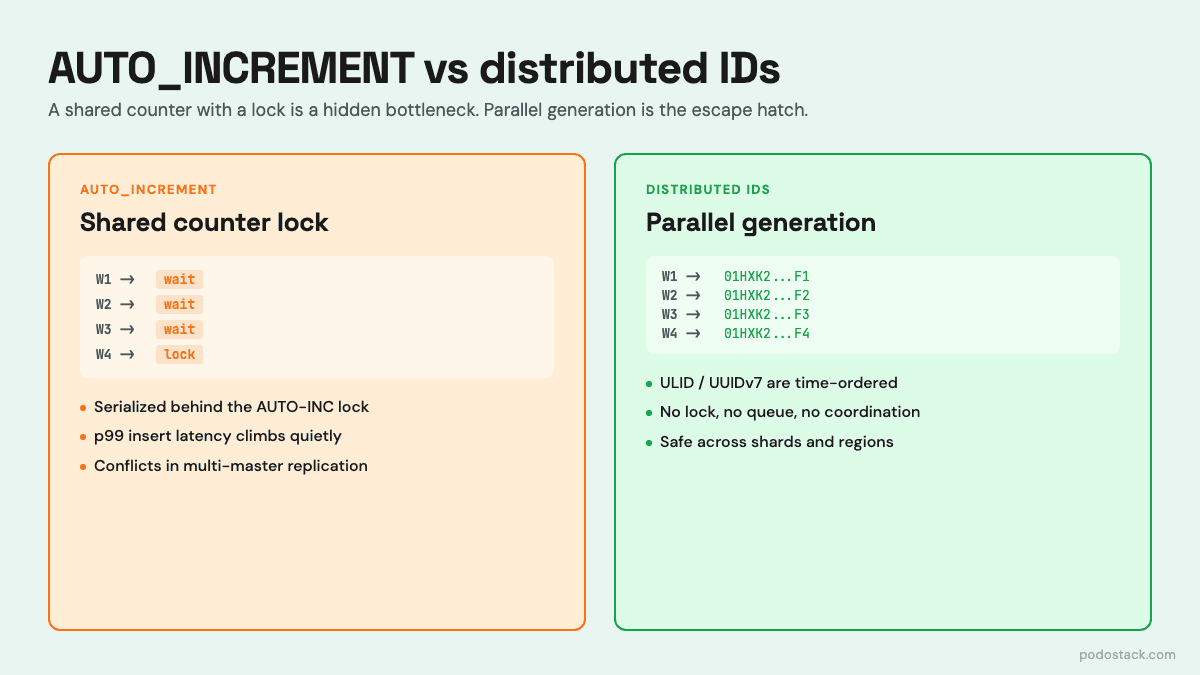
When you insert a row into a table with AUTO_INCREMENT, InnoDB needs to hand you a unique monotonically increasing integer. The way it does that is with a special lock called the AUTO-INC lock. The lock is acquired, the counter is incremented, the new value is stored in your row, the lock is released.
In the default innodb_autoinc_lock_mode = 1 (”consecutive”), the lock is held only for the duration of the increment - brief, but still serialized across all concurrent inserts into that table. Under heavy concurrency, you end up with threads queueing behind each other for nothing but their turn to get a number.
innodb_autoinc_lock_mode = 2 (”interleaved”) relaxes this and avoids the lock for simple inserts, but at the cost of non-consecutive IDs within a transaction. If anything in your codebase or replication tooling assumes contiguous IDs, mode 2 will break it.
Either way, the AUTO-INC counter is a single point of serialization. It’s invisible until you’re doing tens of thousands of writes per second, and then it shows up as insert latency that no amount of CPU or disk tuning can fix.
When it stops scaling
There are three scenarios where AUTO_INCREMENT reliably breaks down:
Single-table write storms. Your event log, your audit trail, your analytics event sink - anything that funnels writes from many sources into one table. The AUTO-INC lock becomes the serialization point for everything.
Multi-master replication. If you’re running MySQL group replication or multi-source replication with writes on multiple nodes, two masters can hand out the same ID at roughly the same time. The classic fix is auto_increment_increment and auto_increment_offset - master A hands out 1, 3, 5, 7; master B hands out 2, 4, 6, 8 - but that only works for exactly two masters and breaks when you add a third. And the moment you fail over and the offset assignment drifts, you get duplicate key errors in replication.
Distributed IDs as external references. The AUTO_INCREMENT ID of your users table starts appearing in URLs, in Kafka messages, in caches, in other services’ foreign keys. Now you have a problem if you ever need to split the users table across shards. There’s no way to shard cleanly by an integer that was handed out sequentially - all your recent users end up on the same shard.
The distributed alternatives
When AUTO_INCREMENT is the bottleneck, the answer is to move ID generation out of the storage layer. You have three common choices:
UUID (version 4). 128 bits of random data. Guaranteed unique across any number of writers without coordination. The downside for MySQL specifically: UUIDs are effectively random, so inserting them into the primary B-tree causes scattered writes and destroys your cache locality. This is why naive UUID primary keys kill MySQL performance on large tables. UUIDv7 (time-ordered) fixes most of this and should be the default when you need a globally unique ID in 2026.
ULID. 128 bits, but the high bits are a millisecond timestamp. The result sorts roughly in time order, which makes it much friendlier to B-tree indexes. Same no-coordination property as UUID. Slightly less standard than UUID but widely supported.
Snowflake-style IDs. 64 bits: timestamp + machine ID + sequence. The ID fits in a BIGINT, sorts by time, and can be generated by any worker as long as each worker has a unique machine ID. Twitter invented this, Discord uses it, Instagram uses a variant. It’s the choice when you want distributed generation but also want numeric IDs that fit in existing schemas.
For any new schema at scale, I’d default to ULID or UUIDv7 for the primary key and never look back. The storage overhead - 16 bytes versus 8 for BIGINT - is a rounding error compared to the scaling properties you get.
The migration trap
Here’s the part people underestimate. Switching from AUTO_INCREMENT to distributed IDs on an existing schema is a whole project, not a one-line change.
Your foreign keys all point at integer IDs. Your indexes are sized for BIGINT. Your application code parses IDs as integers. Your event payloads serialize them as numbers. Every one of those assumptions needs to be revisited. The safe pattern is to add a new column - public_id BINARY(16) for UUID, or VARCHAR(26) for ULID - populate it for new rows first, backfill in the background, switch read paths one at a time, and only then retire the integer ID as the external reference.
The old integer ID can stay as a clustered primary key for InnoDB storage efficiency. You use the new distributed ID as the external-facing reference. This hybrid is often the right answer - you get the InnoDB benefit of a sequential integer clustered key, plus the distributed ID for everything that crosses a service boundary.
A debugging checklist
Before you conclude that AUTO_INCREMENT is your bottleneck, verify. The symptoms overlap with other issues.
Run
SHOW ENGINE INNODB STATUS\Gand look for threads waiting on the AUTO-INC lock.Query
performance_schema.data_locksfiltered to your hot table.Check
innodb_autoinc_lock_mode- if it’s 1 and you’re seeing contention, try mode 2 after confirming nothing depends on consecutive IDs within a transaction.Measure the actual benefit. If switching to distributed IDs adds 2ms to every insert for network round-trips to an ID service but removes a 20ms lock wait, you’re ahead. If it adds 5ms and removes 3ms, you’re worse off. Measure before you migrate.
AUTO_INCREMENT is fine for most workloads. It’s the hidden lock in the corner for the few that outgrow it.
Found this useful? Subscribe to Podo Stack for weekly database patterns, Kubernetes internals, and Cloud Native tools ripe for production.