
HDFS Lost. How Object Storage and Table Formats Won the Data Lake
Why data locality is dead, why S3's rename problem didn't matter, and why Iceberg and Delta Lake turned a key-value store into an ACID database

Ten years ago, the conventional wisdom for building a data lake was carved in stone. Data is too big to move, so move the code to the data. Run your Spark jobs on the same machines where your HDFS blocks live. The whole architecture of Hadoop was built on this single principle - data locality - and for a while it was unquestionable.
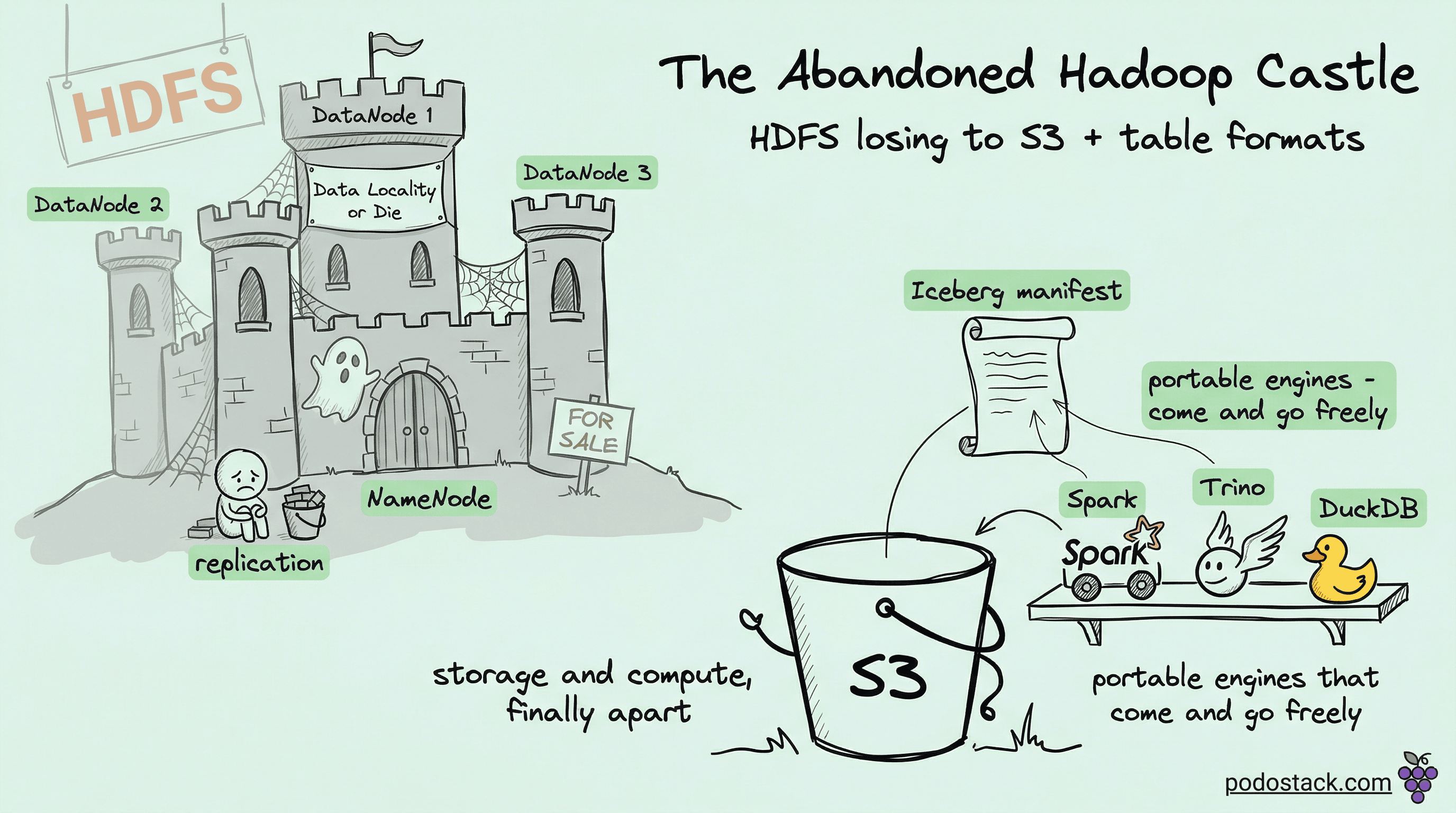
Today that principle is dead, and data engineering is happier for it. Somewhere between 2018 and 2022, the industry quietly abandoned HDFS for object storage plus ephemeral compute, and the world kept turning. If you joined the field in the last five years, you might have missed the memo that this was once controversial.
So what actually happened? Why did data locality lose? And why is S3, which was supposed to be terrible for analytics, now the default?
The collapse of data locality
When Hadoop was designed, data center networking was 1 Gbps and hard drives were spinning rust. Reading 100 MB from a local disk took about a second. Sending the same 100 MB across the network took eight seconds. Of course you moved the code to the data - the math didn’t leave any other option.
In a modern cloud, the math is completely different. EC2 instances routinely get 25 Gbps of network throughput, with some families hitting 100 Gbps. Meanwhile, a local SATA SSD maxes out at maybe 500 MB/s, and even NVMe tops out at a few GB/s per drive. Network bandwidth has caught up to disk bandwidth and in many cases surpassed it.
The moment network I/O is no longer the bottleneck, the whole reason for data locality disappears. You can read a Parquet file from S3 in the same time you’d read it from local disk. The bottleneck has moved elsewhere - to CPU, specifically to the cost of deserializing columnar data into your query engine’s memory format. “Move code to the data” became “move data to whatever compute is cheapest right now.”
The coupling problem
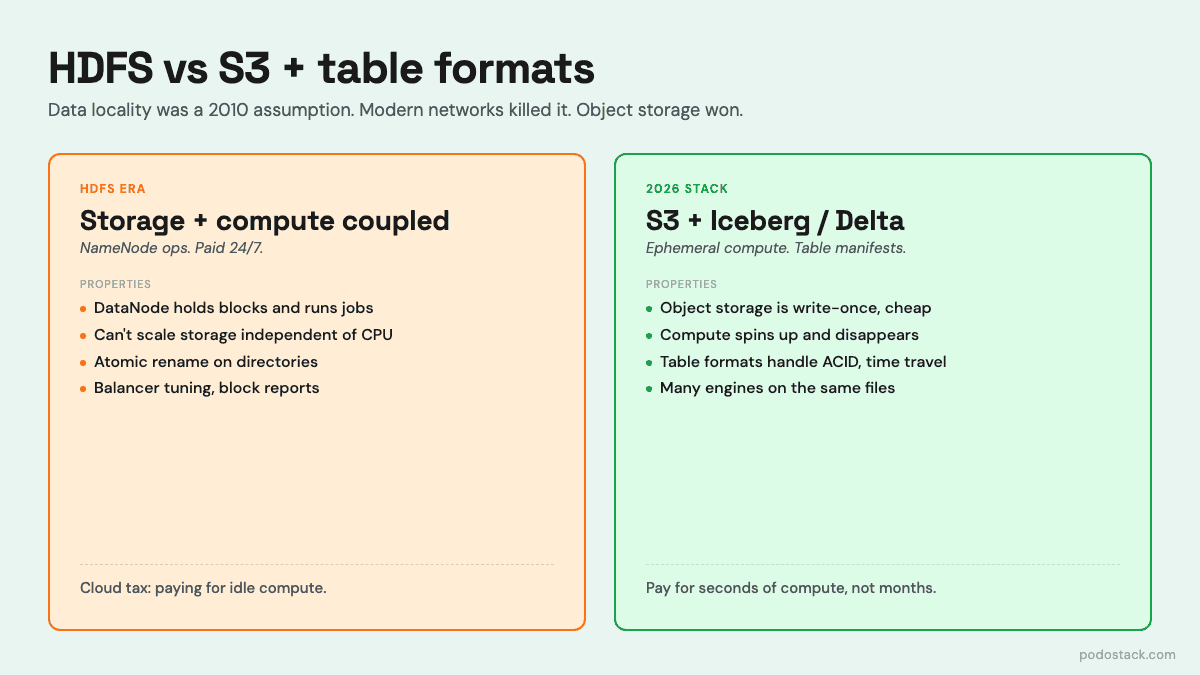
HDFS doesn’t just assume data locality - it bakes it into the architecture. Your DataNodes are both storage and compute. They hold the blocks and they run the YARN containers. You can’t scale them independently because they’re the same thing.
This creates a painful dilemma every time you want to resize your cluster. Running out of storage? You add nodes, each of which brings CPU and RAM you may not need. Running out of CPU? You add nodes, each of which brings disks you may not need. Your actual resource ratio almost never matches the fixed ratio that your instance type offers, so you’re always overpaying for one thing to get enough of the other.
And you pay 24/7. The nodes have to stay up because they store data. Even during the long stretches when nothing is running, you’re paying full price for compute that’s idle because the disks attached to it have your data.
The object storage model breaks this coupling completely. Your data lives in S3. Your compute lives on EC2 Spot or Kubernetes or a managed service. You scale them independently. You turn compute off when you don’t need it. Your nightly ETL runs on a cluster that exists for 40 minutes and then disappears. You’re paying for seconds of compute, not months of idle storage + compute bundles.
The rename problem and why it didn’t matter
There’s one technical reason people initially thought S3 would never work for serious data lakes. HDFS is a filesystem with a proper tree structure. Operations like rename are atomic metadata operations - rename a directory, flip a pointer, done. Spark’s output committers relied on this: jobs wrote to _temporary/attempt_X/, and on success, renamed the temp directory to the final location in one atomic step.
S3 is not a filesystem. It’s a flat key-value store pretending to have directories. There’s no “rename” operation. Moving an object means copying it to the new key and deleting the old one. Renaming a “directory” with 10,000 objects means copying 10,000 objects - and it’s not atomic, so a failure halfway through leaves you with a mess.
The industry’s first attempts to deal with this were hacks on top of hacks. S3A got “magic committers” that abused S3 multipart upload to simulate atomic commits. It worked but was fragile and required tuning.
The real fix came from somewhere unexpected: the metadata layer. Table formats - Iceberg, Delta Lake, Hudi - solved the rename problem by refusing to use directories as state. Instead of “the data for this table is whatever files are in this directory,” they maintain a manifest of which files belong to the current version of the table. Committing a new version means writing a new manifest and atomically swapping a pointer to it. The underlying object store doesn’t need directories, doesn’t need rename, doesn’t need anything clever. It just stores immutable files and serves them back.
This wasn’t just a workaround. It was an upgrade. Table formats gave you ACID transactions, schema evolution, time travel, hidden partitioning, and efficient deletes - none of which HDFS-based data lakes had.
What won
The stack that replaced HDFS looks like this: S3 (or equivalent) for cheap durable storage, a table format (Iceberg or Delta Lake) for ACID transactions and metadata, and ephemeral compute (Spark, Trino, DuckDB, Snowflake, whatever) that reads directly from S3. Each layer is independent. You can swap engines without touching data. You can run two engines against the same table. Your analyst uses Trino, your ML pipeline uses Spark, your dashboards use DuckDB - all pointing at the same files.
The operational savings are real. No NameNode to babysit. No block balancer to tune. No “we need a Hadoop admin” line in your job requisition. The cloud provider handles durability, replication, and scaling - you pay for what you store and what you read.
When HDFS still makes sense
There’s one case where HDFS is still the right answer: you already own the hardware. If you’ve got a rack full of servers in your own datacenter, each with local drives, you don’t benefit from decoupling storage and compute - you can’t turn the servers off to save money because you’ve already bought them. HDFS extracts the most value from that hardware because it uses both the disks and the CPUs at the same time.
For cloud-based data platforms, running HDFS on EC2 instances is an anti-pattern. You’re paying for compute you can’t turn off, you’re getting none of the benefits the on-prem model offers, and you’re fighting every managed service and ecosystem tool that assumes S3.
The wider lesson
Data locality was not a timeless principle. It was a consequence of a specific hardware ratio - slow networks, slow disks, local CPU - that stopped being true. When the ratio shifted, the architecture built on it stopped making sense, and the industry quietly moved on.
There’s probably a similar “timeless principle” in your stack right now that’s actually a snapshot of 2015’s hardware tradeoffs. Worth looking for.
Still running Hadoop on cloud VMs because that’s how you learned it? The math has changed. S3 + Iceberg + ephemeral compute is cheaper, faster to operate, and won’t wake you up to restart a NameNode.