
Iceberg vs Delta vs Hudi: the table-format war is over
Open table formats, metadata layers, snapshots, REST catalogs, interop

A team I talked to picked Hudi in 2022 and spent the early months of 2026 migrating off it. Not because Hudi broke. It ran fine for three years. They moved because every tool they wanted to bring in - a new query engine, a managed warehouse for the analysts, a catalog the security team would sign off on - assumed Iceberg, and they were tired of being the one workload that needed a special path. The migration wasn't a verdict on Hudi's engineering. It was the team noticing, a couple of years late, that the question they'd argued about in 2022 had quietly stopped being the question. Picking a table format used to feel like picking a database - a decision you'd live with for a decade. By 2026 it feels more like picking which of three nearly-identical things to write your data in, because the engines have learned to read all of them anyway.
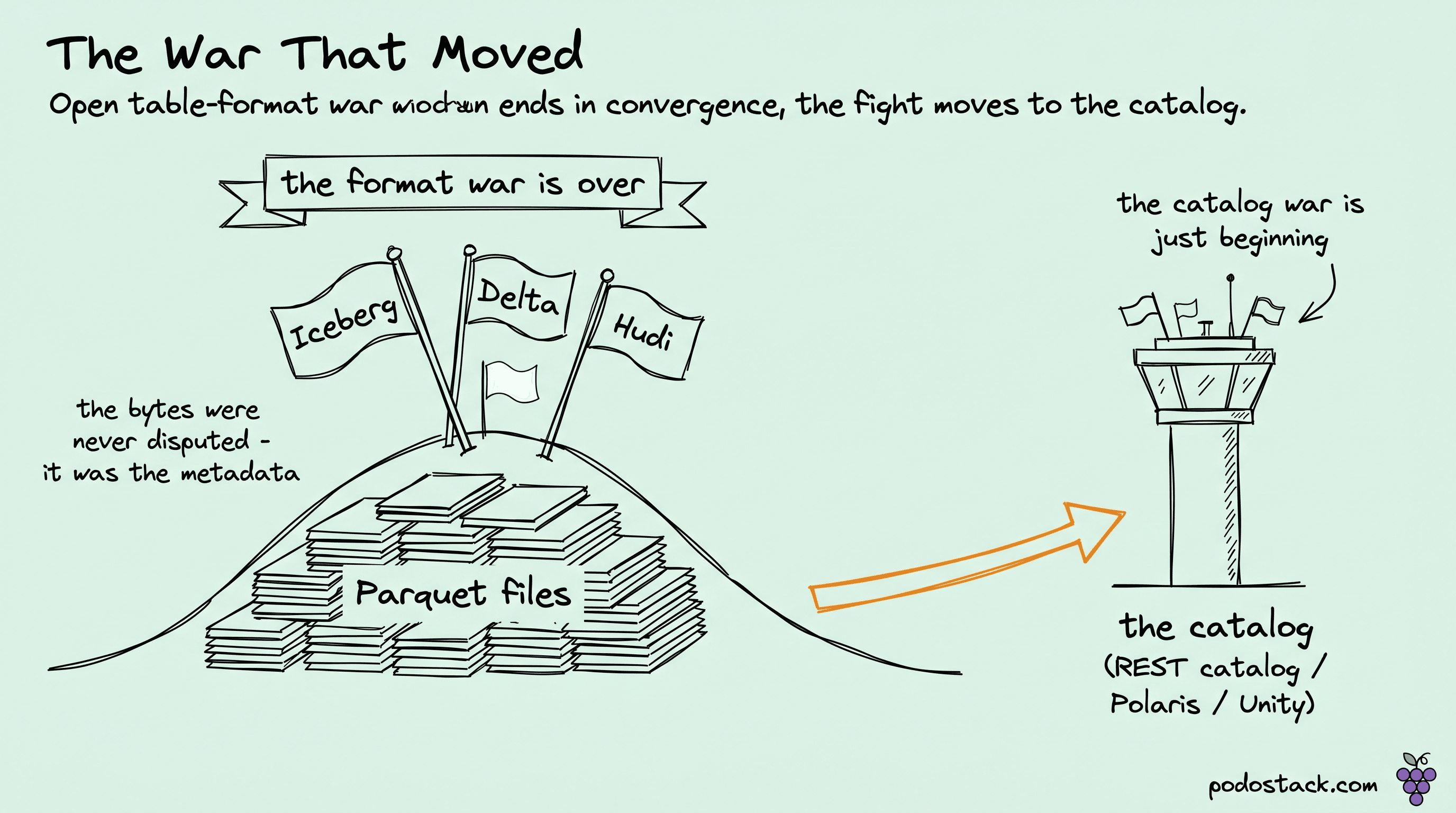
That's the short version of where we are: the format war is basically over, Iceberg won the mindshare, and almost nobody should care as much as they did. The longer version is more interesting, because the war didn't end with one format killing the others. It ended with convergence, and the real fight moved somewhere else.
What a table format even is
Strip away the branding and all three - Iceberg, Delta Lake, Hudi - solve the same problem. You have a pile of Parquet files in object storage. Object storage knows nothing about tables, transactions, or schemas; it knows about objects and prefixes. A table format is the metadata layer you bolt on top so that a directory of Parquet files behaves like a real table - one you can update, query consistently, evolve, and roll back.
The mechanics rhyme across all three. There's a set of data files (Parquet, usually) holding the actual rows. Above that sits a metadata layer that tracks which files belong to the table right now. In Iceberg's vocabulary that's manifest files listing data files plus their column-level stats, manifest lists grouping those manifests, and metadata files describing the table's current state. Every write produces a new snapshot - an immutable pointer to the exact set of data files that constituted the table at that moment. A commit is, at bottom, an atomic swap of "the current snapshot is now this one." Delta does the same thing with a transaction log (the _delta_log directory of ordered JSON commits); Hudi does it with timeline files and a slightly different file-grouping model tuned for upserts. Different nouns, same idea.
Once the snapshot model clicked for me, the headline features stopped looking like separate features and started looking like consequences of that one idea. ACID on object storage: a reader always sees a consistent snapshot because the snapshot is immutable and the commit is a single atomic pointer flip, so a reader either sees the old set of files or the new one, never a half-written mess. Time travel: old snapshots aren't deleted immediately, so "show me the table as of last Tuesday" is just reading an older pointer. Schema evolution: the metadata tracks column identity over time, so adding, renaming, or dropping a column is a metadata operation, not a rewrite of every file. None of this is magic. It's careful bookkeeping in a metadata layer that turns dumb object storage into something transactional.
How Iceberg pulled ahead
For a few years this was a genuine three-way contest with real religious wars attached. Delta Lake had Databricks behind it and the gravity that comes with being the default in the most popular Spark platform on earth. Hudi came out of Uber, built streaming-first, the one that took incremental upserts and change capture seriously when the others were batch-shaped. Iceberg came out of Netflix, designed by people who'd been burned by Hive's directory-listing model and wanted something that scaled to enormous tables without melting the metastore.
Iceberg pulled ahead on two things. One was technical: its design was the cleanest for very large tables and the most engine-neutral from the start - it never assumed Spark the way Delta effectively did. The other was political, and it mattered more. Iceberg's open governance under the Apache Foundation, plus a REST catalog spec that any engine could implement, made it the safe Switzerland choice for vendors who didn't want to hand Databricks the keys to their data layer. If you're Snowflake or AWS or Trino, adopting Delta means adopting Databricks' format; adopting Iceberg means adopting a neutral standard. That's not a hard call.
The decisive moment was Databricks buying Tabular in June 2024 for north of a billion dollars. Tabular was the company founded by Iceberg's original Netflix creators. Read that again: the company most identified with Delta Lake paid over a billion dollars to acquire the people who built the competing format. That is not what winning a format war looks like. That's the Delta camp acknowledging Iceberg's gravity and buying a seat at its table. Databricks' own framing was convergence - bring the Delta and Iceberg creators under one roof and work toward a single interoperable standard - and they were explicit that it'd take years, not months.
Convergence, not conquest
The thing that actually killed the war is that the formats stopped being mutually exclusive. Delta Lake UniForm is the clearest example. UniForm writes your data as Delta but also generates Iceberg (and Hudi) metadata pointing at the same underlying Parquet files, so an Iceberg reader can query a Delta table with no copy and no conversion. One set of data files, multiple metadata layers describing it, read it as whatever your engine speaks. The Parquet was never the disputed territory - it's the same columnar bytes regardless. The fight was always about the metadata layer on top, and once that layer became something you could project into multiple formats over shared files, "which format" stopped being a one-way door.
Iceberg's own evolution pushes the same direction. The format's newer spec revisions added the row-level delete and update machinery that used to be the reason you'd pick Hudi for mutation-heavy workloads, narrowing the gap that justified a separate streaming-first format. So you have Delta growing the ability to be read as Iceberg, and Iceberg growing the capabilities that were Hudi's whole pitch. The three formats are bleeding into each other on purpose.
The industry settled on a phrase for it: write once, read anywhere. Whether you can fully deliver that today depends on which features and which engine versions you're on - the interop is real but the edges are still rough, and "UniForm makes Delta readable as Iceberg" carries asterisks around exactly which Iceberg capabilities survive the projection. So treat write-once-read-anywhere as the clearly-stated direction of travel that's already mostly true for common cases, not as a finished guarantee for every feature.
Where Hudi sits now
Hudi isn't dead, whatever the migration stories suggest. It remains genuinely strong at what it was built for: high-frequency upserts, incremental pulls, streaming ingestion where records mutate constantly and you need merge-on-read and record-level indexes to keep write amplification sane. If your workload is a firehose of changing records rather than mostly-append analytics, Hudi's design still has real advantages, and there are large production deployments running on it happily.
But its center of gravity narrowed. It went from one of three contenders for the default open table format to a specialist tool you reach for when its particular streaming-upsert strengths matter more than ecosystem breadth. The honest read in 2026: greenfield projects mostly default to Iceberg, Hudi stays where the streaming-mutation profile justifies the smaller ecosystem, and a chunk of the teams that picked it in 2021-2022 are doing what that first team did - migrating, not because Hudi failed them but because being the odd format out has a tax that compounds.
The catalog is the new battleground
Here's the part that matters more than which format you write. Once everyone can read everyone's files, the format is commoditized, and the thing that isn't commoditized is the catalog - the service that knows which tables exist, where their current metadata lives, who's allowed to touch them, and how to atomically commit a new snapshot. The catalog is the control plane. It owns governance, access control, and the commit protocol. Whoever owns the catalog owns the actual lock-in.
Iceberg's REST catalog spec turned the catalog into a standard HTTP API: implement the spec and any engine that speaks it can talk to your catalog. That spec is now the contested ground, and the contestants are exactly who you'd expect. Snowflake built Polaris, an open-source Iceberg catalog, and donated it to the Apache Foundation in 2024 (partnering with Dremio, AWS, Google and Microsoft on the donation); Snowflake's managed version of it ships as Snowflake Open Catalog, GA since October 2024. Databricks open-sourced Unity Catalog and took the multi-format route - Unity aims to catalog Delta, Iceberg, Hudi, and unstructured files alike, rather than betting on Iceberg alone. AWS shipped S3 Tables, object storage with Iceberg and a catalog baked directly into the bucket. Every cloud and every warehouse now has a horse in the catalog race, and they all speak the Iceberg REST dialect to some degree.
That's the shape of the next few years. The format question is settled enough that vendors give the format away for free, because the format is no longer where the money or the lock-in lives. The catalog is. Format war over, catalog war beginning - and the catalog war is the one to actually pay attention to, because the catalog is where governance, security, and switching costs concentrate.
How I'd actually choose in 2026
The first thing I tell anyone agonizing over this is that the decision carries far less weight than it did three years ago. With that said, here's roughly how I reason through it:
On greenfield with no overwhelming reason otherwise, I pick Iceberg. It's the de facto open standard, it has the broadest engine and vendor support, and choosing it means you're the normal case every tool plans for instead of the special case. The ecosystem tax runs in your favor.
If a team is already deep in the Databricks world, Delta is fine and UniForm is the bridge. There's no need to rip out Delta to interoperate - write it with UniForm enabled and Iceberg readers can query it. The convergence work exists precisely so this isn't a forced migration.
Heavy streaming upserts and mutation-dominated ingestion are where Hudi still earns its place. If merge-on-read and record-level indexing on a constant stream of changing records is your actual workload, its design advantages are real. Just go in clear-eyed that you're choosing the narrower ecosystem.
Whatever the format, the catalog is where I'd spend the real attention. Which one you adopt - Polaris/Open Catalog, Unity, a cloud-native one like S3 Tables, or a self-hosted REST catalog - determines your governance model, your access-control story, and how locked-in you are. The format increasingly takes care of itself through interop.
And I'd demand REST-catalog compatibility from anything I adopt. The Iceberg REST spec is the interop seam. A tool that speaks it slots into a multi-engine world; one that insists on its own proprietary catalog protocol is the thing that traps you. That's the lock-in axis that's still live, so guard it.
The ones I keep seeing
Re-litigating the format war like it's still 2022 is the one I run into most. Teams burn weeks in format-selection meetings as if the choice is load-bearing, when for most analytics workloads it stopped being load-bearing once interop landed. Default to Iceberg and move on to problems that still matter.
Then there's confusing the format with the catalog. "We use Iceberg" tells me your file metadata layout and nothing about who governs your tables or how locked in you are. Those questions live in the catalog, and conflating the two means skipping the decision that actually has consequences.
Assume "write once, read anywhere" is already a clean guarantee everywhere and you'll get bitten on the edges. The interop is real and improving fast, but UniForm projections and cross-format reads carry feature and version asterisks. Verify the specific capabilities you depend on survive the round trip before you architect as if they do.
Picking Hudi for batch analytics because it was once a contender is a recurring waste. Its strengths are streaming and upserts; on mostly-append analytics you're choosing the narrowest ecosystem for none of the benefit. Match the format to the actual write pattern.
Letting a vendor's proprietary catalog become your lock-in by default is the trap that's quietly replaced the old one. The format being open doesn't help if the catalog protocol is closed, and the catalog is where switching cost concentrates now.
Last, treating an open-source catalog and its managed cloud version as identical. Polaris the Apache project and Snowflake Open Catalog the managed service are related but not the same surface; Unity Catalog open-source and the Databricks-hosted Unity are likewise distinct. Know which one you're actually running and what its governance story is.
The whole arc here is a commodity forming in real time. Five years ago the table format was a strategic, near-irreversible bet, and three vendors fought over it like it was the whole game. Then everyone realized the Parquet underneath was never in dispute, the metadata layer could be projected into multiple formats over the same files, and the engines could just learn to read all of them. So the format stopped being the moat. What's left as a moat is the catalog - the control plane that decides what exists, who can touch it, and how a write becomes official. If you take one thing from all of this, let it be where you point your scrutiny: not at which format to write, which is nearly settled, but at which catalog to trust, which is wide open and decides how free you'll be to change your mind later.