
Invisible Indexes: The Safest Way to Delete an Index You're Not Sure About
MySQL 8.0's hidden indexes let you A/B test index removal in production without DDL risk

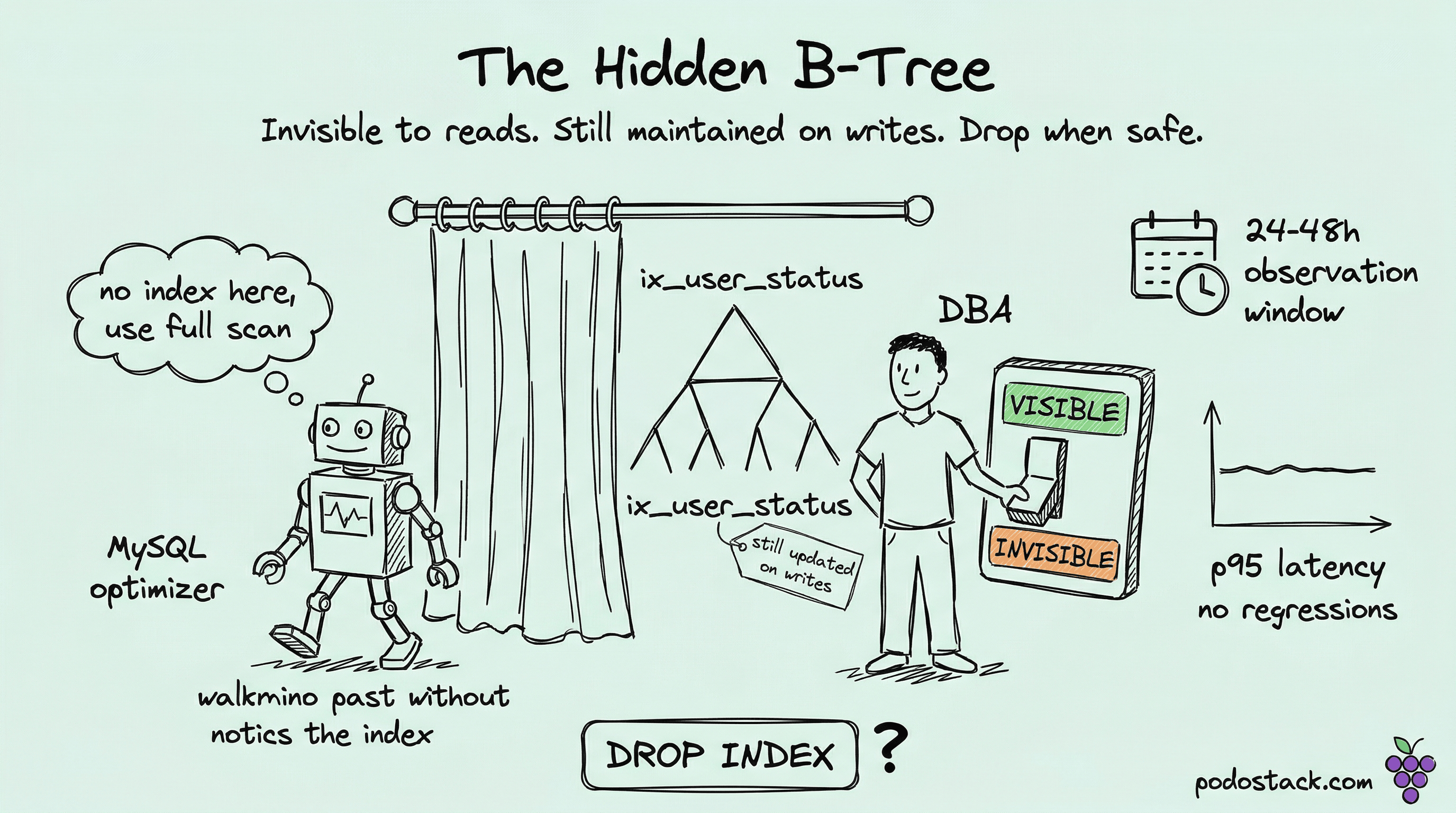
Here’s the classic production database problem. You find an index that looks useless. ix_orders_user_status - nobody in the team remembers adding it. It’s 4 GB. The query that supposedly uses it runs once a day for a report nobody reads anymore.
But you don’t want to drop it. Because the one time in two years that someone runs that report, dropping the index will turn a 200ms query into a 40-minute full scan, and you’ll hear about it from the CFO.
MySQL 8.0 has a feature for this exact problem. It’s called an invisible index, and it solves the “maybe I should drop this” problem without the risk. You hide the index from the optimizer while keeping it physically on disk. If nothing breaks for a few days, you drop it. If something breaks, you flip it visible again in one ALTER TABLE.
What “invisible” actually means
An invisible index is a normal B-tree index that the optimizer pretends doesn’t exist. Every INSERT, UPDATE, and DELETE still maintains it - the writes still hit the index pages. Every query plan is generated as if the index weren’t there.
ALTER TABLE orders ALTER INDEX ix_user_status INVISIBLE;That’s it. One statement. No data movement, no rewriting, no table rebuild. The index goes from “visible to the optimizer” to “invisible to the optimizer” instantly.
And if you need it back:
ALTER TABLE orders ALTER INDEX ix_user_status VISIBLE;Also instant. The index was never physically gone - it was just hidden. You flip the bit, the optimizer can see it again, query plans using it start working immediately.
The three things this is perfect for
Auditing unused indexes. Over years of schema evolution, dead indexes accumulate. Some are duplicates (two indexes with the same leading columns in different order). Some were added “just in case” by someone who left. Dropping them feels risky because you can’t be sure nothing depends on them. Mark them invisible for a week, watch for regressions, then drop the ones that caused zero complaints.
Forcing the optimizer to try a different plan. Sometimes the optimizer stubbornly picks a bad index. You suspect another index would be better, but you can’t remove the “bad” one because other queries need it. Make it invisible temporarily. The optimizer is forced to pick a different plan. If the new plan is better across the board, congratulations - you have evidence for a refactor. If it’s worse, flip it back.
Rolling out a new index carefully. Create the new index as invisible. It gets maintained on all writes but doesn’t affect any query plans. Run your performance tests on a replica with real traffic. If the metrics look good, flip it visible on production. If not, drop it without ever having risked a plan regression.
The workflow
The whole process looks like this:
-- 1. Pick a candidate via SHOW INDEX and slow query log
SHOW INDEX FROM orders WHERE Key_name = 'ix_user_status';
-- 2. Make it invisible (instant)
ALTER TABLE orders ALTER INDEX ix_user_status INVISIBLE;
-- 3. Wait 24-48 hours. Watch your metrics:
-- - p95 and p99 latency per endpoint
-- - handler reads per second
-- - slow query log entries
-- - any alerts from your APM
-- 4a. If everything is fine, drop it
ALTER TABLE orders DROP INDEX ix_user_status;
-- 4b. If something is worse, flip it back
ALTER TABLE orders ALTER INDEX ix_user_status VISIBLE;The reason this is so much better than the straight DROP INDEX approach is reversibility. DROP INDEX on a large table is not free. The rollback is CREATE INDEX, which takes minutes or hours and might lock the table depending on your MySQL version and storage engine settings. Invisible-then-drop gives you a cheap, instant rollback during the observation window, and only after you’re confident do you pay the DDL cost of actually dropping it.

The catches
Primary keys and unique indexes can’t be made invisible. They participate in constraint enforcement, not just query optimization, so MySQL refuses. You’ll get an error if you try.
Writes still hit the index. This is the big one. The index is invisible to reads but alive for writes. If your goal is to reduce write amplification on a heavy OLTP table, making the index invisible does not help. You have to actually drop it to see the write savings. Invisible is for testing the read path, not the write path.
The query hint escape hatch. If you’re desperate to test a query with the invisible index anyway, you can force it with SET SESSION optimizer_switch='use_invisible_indexes=on';. This makes invisible indexes visible for your session only. Useful for debugging “would this index help if I re-enabled it?” without affecting production traffic.
Replica considerations. Make sure you understand how your replication topology handles DDL. On a typical MySQL replication setup, the ALTER TABLE ... INVISIBLE propagates through the binary log like any other DDL. If you run multi-source or group replication, verify the behavior matches your expectations before you rely on it.
Why it matters
Before MySQL 8.0, index management was a one-way door. You either kept the index (paying its storage cost and write overhead) or dropped it (risking a plan regression you wouldn’t notice until it was too late to easily recover). Invisible indexes turn that binary decision into a reversible experiment.
The same DBA pattern works in both directions - testing removals and testing additions. Combined with a proper slow query log and per-query metrics, you can run real A/B experiments on your index set without ever risking production stability.
If you’re running MySQL 8.0 and you’ve never used this feature, the next time someone asks “can we drop this index?” the answer should be “let’s make it invisible first.”
Still dropping indexes and hoping for the best? Flip them invisible first - it’s one ALTER TABLE and it buys you a real rollback window.