
Issue #024 - eBPF reads your TLS traffic without the private key
SSL_read uprobes, Go crypto/tls offsets, Pixie vs Beyla vs eCapture, kTLS, the threat model

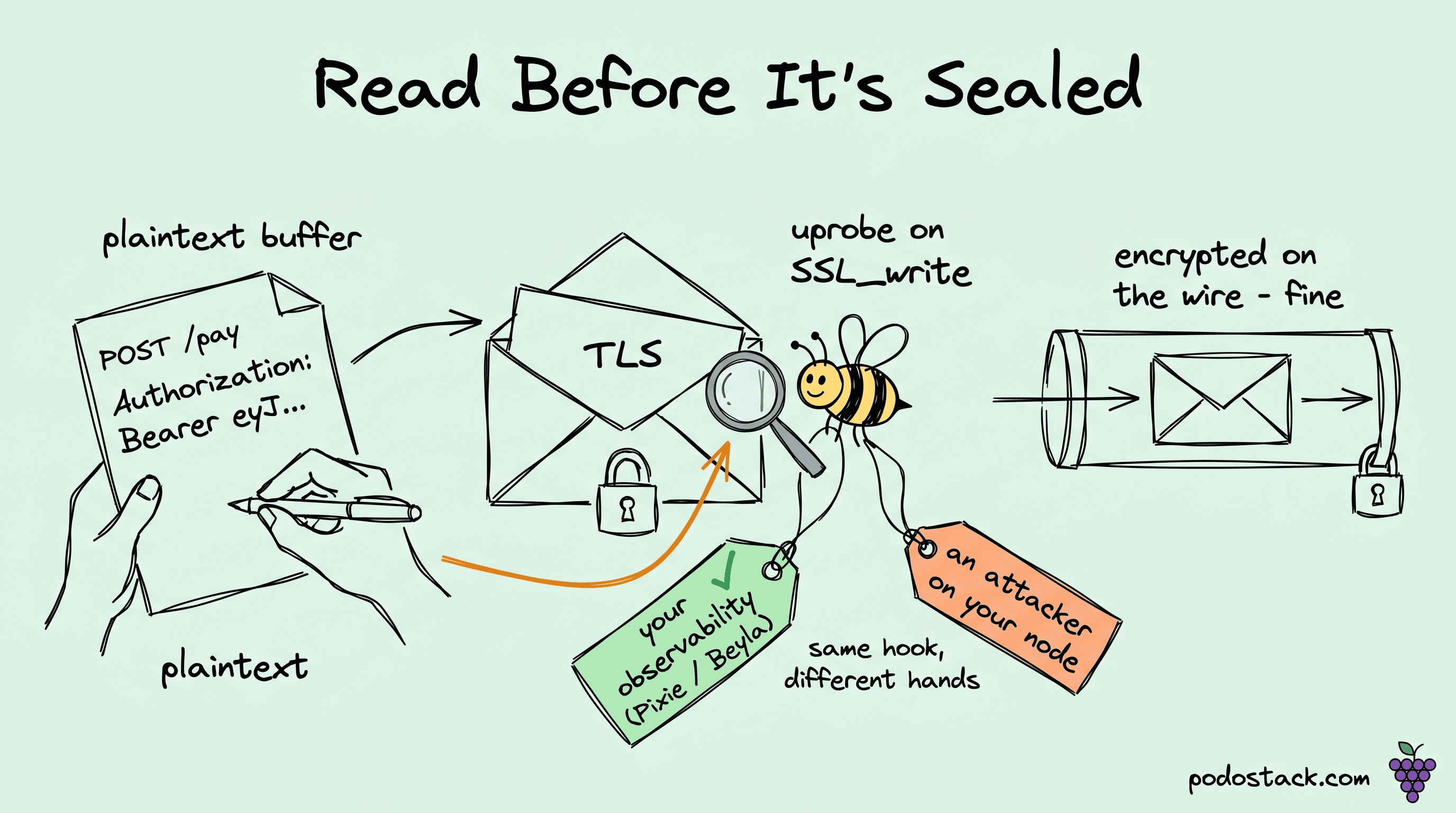
I was sitting in a Pixie session, scoped to one of our own namespaces, expecting the usual latency histograms and the boring shape of a healthy service. Then I clicked into a single request and the body was right there. The full JSON payload our payments service had POSTed to an internal API, headers and bearer token included, rendered as plaintext in a browser tab. The service talks TLS to everything. The mesh enforces mTLS. I had not handed Pixie a key, a cert, or a secret of any kind. It had been running for about four minutes.
The jolt wasn't "is this a bug." I knew roughly how it worked. The jolt was the gap between knowing it in the abstract and watching my own service's secrets scroll by in a tool I'd installed myself that afternoon. "Encrypted in transit" had quietly stopped meaning what I'd been letting it mean in my head, and it took seeing the payload to notice I'd been rounding it off.
This is about a technique that's load-bearing under half the observability stack you might be running, and is also, looked at from a slightly different angle, a clean way for someone with a foothold on your node to read everything your "encrypted" services say. Same mechanism. The only thing that changes is who's holding it.
🔬 The eBPF Trace: a uprobe on SSL_read sees plaintext before the key touches it
For a long time I carried the same wrong picture of TLS observability that most people do. To read encrypted traffic you need a key - the session key, or the server's private key - or failing that you stand up a MITM proxy with a cert the client trusts. All of that is true if you're attacking the bytes on the wire. None of it is what these tools do.
The trick is to not touch the wire at all. Your application calls SSL_write with a pointer to a buffer. That buffer holds plaintext. OpenSSL takes it, encrypts it, and only then hands ciphertext to the kernel's send(). The encryption happens inside the library call, after your plaintext is already sitting in addressable memory. So if you can read that memory at the moment the function is entered, you get the plaintext, and you never have to know a single thing about the key the library is about to use. The same logic runs in reverse for reads: SSL_read returns decrypted plaintext into a caller-supplied buffer, so you wait for the function to return and read the buffer then.
eBPF gives you exactly that hook. A uprobe is a kernel-managed breakpoint on a userspace function. You attach one to SSL_write in libssl.so, and every time any process linked against that library calls it, your tiny eBPF program runs first, with the function's arguments in registers.
The two-probe dance
There's a wrinkle that's worth slowing down on, because it explains the shape of every tool that does this. For a write, the plaintext buffer is an argument - it exists when the function is entered. For a read, the plaintext doesn't exist yet on entry; the buffer is empty and the byte count isn't known until the library has decrypted and returned. So you can't capture a read with a single probe.
What the tools do is split it across an entry probe and a return probe. On SSL_read entry, the eBPF program stashes the buffer pointer in a BPF hash map, keyed by bpf_get_current_pid_tgid() - the 64-bit value that packs the process and thread ID. On SSL_read return, a second probe pulls that pointer back out of the map, reads the function's return value to learn how many bytes actually landed, and only then copies the buffer out. The pid_tgid key is what keeps two threads calling SSL_read at the same time from stealing each other's buffers. The copy itself is a bpf_probe_read_user() into a perf buffer or ring buffer, which is the channel the userspace agent drains asynchronously. None of this is exotic; it's the standard entry-map-return pattern you'd use for any function whose output you want.
People worry this is expensive, and the surprise is how cheap it is. The probe runs in-kernel, off the application's critical path - the app calls SSL_write and returns exactly as it always did; the eBPF program runs alongside. Numbers I've seen quoted put the constant per-event eBPF cost around 0.2 microseconds, with the write-side uprobe landing near 0.007% CPU and the read-side return probe closer to 0.3% on a busy process. I haven't benchmarked those figures myself, so treat them as the right order of magnitude rather than gospel, but they match the lived experience: I ran Pixie across a fleet for weeks and never saw it move a latency graph. The cost isn't CPU. The cost is the capability you handed out to get it, which is the whole second half of this issue.
A stripped-down version of the write side, in bpftrace pseudocode, reads about like this:
uprobe:/usr/lib/x86_64-linux-gnu/libssl.so.3:SSL_write {
// arg0 = SSL*, arg1 = buf, arg2 = num
printf("pid %d wrote %d bytes:\n%r\n", pid, arg2, buf(arg1, arg2));
}That's the whole idea in four lines: hook the function, the buffer is arg1, the length is arg2, print it. A real tool adds the read-side return probe, the per-thread map, connection correlation, and protocol parsing on top. But the part that reads your plaintext is genuinely that small.
Stitching it back to a connection
The first time I looked at raw uprobe output it was a blob of JSON with no idea which socket it went out on, which isn't observability yet. The connection metadata - source, destination, which HTTP request this was - lives in the syscall layer, not in SSL_write. So the better tools also probe the send/recv syscalls and correlate. Pixie's design leans on a neat property here: when SSL_write is on the call stack, the underlying send() is usually right below it on the same stack, so the uprobe can reach down and grab the socket file descriptor that the plaintext is about to flow through. That's how the plaintext gets matched to a real five-tuple without the agent ever parsing a TLS record.
Where the buffer stops being readable
The technique has a hard floor, and it's worth knowing because it's the one thing that makes "just use eBPF" not universally true. If the application uses kernel TLS (kTLS), the encryption moves out of the userspace library and into the kernel's record layer. The library hands plaintext to the kernel and the kernel encrypts it. A uprobe on SSL_write may still see the plaintext on the way in, but tooling that hooks lower, expecting userspace encryption, goes blind - it sees ciphertext or nothing useful. kTLS is still uncommon in typical app stacks, but it's the clean architectural answer to this whole class of introspection, and it's why the technique is a property of how your app does TLS, not a law of physics.
Links
🆚 Showdown: Pixie vs Beyla vs eCapture, and what Go does to all three
Once you know the mechanism, the tools sort themselves by two questions: what do they do with the plaintext once they have it, and how hard do they work to handle the cases where libssl.so isn't sitting there waiting to be probed. The second question is mostly a single word: Go.
OpenSSL, the path nobody trips on
For a process dynamically linked against OpenSSL, all three tools do roughly what the last section described. You point them at libssl.so, they find SSL_read and SSL_write as dynamic symbols, attach the entry and return probes, and the plaintext flows. GnuTLS and NSS work the same way with different function names (gnutls_record_send, PR_Write). This is the well-trodden path and it's been production-stable for years.
The thing that breaks it isn't the library, it's the linking. Statically linked OpenSSL has no libssl.so to attach to - the symbols are buried inside the application binary, and if it's been stripped, they may not be there to find by name at all. BoringSSL, which is what Envoy and a lot of Google-lineage software use, is almost always statically linked, so the same problem shows up there. The tool has to locate the function inside the host binary by symbol or by offset rather than by opening a shared object.
Go breaks the model on purpose
Go is the interesting case, and it's where the tools genuinely diverge. Go doesn't link OpenSSL. It ships its own TLS stack in the crypto/tls package and statically links it into every binary, because static linking is the whole Go distribution story. So there is no libssl.so anywhere. To read a Go service's TLS plaintext you have to probe crypto/tls.(*Conn).Read and crypto/tls.(*Conn).Write directly inside the application binary, located by symbol offset.
Then it gets worse, in two specific ways. First, since Go 1.17 the compiler passes function arguments in registers (the internal ABI), not on the stack the way the old convention did - so the eBPF program has to know which ABI the binary was built with to find the buffer pointer in the right place. Second, and this is the sharp one: a normal uretprobe is unreliable on Go. Go's runtime moves goroutine stacks around as they grow, and the kernel's return-probe trampoline doesn't survive that. The workaround the tools converge on is to disassemble the target function, find every RET instruction, and attach a plain uprobe at each of those offsets - manually reconstructing the return probe the kernel can't safely give you. It works, but it's per-binary, offset-sensitive, and a category of fragile that the OpenSSL path just doesn't have. The practical fallout: a Go service that recompiles with a new toolchain can shift those offsets, and a tool that cached them silently starts capturing garbage until it re-resolves. I lost an afternoon once to exactly that shape - a Go upgrade landed, the traces for that one service went empty, and nothing in the agent's logs said "your offsets are stale" because from its side nothing had failed. The probe was attached. It was just attached to the wrong place in a binary that had moved underneath it.
Where each tool lands
The one I had open in the intro was Pixie, which sits at the full-platform end. It traces both OpenSSL and Go's crypto/tls, feeds the captured plaintext through the same protocol parsers and perf buffers it uses for cleartext traffic, and hands back the L7 service map, latency, and request bodies in a UI. Now under CNCF, New Relic-backed. The plaintext capture is a feature you mostly don't think about; it just shows you the requests.
Grafana's Beyla I'd put a tier toward the metrics side. It got donated to OpenTelemetry in May 2025 and became the basis for OpenTelemetry eBPF Instrumentation (OBI). The framing is zero-code auto-instrumentation: it taps libssl to pull HTTP-level information out of SSL traffic, and you get OTel metrics and traces out the other end without touching the app. Beyla leans hard on the Go case, because Go is where "I can't add an SDK easily" hurts most. One wrinkle I keep having to remind people of: to propagate trace context across encrypted HTTP it wants to be present on both ends and reaches for Linux Traffic Control at the packet level, which is a different mechanism bolted on top of the uprobe capture.
Then there's eCapture, which drops the observability pretense and just hands you the bytes. A CLI, around 15k GitHub stars, supporting OpenSSL, GnuTLS, NSS, BoringSSL, and Go. Its three modes tell you exactly what it's for: text mode prints plaintext to your terminal, pcap mode writes a Wireshark-openable capture of the decrypted traffic, and keylog mode dumps the TLS master secrets so you can decrypt a capture after the fact. No agent, no UI, no metrics pipeline. Point it at a process, read its TLS. Root or CAP_BPF, kernel 4.18+ on x86_64, and you're done.
One name I keep having to pull out of this list is Cilium. Its TLS visibility looks like it belongs here and it doesn't - it terminates the connection at Envoy with a cert your workload trusts, inspects, and re-originates. That's classic key-based MITM, not uprobe-on-plaintext. Different threat model, different requirements, different failure modes. If someone tells you "Cilium reads TLS the same way Pixie does," they're wrong about both.
Links
🔥 Hot Take: encrypted in transit is a promise about the wire, not the node
Here's the part I sat with longest after the Pixie session. The capability that gives my observability stack its L7 view is, byte for byte, the capability an attacker uses to read my "encrypted" traffic. There is no second technique. eCapture in text mode and Pixie's request inspector are the same uprobe on the same SSL_write, pointed at the same buffer. One of them ships me a flame graph and one of them ships me your bearer tokens, and the only difference is intent and who ran it.
That collapses a mental model a lot of us carry without examining it. "TLS everywhere," "mTLS in the mesh," "encrypted in transit" - we say these like they're a guarantee of confidentiality. They're not. They're a guarantee about the wire. They protect the bytes once they leave the process and right up until they enter the next one. Inside the process, before SSL_write encrypts and after SSL_read decrypts, the data is plaintext in memory, and anyone who can run an eBPF program in that pid namespace can read it without breaking a single cryptographic primitive. The crypto is fine. The crypto was never the question. The question is who has code execution next to your process.
So the honest version of the security boundary is narrower than the marketing. To pull this off, an attacker needs CAP_BPF (or CAP_SYS_ADMIN on older kernels) and reach into the target's pid namespace - which in practice means a privileged container, a node compromise, a hostPID: true pod, a debug sidecar nobody locked down, or a DaemonSet with more capability than it needed. That's a real bar. It is not the bar most people picture when they picture "the traffic is encrypted." The traffic being encrypted does nothing against an adversary who already stands where your observability agent stands. And here's the uncomfortable symmetry: if you've deployed Pixie or Beyla or any eBPF L7 tool as a DaemonSet, you have already granted exactly that capability, to that agent, on every node. You decided this was fine. You were probably right. But you decided it, and the decision was "a privileged process may read every service's plaintext," which is a larger decision than "let's get better traces."
The reframe I landed on is to stop treating transit encryption and node trust as one property. They're two. TLS handles the first and handles it well. The second - who is allowed to execute privileged code beside your workloads - is a separate control plane: capability hygiene, CAP_BPF as a guarded grant, locking down hostPID and privileged pods, watching what your DaemonSets actually run. In the postmortems I've read, the teams that got burned weren't running broken TLS at all. They'd let "encrypted in transit" quietly stand in for "confidential on the box," and then handed broad eBPF capability to three different agents because each one's install doc made it sound routine. The wire was never the soft part. The node was.
Until next week
What stuck with me from the Pixie session wasn't the technical surprise. It was realizing how much weight I'd been putting on a phrase - "it's encrypted" - that was only ever true about one segment of the path. The bytes were safe in flight and fully exposed at rest in memory, and I'd been mentally filing both under the same word.
Next Tuesday, the thing this keeps circling back to: who holds the secret. Specifically, the four wrong ways to put secrets in Git, and how SOPS, Sealed Secrets, External Secrets, and Vault each draw the line between "in the repo" and "in the cluster" differently. If this issue made you slightly paranoid about what's readable on your nodes, that one is the natural next paranoid afternoon. See you then.
- Ilia