
kube-apiserver watch cache: the layer that saves etcd
LIST-WATCH, resourceVersion, bookmarks, relist storms, consistent reads

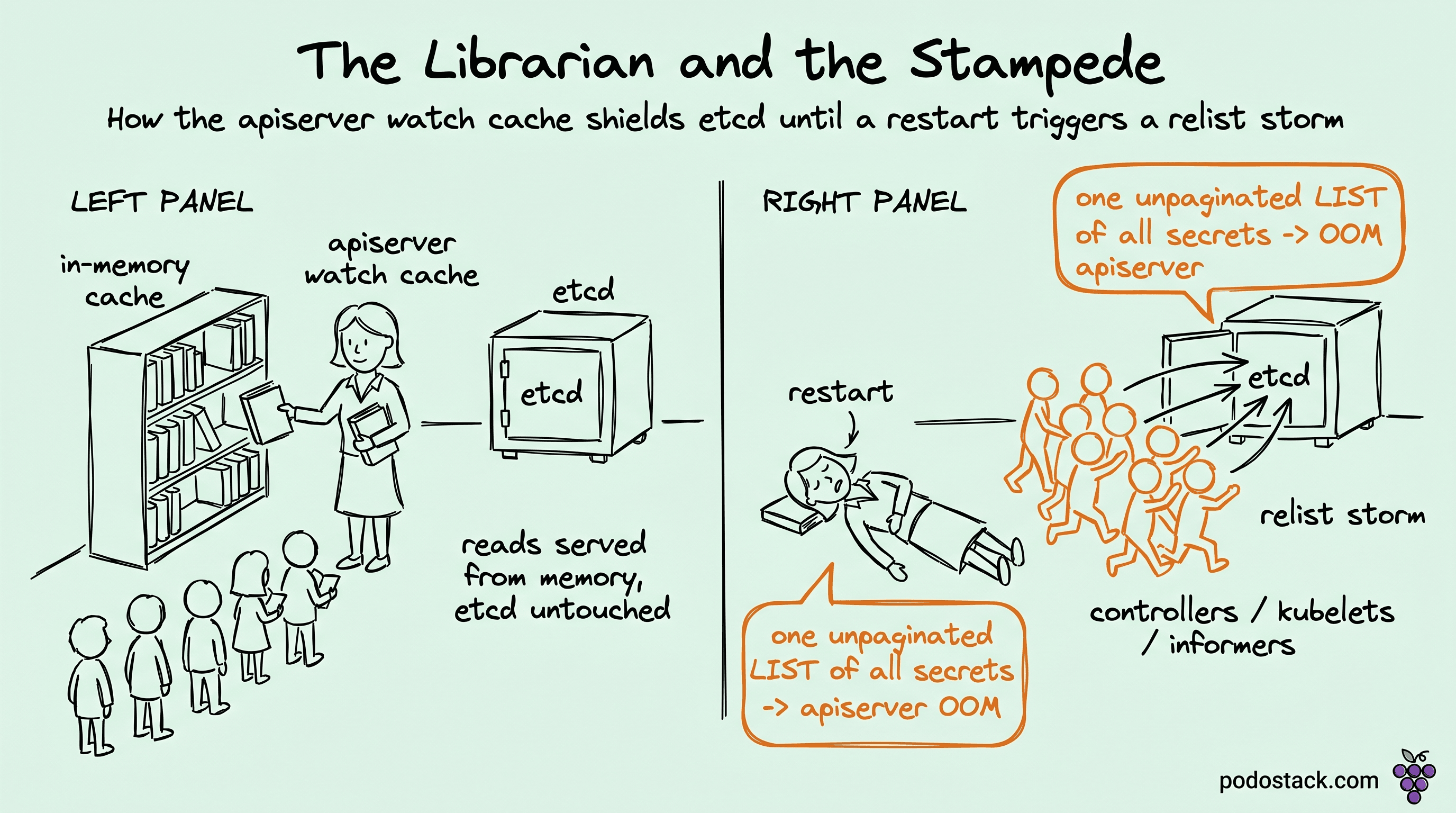
The page that night was apiserver OOMKilled, then OOMKilled again forty seconds after the kubelet brought it back. Three replicas, all dying in a rolling wave. The cluster was big - thousands of namespaces, north of two hundred thousand secrets - and somebody had shipped a controller that, on every reconcile, did a plain client.List of all secrets across all namespaces with no pagination and no informer. One pod restart kicked off a reconcile, the reconcile pulled the entire secret set into apiserver memory at once, the apiserver fell over, every other controller noticed the connection drop and relisted, and now you've got a thundering herd hammering the one component everything depends on. We spent the first twenty minutes assuming etcd was the problem. It wasn't. etcd was bored. The apiserver was the thing eating itself, and the watch cache is the layer that's supposed to stop exactly this.
What a LIST actually costs
People talk about "the Kubernetes API" like it's a database you query. It's closer to a cache in front of a database, and the database is etcd. Every object - every Pod, Secret, ConfigMap, CRD instance - is a key-value pair in etcd, serialized as protobuf. When you ask the apiserver for something, the interesting question is whether it answers from etcd or from its own memory.
A naive LIST straight against etcd is brutal in a way that isn't obvious from the one-line client call. First, it's a quorum read: etcd is a Raft cluster, and a linearizable read has to confirm with a majority of members that the leader hasn't been superseded before it hands back data. That's a network round trip across the etcd peers before a single byte comes back. Then comes the part that actually hurt us - the apiserver pulls every matching key out of etcd, deserializes each one from protobuf into a Go object, holds the whole set in memory, re-serializes it into whatever the client asked for (JSON, usually, which is bigger and slower), and ships it. List a hundred thousand secrets and the apiserver is briefly holding a hundred thousand decoded objects in the heap. Do that from three controllers at once and you've got the heap graph we were staring at.
So most reads don't go to etcd at all. They go to the watch cache.
The cacher
Inside the apiserver, each resource type gets its own cache, an internal component called the Cacher. There's a Cacher for Pods, one for Secrets, one for every CRD. Each one opens a single long-lived WATCH against etcd for its slice of the keyspace and just... keeps up. etcd streams every create, update, and delete as it happens, and the Cacher applies those events to an in-memory copy of the current state. It's a tail of the etcd write log, materialized into a live picture of "what exists right now."
That's the trick. When ten thousand informers across the cluster all want to know about Pods, they don't each open ten thousand watches against etcd. They watch the apiserver, the apiserver watches etcd once, and the one upstream watch fans out to everyone downstream. etcd sees a handful of connections instead of tens of thousands. The cache absorbs the multiplexing.
A LIST served from the cache skips the quorum read and the per-object etcd fetch entirely. The objects are already decoded and sitting in memory. The cache filters them by namespace and label selector, serializes the result, done. That's why kubectl get pods feels instant on a cluster where a direct etcd LIST would take a real chunk of a second.
What resourceVersion actually is
Every object in Kubernetes carries a resourceVersion, and I've misread it myself more than once. It is not a per-object version counter. It's an opaque token derived from etcd's global revision - a monotonically increasing number that ticks on every write to the entire keyspace. Edit one ConfigMap and its resourceVersion jumps to whatever etcd's global revision happens to be at that instant, which might be a number thousands higher than its previous value because thousands of unrelated writes happened in between. Treat it as a logical clock for the whole store, not a version of the thing you're holding.
This matters because resourceVersion is how the watch cache reasons about freshness. When a client LISTs and gets back a result at resourceVersion 8000, then opens a WATCH "since 8000," the apiserver knows precisely where to resume - replay every event after revision 8000. No gaps, no duplicates. When you pass resourceVersion=0 on a LIST, you're telling the apiserver "I don't care about being current, give me whatever the cache has, even if it's slightly stale." That's the cheap path informers use on startup, and it's the right default for them. When you omit resourceVersion entirely, you're asking for a strongly consistent read, and historically that meant a quorum read against etcd. Hold that thought.
The failure mode hiding in here is 410 Gone. The cache only holds a sliding window of recent history. If a watch tries to resume from a resourceVersion that's already fallen off the back of that window - because the watcher was disconnected too long, or etcd compacted that revision away - the apiserver can't replay the missing events and returns 410 Gone. The client's only correct response is to throw away its cached state and LIST again from scratch. Which is fine for one client. It is not fine when a network blip disconnects every watcher in the cluster at once and they all relist together.
Bookmarks, and why your watch goes quiet
Here's a subtle one. Suppose your controller watches Pods, but it filters to a label selector that matches almost nothing - one Pod in a busy cluster where thousands of other Pods churn every minute. Your watch sits silent for an hour because none of your one Pod's events fired. Meanwhile etcd's global revision has climbed by tens of thousands. Your client still thinks it's at the revision from an hour ago. When it eventually has to reconnect, that revision is long gone, you get a 410, and you relist.
Watch bookmarks fix this. The apiserver periodically sends a near-empty event - no object payload, just a bumped resourceVersion - down every watch stream, including the quiet ones. It's the server saying "nothing you care about changed, but you're now caught up to revision 47000, write that down." The client advances its resourceVersion without doing any work, so when it reconnects it asks to resume from a revision the cache still has. Bookmarks turned 410 storms from a regular annoyance into a rare event. They've been on by default for years now, and if you're writing a controller against client-go you get them for free.
The relist storm
Back to the incident. The thing that turned one bad controller into a cluster-wide outage was the relist. When the apiserver died, every informer's watch connection dropped. client-go's reflector, on a broken watch, does the only safe thing: it relists. So at the moment all three apiservers were already starved for memory, every controller, every kubelet, every operator in the cluster simultaneously fired a LIST to repopulate its informer. The survivors got buried. This is the apiserver equivalent of a cache stampede, and it's why apiserver restarts on large clusters are genuinely scary - the recovery traffic can be worse than whatever knocked it down.
kubectl get pods -A is a smaller version of the same thing. On a laptop against a dev cluster it's nothing. On a cluster with hundreds of thousands of Pods it tells the apiserver to assemble every Pod object, serialize the lot, and stream it to your terminal - a multi-hundred-megabyte response materialized in the apiserver heap for one human running one command. Run it during an incident, when the apiserver is already under pressure, and you can be the one who tips it over. I've watched it happen. The -A is doing a lot of quiet work.
The 1.5 MB wall and why pagination exists
etcd refuses any request above roughly 1.5 MB by default - that's the --max-request-bytes limit, and it's there for a reason. A single value can't be allowed to grow unbounded or it threatens the Raft log. The apiserver respects it. But a LIST result is obviously bigger than 1.5 MB on any real cluster, so the apiserver doesn't fetch the whole thing in one etcd call - it pages through etcd's keyspace in chunks under the hood.
Pagination is also exposed to you, and you should use it. A LIST with limit=500 returns 500 items plus a continue token, an opaque cursor pointing at where to resume. You pass it back on the next request and walk the collection in bounded pieces. The win isn't on the wire so much as in memory: the apiserver allocates a buffer for 500 objects, not for two hundred thousand. The unpaginated controller in our incident was the entire problem in one sentence - it asked for everything at once and the apiserver tried to give it everything at once.
There's a wrinkle worth knowing. Paginated LISTs historically could not be served from the watch cache - the cache held current state, not the snapshot-at-a-revision you need to page consistently, so a paginated LIST would fall through to etcd. For years that put you in a bind: paginate and hit etcd, or list-from-cache and blow up memory. Recent Kubernetes closed that gap, which is the next part.
Serving consistent reads from cache
For a long time the rule was simple and annoying: if you wanted a strongly consistent read - the latest data, guaranteed - it had to come from etcd via a quorum read, because the cache might be a few milliseconds behind. Since more than 80% of LISTs the apiserver handles are these consistent reads, that's a lot of load landing on etcd for data the cache very nearly already had.
The Consistent Reads from Cache work changed the deal. It leans on etcd's progress notifications: etcd periodically tells each watcher "you're current as of revision N." The apiserver records the latest revision it's seen from etcd, and when a consistent LIST comes in, it waits until the cache has caught up to at least that revision - a freshness check with a short timeout - then serves from memory. Same consistency guarantee, no per-object etcd fetch. The published numbers are good: in 99.9% of cases the cache became fresh enough within about 110 milliseconds. This landed as beta and on by default back in v1.31 (August 2024), and as of mid-2026 it's still riding as beta rather than formally GA, so check your version's feature gates if you're depending on the behavior.
Then there's the snapshot work. The Snapshottable API server cache (beta and default-on as of v1.34, September 2025) gives the cache lightweight, point-in-time snapshots - lazy copies built on a btree, sharing object pointers rather than duplicating data - so historical-revision and paginated LISTs can finally be served from cache instead of falling through to etcd. The bind I mentioned above mostly goes away: you can paginate and stay in the cache.
The streaming side moves too. WatchList, also called streaming lists, replaces the relist-then-buffer pattern with a watch-based initial list that streams objects one at a time instead of assembling the whole collection in memory first. The reported effect is dramatic - apiserver memory stabilizing around 2 GB in a test where the old path climbed to roughly 20 GB. The rollout has been bumpy: enabled by default in v1.32, then reverted to off-by-default in v1.33, and the client side still needs you to opt in via WatchListClient. So it's real and it's coming, but it is not yet the thing quietly protecting your cluster unless you turned it on.
Why informers exist at all
All of this is the backdrop for the single most important client-side fact: do not poll the apiserver, watch it. An informer (client-go's cache, the thing controller-runtime wraps) does one LIST to seed itself, then holds a long-lived WATCH and keeps a local copy of every object it cares about. After that initial list, your controller reads from its own in-process memory at zero cost to the apiserver. A reconcile loop that hits a shared informer cache makes no API calls; a reconcile loop that calls client.List every time makes one expensive call every time. Our incident controller did the second thing, against all secrets, with no pagination. That's three separate mistakes stacked into one reconcile, and any one of them removed would have kept the cluster up.
The decision framework
When you're touching the read path on a cluster of any real size, walk through this honestly.
An informer comes first, always. If you're reconciling, you want a shared informer or controller-runtime client backed by a cache, not raw
List/Getper loop. The informer LISTs once and watches forever, which is the difference between zero apiserver calls per reconcile and one heavy one.Then I scope the watch. A label selector or a single-namespace watch means the cache filters down to what you need and your event stream stays small. Watch all objects of a type cluster-wide when you care about a handful, and you end up watching everything and bookmarking constantly.
Anything outside an informer - a CLI tool, a migration script, an audit job - gets pagination: set a
limit, walk thecontinuetoken, never ask for the unbounded set. The buffer the apiserver allocates is proportional to your limit, not the collection size.Where stale is fine - informer warm-up, dashboards, anything that doesn't need this-instant accuracy -
resourceVersion=0takes the cheap cache read. Consistent reads are worth saving for when correctness actually depends on freshness.And before leaning on any of the cache behavior, check the cluster's version. Consistent-reads-from-cache, snapshottable cache, and WatchList have all moved through alpha/beta/reverted states on different timelines, so the protection you assume is on might not be.
Common mistakes
Unpaginated cluster-wide LISTs in a hot path. The classic. One
client.Listof everything, called on every reconcile, against a resource with a lot of objects. It works in staging with fifty objects and detonates in production with two hundred thousand.Polling instead of watching. A controller that GETs or LISTs on a timer when it should hold a watch. Every poll is load the informer would have eliminated; you're paying for a database query to learn nothing changed.
Treating
resourceVersionas a per-object counter. It's a global etcd revision. Comparing two objects' resourceVersions to decide which is "newer" within the same object is fine; reasoning about the absolute number as if it counts edits to that one object is wrong and will mislead you.Ignoring
410 Goneinstead of relisting. The only correct response to a410is to drop cached state and list again. Retrying the same watch from the same dead revision just loops. client-go handles this for you - hand-rolled watch code often doesn't.kubectl get pods -Aduring an incident. On a big cluster that's a multi-hundred-megabyte response assembled in an already-stressed apiserver heap. Scope it to a namespace, add a selector, or paginate, especially when things are on fire.Per-replica watches that don't share a cache. Multiple informers for the same resource inside one process, each opening its own watch, when a shared informer factory would open one. The apiserver fans out cheaply, but you can still multiply your own footprint pointlessly.
Assuming a big cluster's apiserver restart is routine. It triggers a relist from everything at once. The recovery storm can be worse than the original fault, and that's the moment to have pagination and informers already in place, not to discover you don't.
The whole architecture is one cache standing between a quorum-consistent log and ten thousand things that want to read it constantly. etcd holds the truth, the watch cache holds a live copy so etcd doesn't get mobbed, and informers hold a copy of the copy so the apiserver doesn't get mobbed either. Every outage I've seen on this path was someone reaching past one of those layers - hitting the apiserver like it was etcd, or hitting etcd like it was a local map. The layers exist because the thing underneath them can't survive being read directly at scale.