
Kubelet eviction: the logic that kills the wrong pod
soft vs hard thresholds, memory.available, nodefs, QoS ranking, kernel OOM race, node NotReady cascade

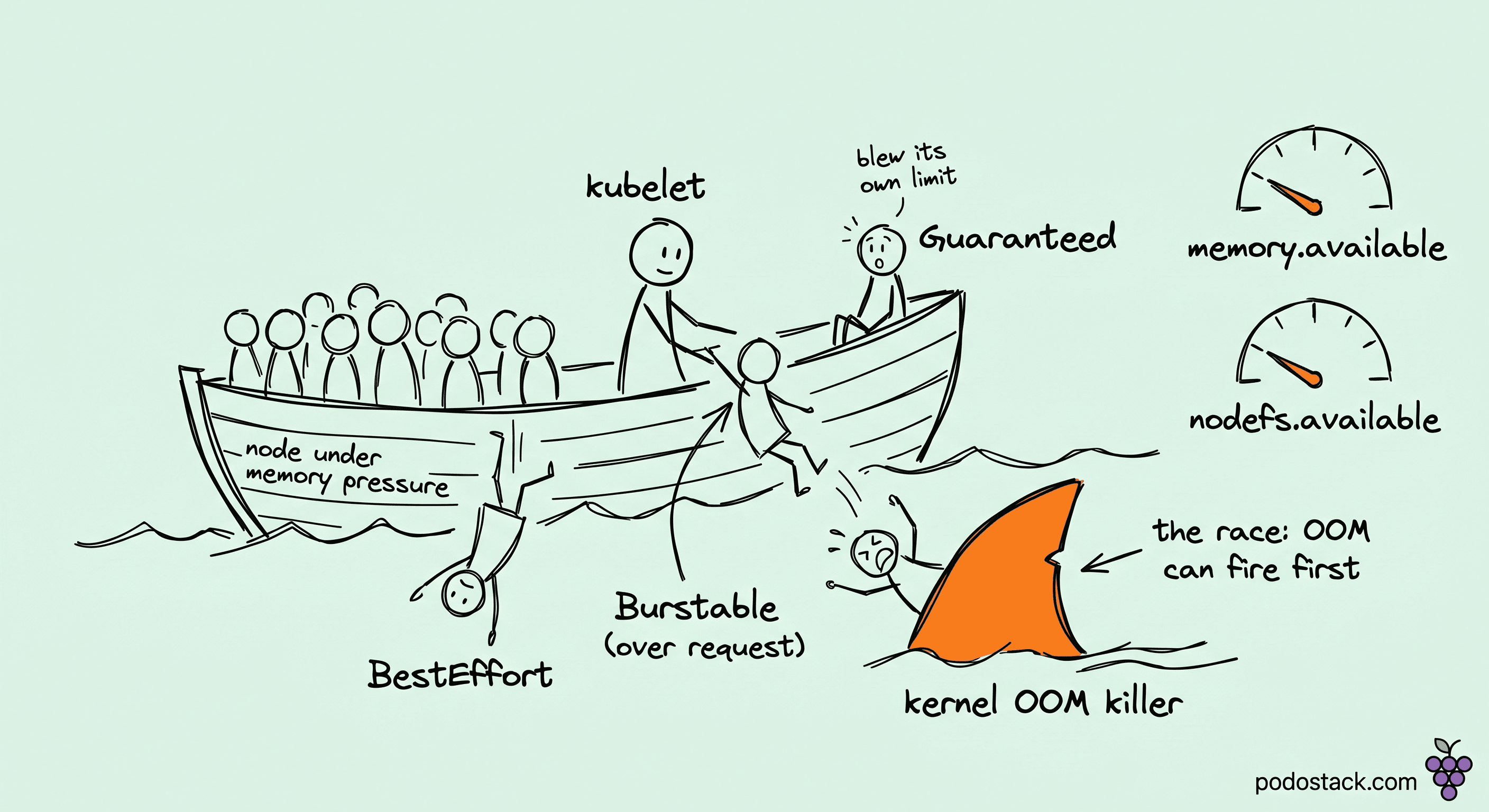
The postmortem started with a question nobody could answer: why did the payment service die while the log shipper lived? The node had run out of memory, that part was clear. But the thing that got killed was the one workload we'd actually marked as important, and the thing that survived was a BestEffort DaemonSet whose entire job was to tail files and forward them. We'd spent a sprint setting requests and limits on the payment pods precisely so they'd be protected. They weren't. The log shipper had no requests at all, was using a few hundred megabytes, and sailed through the whole event untouched while the payment pod took an OOM kill from the kernel before the kubelet ever printed an eviction line.
That gap - between what we thought protected a pod and what actually decided its fate that night - is the whole subject. There are two completely separate mechanisms that can kill a pod under memory pressure, they run on different clocks, and the one that fires first is often not the one you tuned for.
Two thresholds: soft and hard
The kubelet watches the node and evicts pods before the node becomes unusable. It does this off a set of eviction signals, and you configure two families of thresholds against those signals.
Hard thresholds fire immediately. When the signal crosses the line, the kubelet picks a pod and kills it with no grace period - the pod's terminationGracePeriodSeconds is ignored, it gets effectively zero seconds to clean up. The default memory.available<100Mi is a hard threshold on most distributions. The point of hard eviction is to act fast enough that the node doesn't fall over entirely, which means it can't afford to wait for graceful shutdown.
Soft thresholds fire only after the signal has stayed over the line for a configured grace period. You set them as a pair: eviction-soft gives the threshold, eviction-soft-grace-period gives how long it has to hold before the kubelet acts. There's also eviction-max-pod-grace-period, which caps the graceful shutdown the evicted pod gets. So a soft eviction is the polite one: the signal degrades, it stays degraded for, say, ninety seconds, and only then does the kubelet start a graceful termination that itself respects a bounded grace window. The intent is to catch slow leaks before they turn into a hard-threshold emergency.
Where I've seen this go wrong is a node configured with only hard thresholds, or with a soft grace period set so long the node is already in trouble before it expires. The cluster in the postmortem ran memory.available<100Mi with no soft tier above it, so every memory event was a no-grace kill and we'd quietly given up any chance to drain a leaking pod cleanly.
Links
Node-pressure Eviction - the canonical reference for how the kubelet monitors signals and acts on them.
Eviction thresholds: soft vs hard - how grace periods and the no-grace hard tier are configured.
The four signals, and the two that fool you
The kubelet evicts on four signals, and two of them surprise people by what they don't do.
memory.available is the one everyone knows. It's not just "free RAM" - the kubelet computes it from the cgroup's working set, deliberately excluding reclaimable page cache, so it tracks memory the kernel can't easily get back. When this drops below the threshold, the node goes MemoryPressure.
nodefs.available is free space on the filesystem the kubelet uses for volumes and pod-level scratch (logs, emptyDir).
imagefs.available is free space on the filesystem the container runtime uses for images and writable layers. On many setups these are the same disk, but they can be split, and the eviction behavior differs: low nodefs evicts pods, low imagefs first triggers image garbage collection before it starts evicting. Both also have an inodes variant (nodefs.inodesFree, imagefs.inodesFree) that catches the case where you've run out of inodes long before you've run out of bytes - a pile of tiny files will do that, and it's a genuinely confusing page when df shows free space and the node is still under disk pressure.
pid.available looks like it belongs with the others but behaves differently. When the node runs low on process IDs, the kubelet sets PIDPressure on the node, which taints it so the scheduler stops placing new pods there. It does not evict running pods to reclaim PIDs. So PID pressure is a scheduling brake, not an eviction trigger - the kubelet only evicts to reclaim memory and disk. A fork bomb in one pod will mark the node unschedulable but won't get that pod evicted by the eviction logic; you're relying on the pod's own PID limit to contain it.
How it ranks the pods
Once the kubelet decides to evict, it has to choose a victim, and the order is where our payment-service postmortem went sideways.
The first sort key is QoS class. BestEffort pods - no requests, no limits - go first. Then Burstable pods, which set requests below limits. Guaranteed pods, where requests equal limits on every container, go last. That's the design: you declare a pod important by giving it requests equal to limits, and the eviction logic honors that by killing it only as a last resort.
But QoS is the first key, not the only one. Within the consideration, the kubelet ranks by how far a pod's usage of the pressured resource exceeds its request. A Burstable pod sitting way above its memory request is a more attractive victim than one near its request, and pod priority feeds in too. The practical consequence is that a pod with no request for the pressured resource is treated as exceeding "zero" by its entire usage, which sounds bad for it, except a BestEffort pod that's barely using anything is also the cheapest thing to kill first by class. The ranking is doing something reasonable; it just isn't "kill whoever is using the most".
Which is exactly how the log shipper survived. It was BestEffort, so by class it should have died first - but the kubelet never got to run its ranking, because the kernel got there first.
Links
Pod selection for kubelet eviction - the actual ranking: QoS class first, then usage over request.
Pod Quality of Service Classes - how Guaranteed/Burstable/BestEffort get assigned and what each means.
The race the kubelet can lose
The kubelet's eviction loop is not the only thing that kills pods, and it's not even the fast one. The Linux kernel OOM killer runs in kernel space, on its own schedule, and it fires when a cgroup or the node hits a hard memory wall. The kubelet's eviction loop polls signals on an interval (the housekeeping period, on the order of seconds) and then has to select, signal, and wait. The kernel OOM killer fires in the time it takes a single allocation to fail.
So under a fast allocation spike - not a slow leak, a sudden burst - the kernel can OOM-kill a process inside a pod before the kubelet's next poll even notices memory.available dropped. That's what the dmesg timestamps showed us that night: the kernel's Killed process line landed almost a full second before the kubelet logged anything at all. When that happens, the kubelet didn't choose the victim. The kernel did, using its own oom_score, which Kubernetes biases by QoS (BestEffort gets a high, easy-to-kill oom_score_adj; Guaranteed gets a low one), but the kernel's accounting is per-cgroup and per-process, not "which pod is least important globally". A container that exceeds its own memory limit gets OOM-killed by its cgroup regardless of node-level pressure or its neighbors' importance.
This is why a Guaranteed pod can still die to OOM. Guaranteed protects you from kubelet eviction - it's last in that ranking. It does not protect you from your own limit. If a Guaranteed pod allocates past its memory limit, the cgroup OOM killer kills a process in that pod immediately, and the kubelet's nice QoS-aware ranking never enters the picture. In our incident the payment pod hit a request burst, its working set crossed its limit, and the cgroup OOM killer took it out while the kubelet was still mid-poll. The log shipper was never close to its (nonexistent) limit, so nothing touched it. The protection we'd built was real but aimed at the wrong killer.
Links
Node out of memory behavior - why the kernel OOM killer can fire before the kubelet's next poll.
Resource requests and limits - how a container's own limit drives the cgroup OOM kill, independent of node pressure.
Reclaim, and why the node goes NotReady
Two more mechanics close the loop on a bad memory event.
eviction-minimum-reclaim stops the kubelet from evicting one pod, dropping just barely back over the line, and then evicting again thirty seconds later when it tips back under. For each signal you can specify how much headroom to reclaim past the threshold, so a single eviction round frees enough that the node sits comfortably above the line for a while instead of flapping at the edge. Without it, a node under steady pressure can churn through pod after pod, each eviction buying only seconds.
The NotReady cascade is the failure mode that turns one hot node into a cluster event. When a node is under sustained pressure, the kubelet can get starved - it's competing for the same exhausted memory or a pegged disk - and if it can't post its status to the API server in time, the node goes NotReady. Once a node is NotReady past the eviction timeout, the control plane starts evicting (rescheduling) its pods elsewhere. Those pods land on other nodes, and if the root cause was a workload that leaks everywhere it runs, the next node starts climbing toward pressure too. One node's local problem becomes a rolling reschedule that walks across the cluster. The node-level eviction logic was trying to save one node; the control-plane reaction to NotReady can spread the load that's killing it.
Two things called "eviction"
The word "eviction" gets used for two unrelated mechanisms, and the first time that bit me it cost an afternoon of confusion.
Everything above is node-pressure eviction: the kubelet, acting locally, killing pods to save its node. It doesn't consult PodDisruptionBudgets, doesn't ask the control plane, and under hard thresholds doesn't even honor graceful termination. It's a survival reflex, and it'll violate your PDB without hesitation, because the alternative is the whole node going down.
The other one is API-initiated eviction - the Eviction API, the thing kubectl drain calls and what the control plane uses for voluntary disruptions. This one does respect PodDisruptionBudgets: if evicting a pod would take a deployment below its minAvailable, the API call is refused. It's the polite, planned path for node maintenance and autoscaler scale-down.
The expensive assumption is that a PDB protects against node pressure. It doesn't. A PDB is a contract for voluntary disruptions - drains, upgrades, scale-down. When a node is out of memory, the kubelet evicts past the PDB because there's no negotiating with a node that's about to lock up. If you need a workload to survive node pressure, the lever is QoS and limits, not a disruption budget.
Links
API-initiated Eviction - the other "eviction": the Eviction API that drains nodes and respects PDBs.
Disruptions and PodDisruptionBudget - why a PDB governs voluntary disruption only, not node-pressure eviction.
Which dial to turn for which killer
Everything I'd tune here starts from which killer I'm defending against, because the two want different settings.
If a workload must not die to kubelet eviction, the move is requests equal to limits so the pod is Guaranteed, which puts it last in the kubelet's ranking. The catch we learned the hard way: that buys protection from node-pressure eviction, not from the cgroup OOM killer, so the same setting arms the other killer if you size the limit too low.
Surviving the OOM killer is a different lever entirely - the limit itself, high enough to cover real peak working set and not just the steady state, because the cgroup kills the instant you cross it. A Guaranteed pod with a too-tight limit dies more readily than a Burstable one with a generous limit. Profile the peak, don't guess it.
Then there's the node itself. Reserve resources with system-reserved and kube-reserved so the kubelet and the OS aren't fighting pods for the last megabytes. A node that hands every byte to pods is a node where the kubelet starves and goes NotReady under pressure, which is exactly how a local event turns into the cascade.
And above the hard tier, configure a soft one, so slow leaks get a graceful eviction with a real grace period before anything hits the no-mercy threshold. Hard-only configs throw away the chance to drain a pod cleanly.
Links
Reserve Compute Resources - system-reserved and kube-reserved so the kubelet and OS don't starve under pressure.
Minimum eviction reclaim - eviction-minimum-reclaim to stop a pressured node from flapping.
The patterns that turn one hot node into an incident
These are the ones I keep running into, roughly in order of how often they catch a team:
Trusting a PDB to survive node pressure. It governs drains and voluntary disruption only; the kubelet evicts straight through it when the node is starving.
Then there's setting limits from steady-state usage instead of peak. The cgroup OOM killer fires on the peak, and a Guaranteed pod with a snug limit dies to its own cgroup while you're admiring its QoS class.
Leaving critical workloads BestEffort because "they don't use much" puts them first in line for kubelet eviction and hands the kernel a high
oom_score_adj- cheap to kill on both paths.Hard thresholds with no soft tier above them turn every memory event into a zero-grace kill, and you never get a clean drain out of a slow leak.
Forget
eviction-minimum-reclaimand a pressured node flaps - evict, tip back under, evict again - churning pods for seconds of relief each.Hand the node's entire memory to pods with nothing reserved for system and kubelet, and the kubelet starves, misses its status post, the node goes NotReady, and the control plane reschedules the leak onto the next node.
Last, assuming low
imagefsand lownodefsbehave the same. Low image filesystem triggers image GC first; low node filesystem goes straight to evicting pods. And both can hit on inodes while df still shows free bytes.
We left that postmortem having moved one number: the payment pod's memory limit went up by 40%, and the next request spike rode under it instead of through it. "Important" had never been a single dial. We'd set QoS thinking we'd bought protection, and we had - against the kubelet. The kernel doesn't read your QoS class the way the kubelet does, it reads your cgroup, and it acts in microseconds where the kubelet acts in seconds. Two killers, two clocks, and the disruption budget we'd also been counting on was never written to show up to either fire.