
Postgres partitioning: the pruning that doesn't happen
Declarative partitioning, partition pruning, partition-wise joins, Citus, sharding

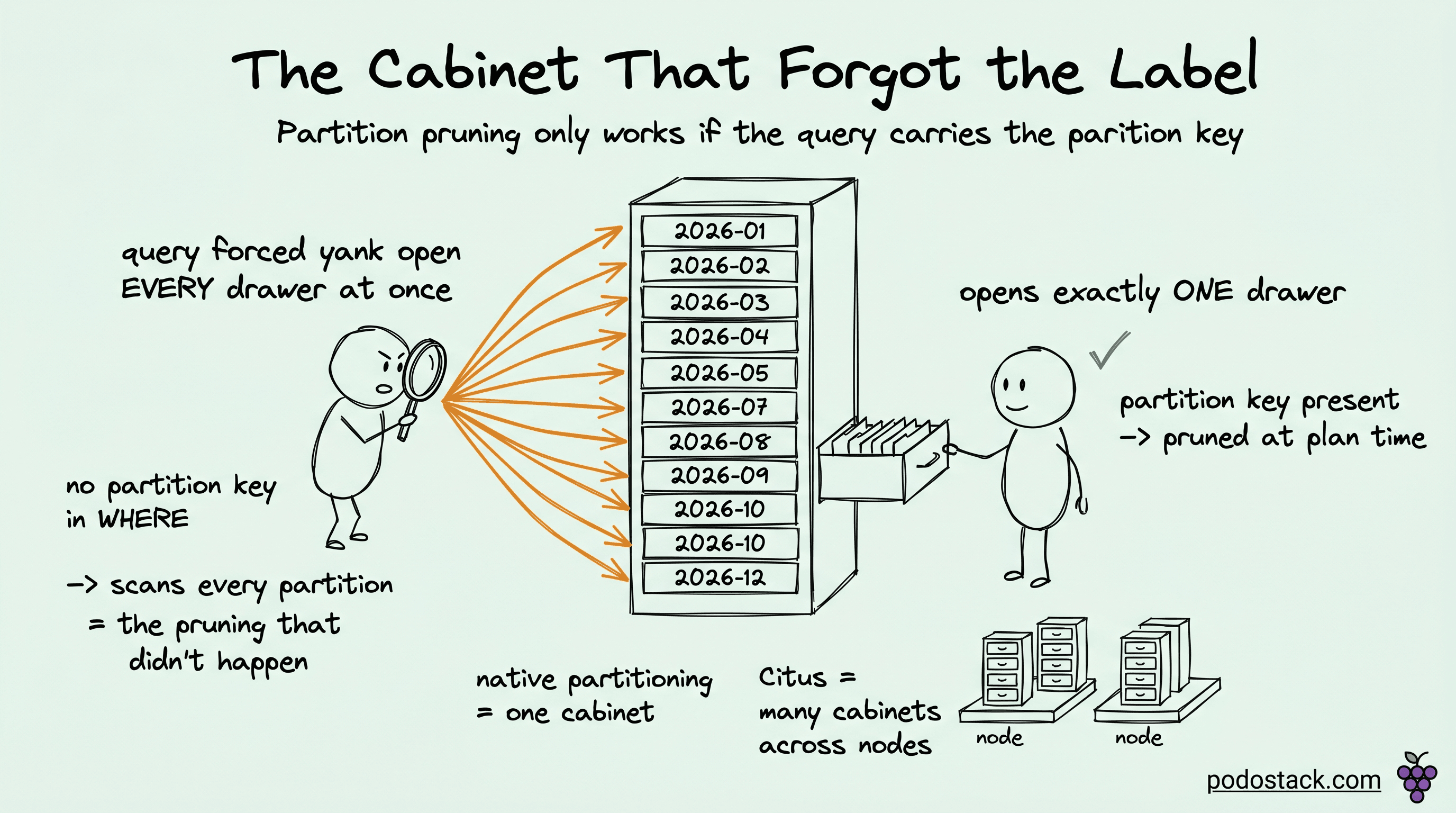
The table had been "partitioned for performance" six months before I got there, and the queries were slower than before anyone touched it. Monthly range partitions, two years of them, twenty-four child tables under one events table. Looked textbook. Then I read the slow query log and the thing every report ran was a filter on user_id and a date range expressed as created_at >= now() - interval '7 days'. The partition key was event_date. Not created_at, a different column the ETL had stopped populating consistently. So every query scanned all twenty-four partitions, every time, and paid the planning overhead of twenty-four tables on top. Partitioning hadn't sped anything up. It had added a tax and pruned nothing, because the planner never had the key it needed to prune.
That's the failure I want to talk you out of. Partitioning is a manageability tool that can speed some queries up as a side effect. It is not a performance feature you turn on. When it makes things faster it's because of pruning, and pruning only happens under conditions that are easy to miss.
What declarative partitioning actually gives you
Since Postgres 10 you write PARTITION BY and the database maintains the routing. There are three strategies. RANGE splits on ordered values, dates and sequential IDs being the common cases. LIST splits on discrete values, like a region or a tenant. HASH spreads rows across a fixed number of partitions by a hash of the key, for when you want even distribution and have no natural range. You declare the parent, attach child partitions, and inserts land in the right child automatically.
What you have not done is distribute anything. Every partition lives in the same Postgres instance, on the same disk, served by the same process. Native partitioning is organization, not scale-out. It's one table the planner is allowed to treat as several. That distinction is the whole back half of this piece, so hold onto it.
The reason to do it at all comes down to three things that get genuinely easier. Dropping old data becomes a DETACH and a DROP of one partition instead of a DELETE that bloats the heap and chews autovacuum. Bulk loads can target one partition. And the planner can sometimes skip partitions entirely. That last one is pruning, and it's the only one that touches query speed.
Pruning, and when the planner can't do it
Partition pruning is the planner deciding it doesn't need to look at a partition because the query's conditions can't match anything in it. Filter on the partition key with a value that falls in March, and Postgres reads the March partition and ignores the other twenty-three. That's the speedup people are chasing. It's real, and it's worth a lot when it fires.
The catch is in the word "key". Pruning needs the partition key in the query's conditions. Omit it, and there's nothing to prune on, so the planner reads every partition. A query that filters on user_id against a table partitioned by date will scan all of them and then filter inside each, which is strictly more work than the same query against an unpartitioned table with the right index. This is exactly what bit the table I opened with. Partitioning a table on a column your queries don't filter on is worse than not partitioning it.
There are two moments pruning can happen, and the difference matters when you read plans. Plan-time pruning is when the partition key is a constant the planner sees while planning, like a literal date. It drops the partitions right there and the plan only mentions the survivors. Runtime pruning is when the key's value isn't known until the query runs, which covers parameters in a prepared statement and the inner side of a nested loop join. Postgres can still prune in those cases, but it happens during execution, so EXPLAIN without ANALYZE will show all the partitions in the plan even though most get skipped at run time. I've watched people panic at a plan listing forty partition scans that, when actually run, touched two. Run it with ANALYZE and look at (never executed) on the partitions that got pruned.
One more way pruning quietly fails: wrap the partition key in a function or a type cast and the planner often loses the ability to prune. A query that filters on date_trunc('day', event_date) instead of plain event_date can scan every partition, because the planner reasons about the bare column, not the expression around it. Same with an implicit cast when the literal type doesn't match the column type. The query looks like it filters on the key, the plan disagrees, and the only way to catch it is to read the plan rather than trust the SQL.
Older Postgres had constraint_exclusion, a cruder mechanism from the inheritance-based partitioning era. It compares CHECK constraints against the query at plan time only, it's controlled by a GUC that defaults to partition, and it can't do runtime pruning at all. If you're on modern declarative partitioning you mostly get the better pruning automatically, but mixed setups and legacy inheritance trees can still fall back to constraint exclusion and its plan-time-only limits, which is one more reason a plan shows partitions you expected gone.
The cost of too many partitions
The instinct after learning pruning is to partition finely: daily partitions, a partition per tenant, thousands of them. That instinct has a sharp edge.
Planning time grows with partition count. The planner has to consider each partition, and even with pruning it does work proportional to how many it started with before pruning. A query against a table with a few dozen partitions is fine. The same query against several thousand can spend more time planning than executing, especially for short OLTP queries where the execution was going to be a millisecond anyway. There's a real ceiling here, and it's lower than people expect.
Locks are the other tax. Operations that need to touch the parent can acquire locks across all partitions, and a query that can't prune locks every one of them. Under concurrency that's a lot of lock entries, and the lock table is finite. I've seen a cron job that scanned an over-partitioned table blow past max_locks_per_transaction and take down writes that had nothing to do with it. And every partition is its own table with its own statistics, its own autovacuum bookkeeping, its own indexes to maintain. A thousand partitions is a thousand of each. The manageability win you partitioned for starts eating itself.
Partition-wise joins, and the flag that's off
When you join two tables partitioned the same way on the same key, Postgres can join them partition by partition instead of joining the whole things and sorting it out after. March-against-March, April-against-April, never crossing. For large partitioned joins that's a big saving, and the same idea applies to aggregates that group by the partition key.
The catch that surprises people: it's off by default. enable_partitionwise_join and enable_partitionwise_aggregate both default to off, because the planning cost is higher and it only pays off when the partitions line up. So you can build two perfectly matched partitioned tables, join them, and get the naive plan because nobody flipped the GUC. The feature exists, you opted into the partitioning, and you still don't get the optimization until you ask for it explicitly.
Attach, detach, and rolling windows
The pattern that justifies partitioning for a lot of teams is the time window. You keep ninety days of events, you partition by day or week, and aging out old data is a DETACH PARTITION followed by a DROP TABLE on the detached child. No giant DELETE, no bloat, no vacuum storm. The space comes back instantly because you dropped a whole table.
Going the other way, ATTACH PARTITION folds a populated table into the parent. Postgres validates that its rows fall within the partition bounds, which is a scan unless you've pre-created a matching CHECK constraint that lets it skip the validation. On a big table that's the difference between an attach that takes a lock for a second and one that scans for minutes. Worth knowing before you run it in the middle of the day. Detach got a CONCURRENTLY option in Postgres 14 specifically so you can pull a partition out without a long lock on the parent, which matters when the parent is serving live traffic.
Indexes on partitioned tables
Create an index on a partitioned parent and Postgres creates a matching index on every partition and on every partition you add later. That's usually what you want, and it mostly behaves like a normal index per partition. The corner is uniqueness. A unique constraint on a partitioned table has to include the partition key, because Postgres can only enforce uniqueness within a partition, not across them. So you can't declare UNIQUE (email) on a table partitioned by region the way you would on a plain table. The constraint becomes UNIQUE (email, region), which is not the same guarantee. People discover this when their dedup logic lets the same email through in two regions, and the fix is a different schema, not a different index.
Where native ends and Citus begins
The word "partitioning" muddies this one, because Citus calls its thing partitioning too and it's a different animal. Native partitioning organizes one table on one machine. Citus distributes one logical table across many machines, with a coordinator that routes and a set of workers that each hold shards. Whenever a team asks me "which is better," I push back: the real fork is whether your problem is organization or capacity, and the two tools sit on opposite sides of it.
Native is enough when your data fits one machine and your pain is manageability or a specific pruning win. A few hundred gigabytes, time-series you age out, a hot date range your queries actually filter on, all single-node problems. Adding Citus there buys you a coordinator, a multi-node cluster, network hops on every query, and a distribution key you have to design your schema around, in exchange for solving a problem you didn't have. I've watched a team reach for Citus at 200 GB and spend a quarter on operational overhead that a few range partitions and an index would have settled in an afternoon.
You actually need Citus when one machine genuinely can't hold the data or serve the write throughput, and when your access pattern has a distribution key that most queries carry, so the coordinator can route to a single worker instead of fanning out to all of them. Multi-tenant SaaS where every query filters by tenant_id is the textbook fit, because the tenant key shards cleanly and most queries hit one shard. Get the distribution key wrong and you're back to fan-out across every worker, which is the distributed version of the no-pruning problem from the start of this piece, only now it's spread over the network. The failure mode rhymes. A query without the key scans everything, whether everything is twenty-four local partitions or forty remote shards.
The ones I keep running into
These show up again and again, roughly in the order they tend to bite:
Partitioning on a column your queries don't filter on. No pruning, full fan-out, plus the per-partition planning tax. It's the single most common way partitioning makes things slower, and it's exactly what I walked into in the opener.
Then the
EXPLAIN-without-ANALYZEpanic at every partition in the plan. Runtime pruning doesn't show up there. Run it for real and check for(never executed).Partitioning too finely is the next trap: thousands of daily partitions turn planning time and lock counts into the bottleneck, and a cron job over the parent can exhaust the lock table and take writes down with it.
Expect partition-wise joins to just work and you'll be disappointed - they're behind
enable_partitionwise_join, off by default, so matched partitioned tables still get the naive plan until you flip it.A unique constraint doesn't behave like it does on a plain table either. It has to include the partition key, so
UNIQUE (email)quietly becomes per-partition uniqueness and your dedup leaks across partitions.Reaching for Citus before you've hit a single-machine wall is the expensive one. If the data fits one box and the queries carry the right key for native pruning, Citus is operational weight you're carrying for nothing.
And last, a Citus distribution key that most queries don't include. Every query fans out to every worker, the same no-pruning failure as native partitioning, now distributed across the network and far harder to debug.
Partitioning earns its keep on manageability: dropping old data cleanly, loading in bulk, keeping a rolling window without a vacuum storm. The query speedup is a conditional bonus that shows up only when the planner can prune, which means only when your queries carry the partition key. Decide what you're actually buying before you cut the table into pieces. Most of the time the honest answer is "easier data lifecycle", and if you went in expecting "faster queries" you'll end up like that events table, paying a tax and pruning nothing.