
Quorum Queues, Streams, and Why Your RabbitMQ Cluster Is Lying to You
Raft-based queues, append-only streams, non-voter replicas, broker policies, and cluster partition strategies

RabbitMQ has been around since 2007. Most teams are still running it like it’s 2015 - classic mirrored queues, ha-mode: all policies, and a prayer that nobody pulls the network cable during sync.
This week: the RabbitMQ features that changed the game in the last few releases. Raft-based queues that actually protect your data, a Kafka-like streaming layer built into the broker, and a scaling trick that separates durability from consensus.
The Pattern: Quorum Queues
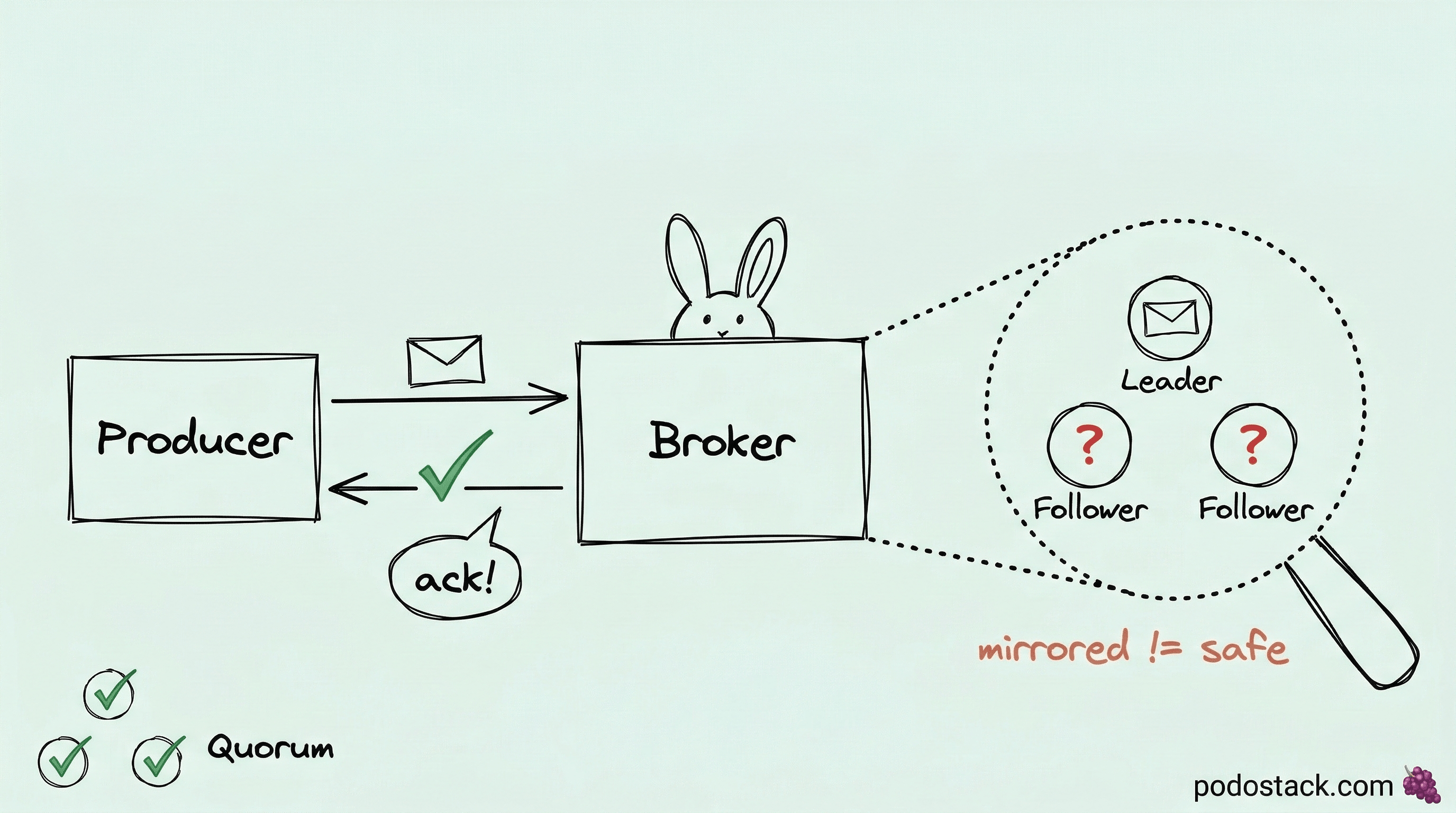
Mirrored queues are dead. Quorum queues are the replacement.
Classic mirrored queues had a dirty secret. During synchronization, the entire queue blocked. New messages couldn’t be consumed. On a large queue, this could last minutes. And if a node went down during sync? Data loss. The mirror wasn’t really a mirror - it was a best-effort copy that fell apart under pressure.
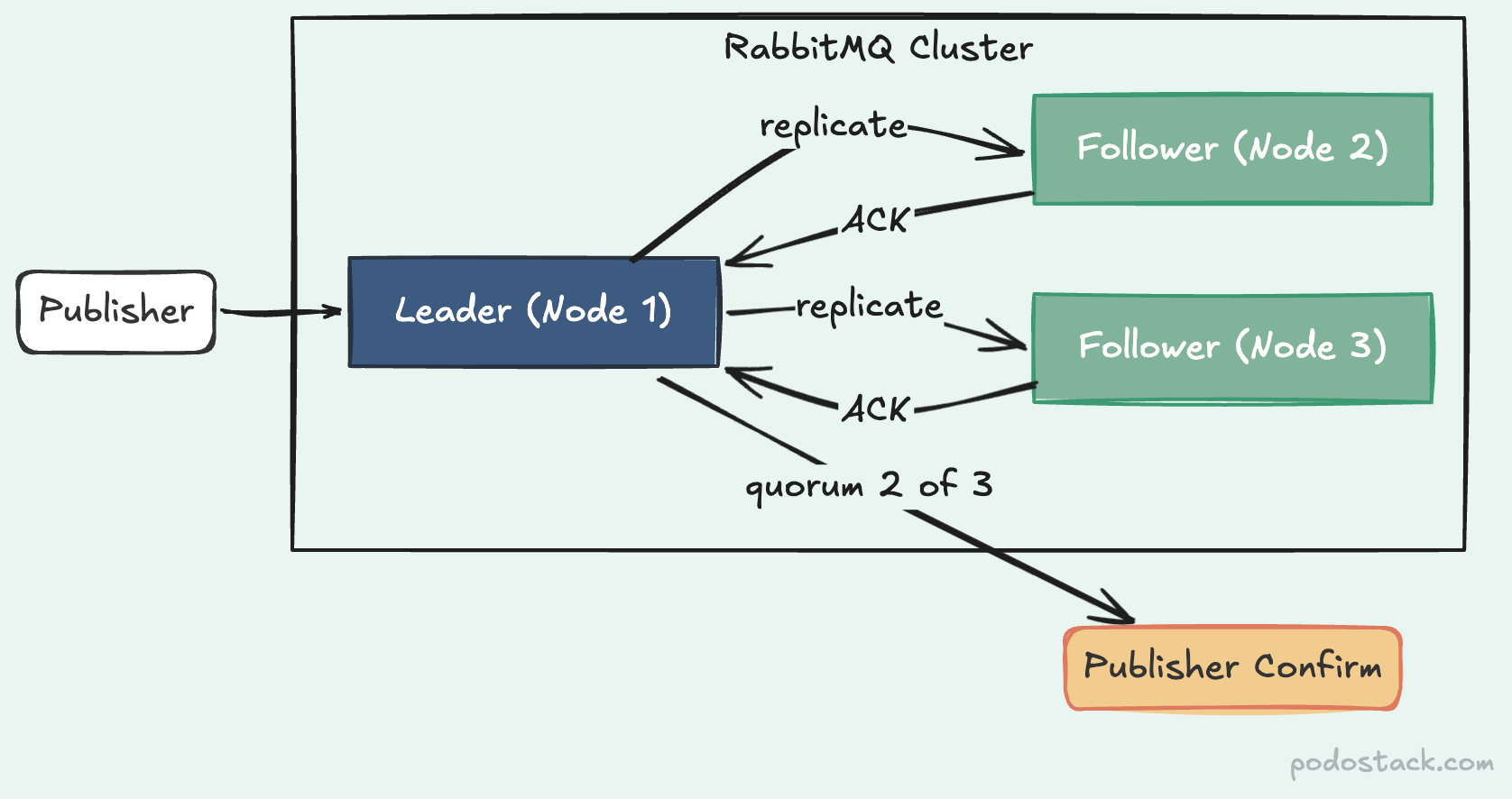
Quorum queues fix this with Raft consensus. Same algorithm etcd and Consul use. Every message gets written to a Write-Ahead Log on the leader node, then replicated to followers. A publish is only confirmed when a majority (quorum) of nodes acknowledge the write.
Three nodes, quorum of two. If one node dies, the remaining two elect a new leader automatically. No sync blocking. No data loss. The K8s operator makes it declarative:
apiVersion: rabbitmq.com/v1beta1
kind: Queue
metadata:
name: orders
spec:
name: orders
type: quorum
durable: true
rabbitmqClusterReference:
name: my-clusterThe trade-off: quorum queues don’t support TTL per message, priorities, or exclusive queues. If you need those, classic queues still work. But for anything where “don’t lose my messages” matters - and that’s most things - quorum queues are the answer.
Links
Hidden Gem: RabbitMQ Streams
Kafka-like capabilities without running Kafka.
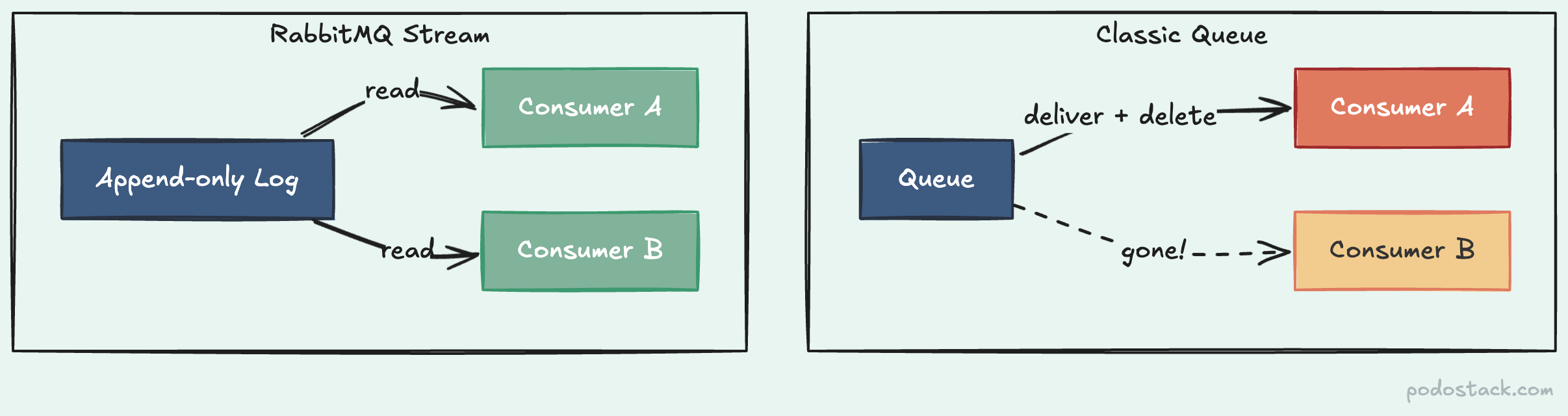
Here’s the thing about classic queues - once a consumer acknowledges a message, it’s gone. Poof. Another consumer can’t read it. You can’t replay it. If you needed replay or fan-out, you ran Kafka alongside RabbitMQ and glued them together.
RabbitMQ Streams changed that. A stream is an append-only log. Messages aren’t deleted after consumption - they stay in the log until a retention policy removes them (by time or size). Multiple consumer groups read the same stream independently, each tracking their own offset.
Think of it this way. A classic queue is a bulletin board where you tear off the flyer after reading it. A stream is a newspaper - everyone gets their own copy, and you can re-read yesterday’s edition.
The use cases are exactly what you’d expect: telemetry ingestion, event sourcing, clickstream analytics, audit trails. Anything where “I need to replay from 3 hours ago” is a valid requirement.
Enable the plugin, declare with x-queue-type: stream, and set retention:
apiVersion: rabbitmq.com/v1beta1
kind: Queue
metadata:
name: events
spec:
name: events
type: stream
arguments:
x-max-age: "7D"
rabbitmqClusterReference:
name: my-clusterYou don’t need to run Kafka for replay anymore. You might still want Kafka for other reasons - partitioning, exactly-once semantics, the ecosystem. But for “I just need fan-out and replay inside my existing RabbitMQ cluster,” Streams deliver.
Links
The Showdown: Quorum Queues vs Classic Mirrored
Replication: ha-sync (blocking) → Raft consensus (non-blocking)
Data safety: Best-effort → Quorum-confirmed writes
Leader election: Slow, manual intervention → Automatic via Raft
Message TTL: Supported → Not supported
Priority queues: Supported → Not supported
Status: Deprecated since 3.13 → Recommended default
The verdict: if you’re still running ha-mode: all policies, you’re using a deprecated feature that was never safe to begin with. Migrate to quorum queues. The only exceptions are workloads that genuinely need per-message TTL or priority - and even there, consider DLX-based TTL as a workaround.
Deep Dive: Non-Voter Replicas
More copies of your data without slowing down writes.
Raft has a scaling problem. Every voter must acknowledge a write before it’s confirmed. Three voters, quorum of two - fast. Seven voters, quorum of four - noticeably slower. Every additional voter adds network round-trip latency.
The quorum_queue_non_voters feature flag solves this. It lets you add replicas that receive the full replication stream but don’t participate in voting. Think ZooKeeper observers or etcd learners - same concept.
Seven replicas, but only three vote. Quorum stays at two. Write latency stays fast. The other four replicas hold complete copies of your data for durability and read distribution, without slowing down the consensus path.
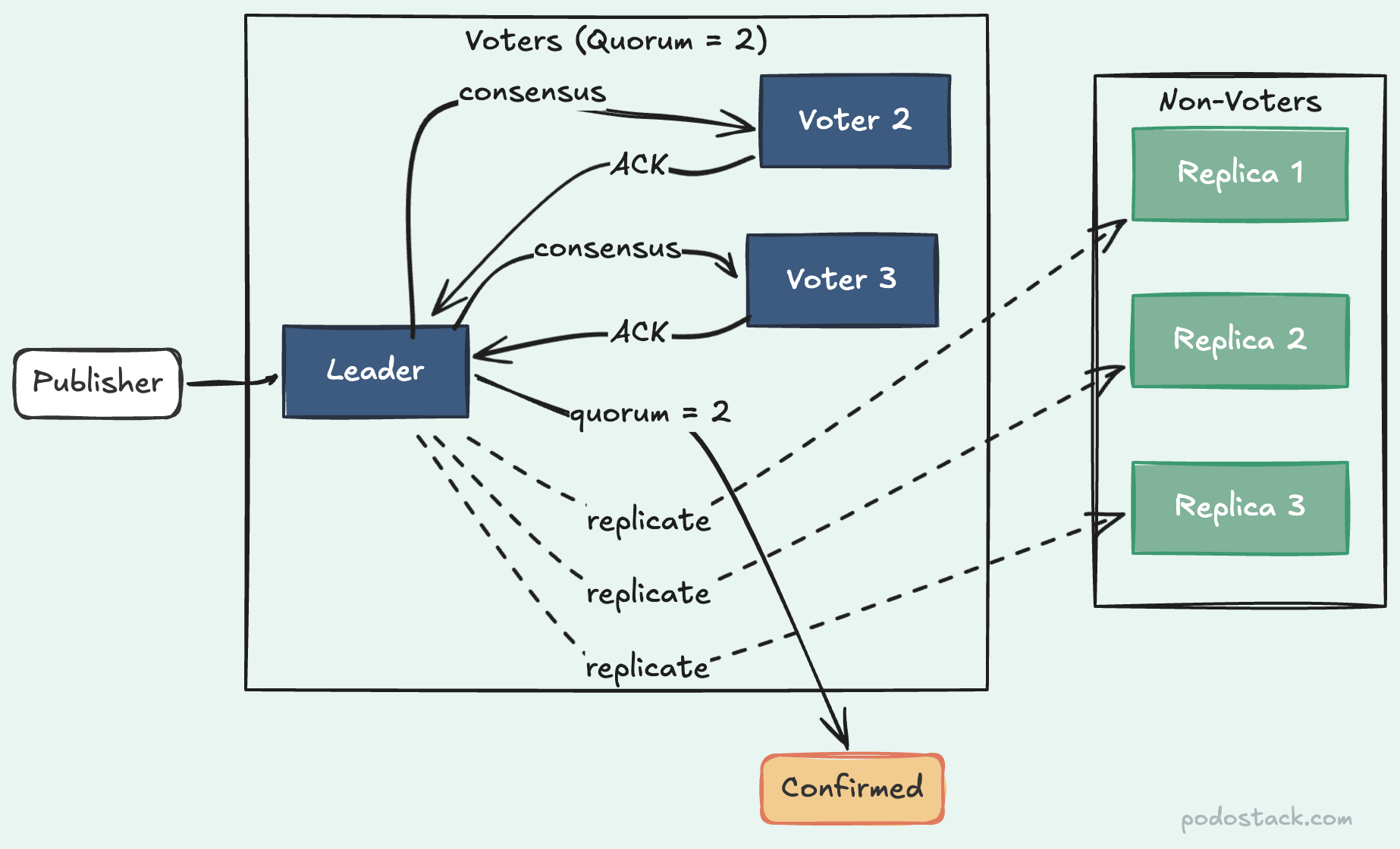
Standard (3 replicas): 3 voters, quorum of 2 — low write latency
Standard (7 replicas): 7 voters, quorum of 4 — high write latency
Non-voters (7 replicas): 3 voters, quorum of 2 — low write latency
Use this for geo-distributed clusters where you want replicas in every AZ but can’t afford cross-region consensus latency. Or for compliance requirements that demand 5+ copies without killing throughput. If a voter goes down, a non-voter gets promoted automatically.
Links
The One-Liner: Broker Policies
rabbitmqctl set_policy DLX ".*" \
'{"dead-letter-exchange":"dlx"}' \
--apply-to queuesOne command. Every queue in the cluster now routes dead-lettered messages to your DLX. No code changes. No redeployment.
RabbitMQ policies are server-side regex rules that apply configuration to queues and exchanges by name pattern. TTL, max-length, DLX, queue type - all manageable without touching application code. Priority-based: a specific policy (^orders\.) overrides a global one (.*). Changes apply instantly, no restart needed.
Stop hardcoding TTL and DLX in your app. Let the broker own its own configuration.
Links
Questions? Feedback? Reply to this email. I read every one.
Podo Stack - Ripe for Prod.