
Redis persistence: why RDB and AOF both lie about durability
RDB snapshots, AOF fsync, fork latency, hybrid preamble, replication

The page said the cache lost the last minute of writes. Not the whole dataset, not corruption, just the last minute. We'd been running with the default save points and appendonly off, and when the box got OOM-killed the most recent snapshot was 54 seconds old. Everything written in those 54 seconds was gone. The part that stung is that we'd ticked the "persistence enabled" box in the Helm chart eighteen months earlier and never looked again. Persistence was on. Durability was not. Those are different words, and Redis lets you confuse them for as long as nothing crashes.
Two mechanisms, two different lies
Redis gives you two on-disk formats and they fail in opposite ways. RDB is a point-in-time snapshot of the whole dataset, written periodically. AOF is an append-only log of every write command, replayed on restart. Most teams pick one without reading what each one promises, and the gap between the promise and the default is where the data goes.
The same applies to Valkey, byte for byte. Valkey is the BSD-licensed fork of Redis 7.2.4 that AWS, Google, and the Linux Foundation stood up after the 2024 license change, and it inherited the persistence engine unchanged. RDB and AOF files are compatible across both. Everything below is the same engine talking, so when I say Redis, read Valkey too.
Neither format is the thing people think they bought. RDB loses everything since the last snapshot. AOF in its default config loses up to a second. And both can stall your tail latency hard enough that the SRE on call assumes the node is dying. Which failure mode you hit comes down entirely to the knobs you left at default, so the two formats are worth taking one at a time.
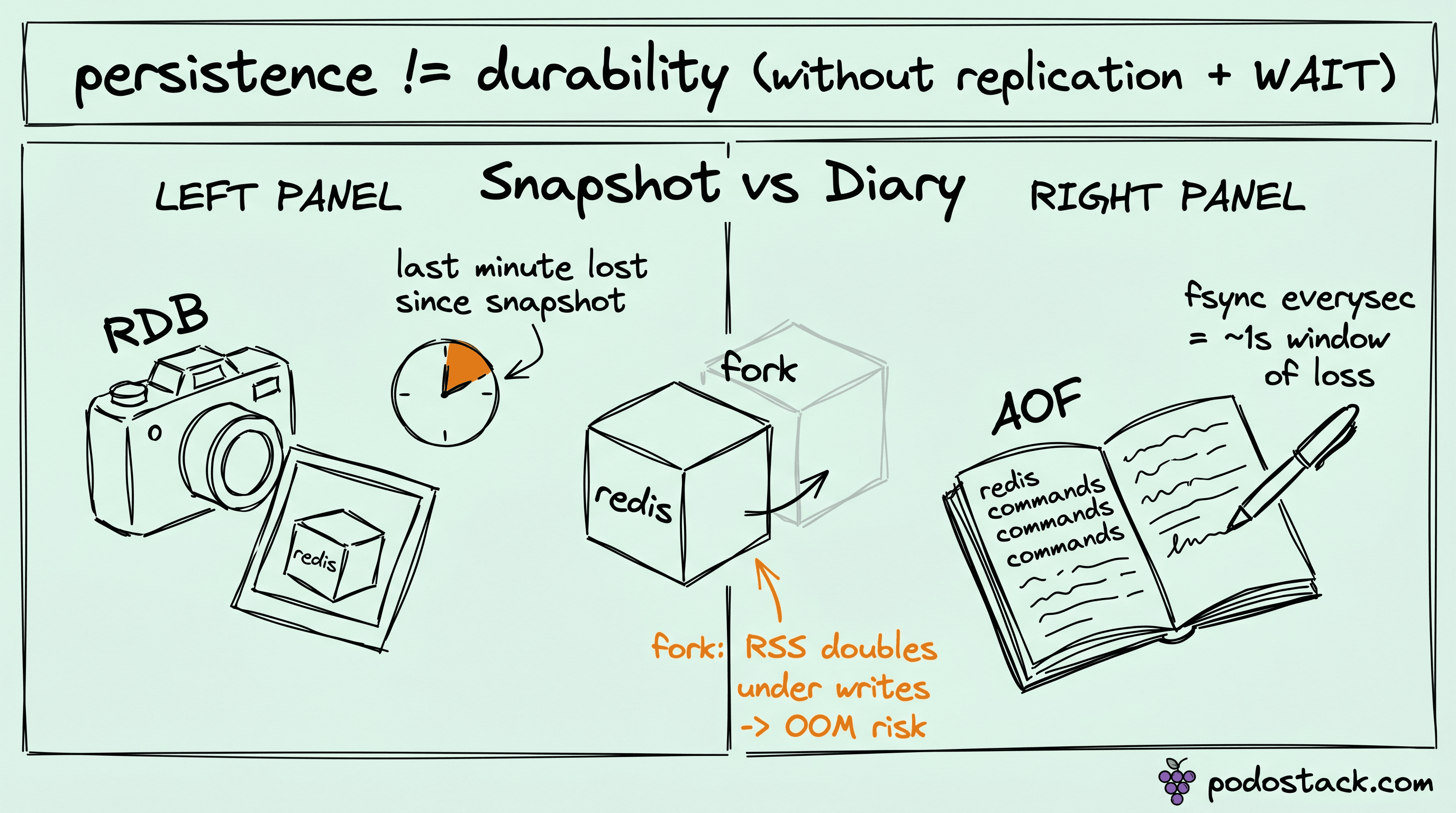
RDB: the snapshot that forks your whole heap
RDB works by fork(). When a save fires, the parent process forks a child, and the child writes the entire dataset to a temp file while the parent keeps serving traffic. The child sees a frozen copy of memory thanks to copy-on-write: parent and child share physical pages, and a page only gets duplicated when one of them writes to it.
That copy-on-write detail is the whole story for memory. On a read-mostly instance the fork is nearly free, because almost no pages change while the child writes. But under heavy writes the parent dirties pages fast, the kernel copies each dirtied page, and your resident memory climbs toward 2x the dataset. I've watched a 30 GB Redis with a busy write path balloon past 50 GB of RSS during a save and trip the cgroup limit. The kernel OOM killer doesn't care that the extra memory is transient. It picks the biggest process and kills it, which is your Redis, mid-snapshot.
Save points are configured as "after N seconds if at least M keys changed". The classic defaults fire roughly every 15 minutes on light churn and as often as every minute under load. Whatever the interval, the data-loss window is "everything since the last completed snapshot". Lose the process between saves and you lose that window. There's no log of the in-between writes, because RDB doesn't keep one.
The flip side is recovery. Loading an RDB file is fast: it's a compact binary dump, read sequentially, deserialized straight into the keyspace. A multi-gigabyte dataset comes back in seconds. If your priority is "get the cache warm again quickly after a restart" and you can tolerate losing a chunk of recent writes, RDB alone is defensible. Most people who reach for it haven't actually decided they can tolerate that loss, though. They just left it on.
AOF: the log that still loses a second
AOF logs every write command to a file as it happens. On restart Redis replays the log and rebuilds the exact state. That sounds like real durability, and it can be, but the durability lives entirely in one setting: appendfsync.
There are three values. With always, Redis calls fsync after every write, so a crash loses at most one command. It's also brutally slow, because you're paying a disk sync on the hot path of every single write, and throughput drops to a fraction of what the same box does otherwise. With no, Redis never explicitly fsyncs and leaves it to the OS, which on Linux means up to 30 seconds of buffered writes can vanish. The middle option, everysec, is the default and the one almost everyone runs: a background thread fsyncs once a second.
everysec is the setting people mean when they say "we have AOF, we're durable". What they actually have is a roughly one-second loss window. Crash at the wrong moment and the writes from the last second that hadn't been synced yet are gone. For a cache or a job queue that's usually fine. The trouble is nobody decided it was fine, they just inherited it, the same way we inherited those RDB save points.
AOF grows without bound, so Redis periodically rewrites it: it forks a child (yes, the same fork cost as RDB) that writes a compact version representing current state, then the parent appends any commands that arrived during the rewrite. So AOF doesn't escape the fork problem. A write-heavy instance pays the copy-on-write memory tax during every rewrite, not just during snapshots.
Recovery is where AOF hurts. Replaying a large AOF means re-executing millions of commands one at a time, in order, through the same command parser that handles live traffic. I've seen an AOF-only instance take several minutes to come back where an equivalent RDB loaded in seconds. If your dataset is large and your uptime SLO is tight, that replay time is a real operational cost, not a footnote. It also means a corrupt AOF can stall startup entirely: hit a truncated or malformed entry and Redis refuses to load until you run redis-check-aof --fix, which is exactly the tool you don't want to be learning about during an outage. The file that promised better durability is also the file with more ways to go wrong on the way back up.
The hybrid that papers over both
Modern Redis defaults to a hybrid that fixes the worst of each. With aof-use-rdb-preamble on, an AOF rewrite writes an RDB-format snapshot as the head of the file, then appends commands in AOF format after it. On restart Redis loads the RDB preamble fast, then replays only the commands logged since the last rewrite.
You get RDB's quick load and AOF's small loss window in one file. This is the sane default for most workloads, and if you're standing up a new instance it's where I'd start: appendonly yes, appendfsync everysec, RDB preamble on. It doesn't make the fork cost go away, and it doesn't make everysec lose less than a second. It just stops you from having to choose between fast recovery and a bounded loss window. You get both, with the caveats both carry.
The fork spike that looks like a dying node
The thing that pages people who never touch persistence config is the fork() itself, which is not free even with copy-on-write. The kernel has to copy the parent's page tables, and page-table size scales with how much memory the process maps. On a small instance the fork takes microseconds. On a 100 GB instance it can take hundreds of milliseconds, and during that time the parent process is blocked. Every command in flight waits.
That shows up in your metrics as a clean p99 jolt: median latency flat, tail latency spiking on a regular cadence that matches your save or rewrite schedule. The first time I saw it I spent an hour chasing GC pauses in the wrong service before noticing the spikes lined up exactly with the snapshot interval. Transparent huge pages make it worse, because each copied page-table entry covers more memory and the COW faults that follow are larger. Disabling THP for Redis is one of the few pieces of folklore that's actually right.
So persistence isn't just a durability question. The act of persisting is itself a latency event, and on a big instance it's the kind of latency event that wakes people up.
Why none of this is durability anyway
Step back from the file formats and the harder truth shows up: a single Redis node is never durable, whatever you set appendfsync to. The disk it writes to is the disk that dies. The host it runs on is the host that gets terminated. everysec bounds your loss to a second on a clean crash, but a clean crash isn't the interesting failure. Disk corruption, a yanked EBS volume, a node that vanishes mid-fsync, none of those respect the one-second promise.
Durability comes from replication, not from a file. You run replicas, writes propagate to them, and the data survives the loss of any one node. But default Redis replication is asynchronous, so a primary can acknowledge a write to your client and die before the replica ever sees it. The client thinks the write succeeded. It didn't survive.
The WAIT command is the tool that closes that gap. WAIT 1 100 blocks until at least one replica has acknowledged the write, or 100 milliseconds pass. It turns the async ack into something closer to a synchronous one, at the cost of the latency you'd expect. Even WAIT isn't a true quorum commit, and it won't save you from a simultaneous loss of primary and replica, but it's the difference between "the write reached one other machine" and "the write reached one machine's page cache". If you genuinely can't lose writes, persistence files are the wrong layer to be arguing about. Replication plus WAIT is the conversation, and even then Redis is a cache that can lose data, not a database that can't.
How I actually pick
I size the config to what I'd actually lose, not to what feels safe.
A pure cache that repopulates from a source of truth gets RDB alone, or no persistence at all. The last one of these I set up was a session cache backed by Postgres - if everything in it can be rebuilt, the loss window doesn't matter and the fast restart is what you want.
A job queue or session store, where a second of loss is annoying but survivable, is where the hybrid earns its keep: appendonly yes, everysec, RDB preamble on. Most workloads I've run land right here, and I've stopped second-guessing it.
When the data genuinely can't be lost, the file format stops being the question. I push back on that one every time it comes up. You need replicas, WAIT on the critical writes, and an honest look at whether Redis is even the right store.
And cutting across all of them is the big latency-sensitive instance, where I just watch the fork. Cap memory so a write-burst COW doubling can't OOM you, disable transparent huge pages, and if a single node is too big to fork cheaply, shard it before the page-table copy eats your tail latency.
The ones that keep catching people
A handful of these show up over and over once you start looking, and I've personally been burned by most.
Believing "persistence enabled" means "durable". It means there's a file on disk that's some amount of stale. The amount is the whole question, and the default answer is "up to a second, or up to your snapshot interval".
Then there's running RDB on a write-heavy instance with memory capped at the dataset size. The COW doubling during a save runs you straight into the OOM killer, mid-snapshot, which is the worst possible moment to lose the process.
Treating
appendfsync everysecas zero loss is the quiet one. It's a one-second window - fine for a cache, quietly wrong for anything you described to a stakeholder as durable.AOF-only with no thought for recovery time bites later: the replay of a large AOF is minutes, not seconds, and you find that out during the incident when you most want the node back.
Blame GC or the network for periodic p99 spikes that actually line up with the save schedule, and you'll spelunk in the wrong place for an hour. Overlay the snapshot interval on the latency graph first.
Assuming a replica makes you safe with async replication and no
WAIT. The primary can ack and die before the replica catches up. The write you were promised is the write you lost.Last, forgetting Valkey behaves identically. The fork is the same fork, the fsync is the same fsync. Switching projects doesn't change the physics, it just changes the license.
Persistence and durability sit one word apart in the docs and a whole incident apart in production. RDB tells you the dataset is safe and means "as of the last snapshot". AOF tells you every write is logged and means "give or take a second". The fork that does both can be the thing that takes your node down. Once you've internalized which lie each format tells, the config stops being a box you tick and starts being a decision you can defend at 3 a.m.