
UUID vs ULID: Why Your Primary Key Choice Is Killing Database Performance
Page splits, B-tree fragmentation, and the 10x I/O difference between random and sorted IDs

Every INSERT with a random UUID as primary key is a lottery ticket for a page split.
I didn’t understand this until I ran a load test on a table with 50 million rows. Writes were getting slower over time - not linearly, but in bursts. The monitoring showed disk I/O spikes every few seconds. I assumed it was the storage layer. It wasn’t. It was the B-tree reorganizing itself because my primary key was UUIDv4 - completely random.
Switching to ULID dropped write latency by 40% and cut I/O in half. Same data. Same hardware. Different primary key format. Here’s why.
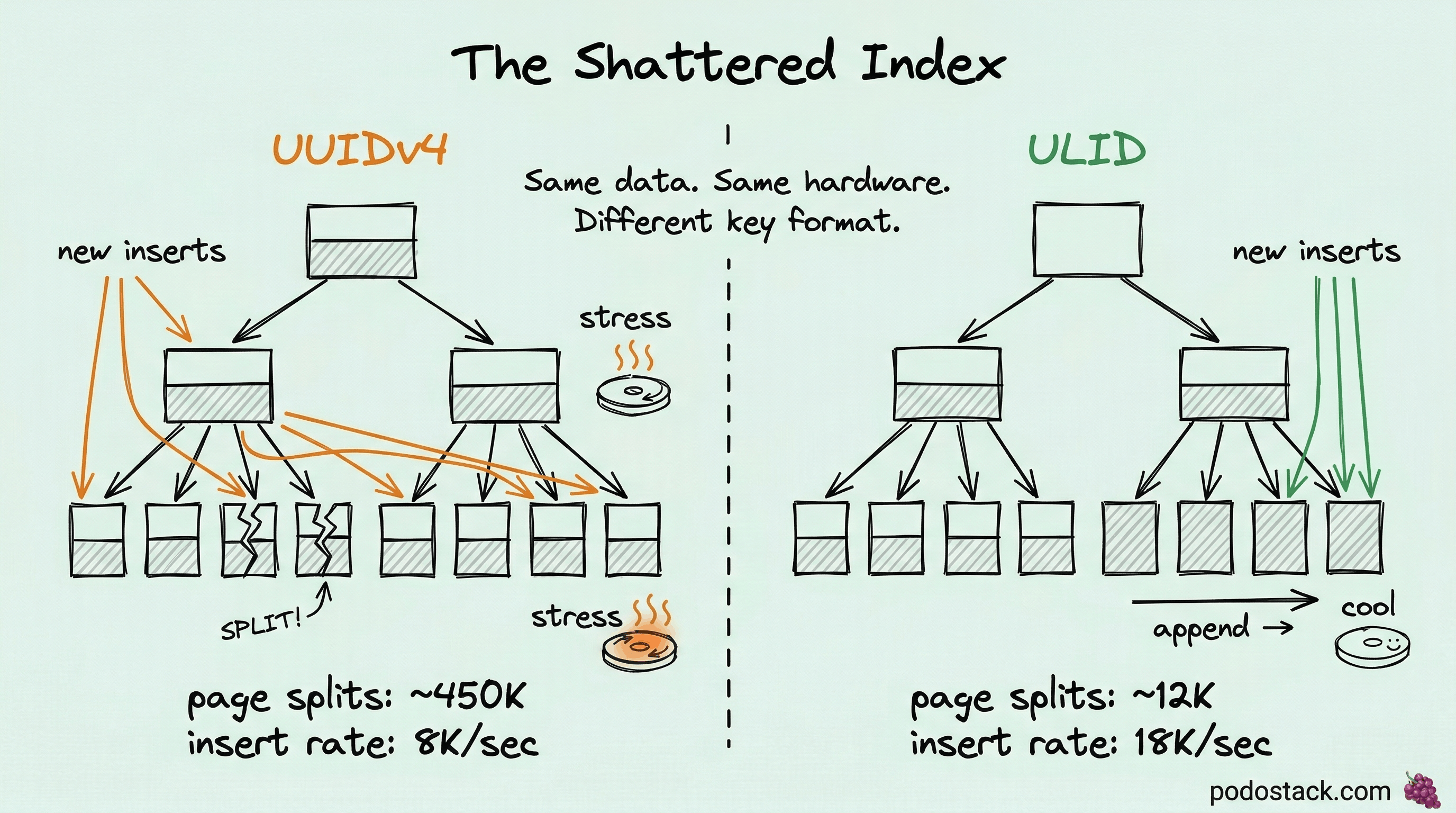
The problem: random keys shatter your index
InnoDB (MySQL) and most B-tree databases store rows in primary key order. The clustered index IS the table. When you insert a row, the database finds the right position in the B-tree and slots it in.
With auto-increment integers, new rows always go to the end of the tree. The last page gets filled up, a new page is allocated, and the old page is never touched again. Sequential. Predictable. Fast.
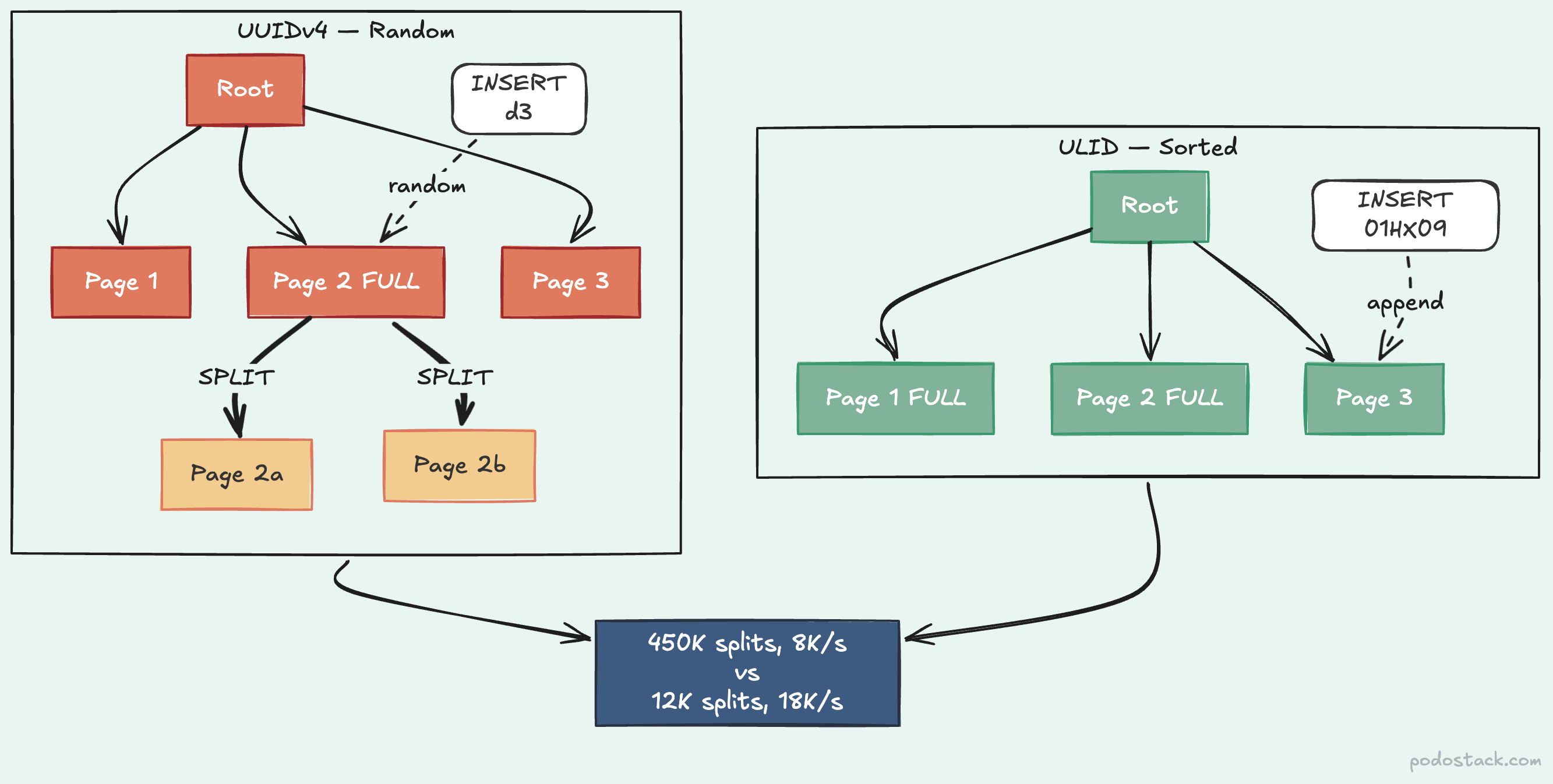
With UUIDv4, new rows go to random positions. The database has to find the right page somewhere in the middle of the tree. If that page is full, it splits - half the rows stay, half move to a new page, and the parent node gets updated. This is a page split. It’s expensive.
At 1 million rows with random UUIDs, page splits can account for 30-50% of all write I/O. The tree is constantly shuffling. Pages are half-full because of splits. The buffer pool is thrashing because random reads pull in pages from all over the disk.
Auto-increment: [1][2][3][4][5][6][7][8] → append to end
UUIDv4 (random): [a3][1f][d7][42][8b][c1] → insert everywhere, page splits
ULID (time-sorted): [01HX][01HX][01HY][01HY] → mostly append, rare splitsWhat is ULID?
ULID stands for Universally Unique Lexicographically Sortable Identifier. It’s 128 bits, just like UUID. But the first 48 bits are a millisecond-precision timestamp, and the remaining 80 bits are random.
ULID structure (128 bits):
|---- timestamp (48 bits) ----|------- random (80 bits) -------|
01HX9N0DQYP 5R3YWBKJZM7E2G
UUID v4 structure (128 bits):
|---------------- all random (122 bits + 6 version bits) -------|
550e8400-e29b-41d4-a716-446655440000Because the timestamp comes first, ULIDs generated in the same millisecond sort together, and ULIDs generated later sort after earlier ones. The B-tree sees mostly sequential inserts - new rows append near the end instead of scattering across the tree.
You still get uniqueness (80 random bits = 1.2 x 10^24 possible values per millisecond). You still get decentralized generation (no coordination needed). But you also get sort order for free.
Storage: stop using CHAR(36)
Both UUID and ULID are 128 bits. How you store them matters.
UUID as CHAR(36): 37 bytes per row — 370 MB for 10M rows
ULID as CHAR(26): 27 bytes per row — 270 MB for 10M rows
Either as BINARY(16): 16 bytes per row — 160 MB for 10M rows
That’s the primary key column alone. Every secondary index also stores a copy of the primary key. If you have 5 indexes, CHAR(36) costs you 5 x 370 MB = 1.85 GB vs 5 x 160 MB = 800 MB for BINARY(16). At scale, this difference in index size affects how much fits in the buffer pool, which affects how many disk reads your queries need.
For UUID in MySQL, use UUID_TO_BIN with the swap flag:
CREATE TABLE orders (
id BINARY(16) PRIMARY KEY,
-- other columns
);
-- Insert
INSERT INTO orders (id) VALUES (UUID_TO_BIN(UUID(), 1));
-- Select (human-readable)
SELECT BIN_TO_UUID(id, 1) AS id FROM orders;The swap flag (1) rearranges UUIDv1 bytes so the timestamp portion comes first, improving sort order. For UUIDv4 it doesn’t help with ordering (still random) but it’s a good habit.
For ULID, generate in your application and pack into BINARY(16):
import ulid
# Generate ULID
new_id = ulid.new()
# Store as 16 bytes
binary_value = new_id.bytes # bytes, length 16
# For display
print(str(new_id)) # "01HX9N0DQYP5R3YWBKJZM7E2G"The benchmarks
On a MySQL 8.0 test with 10 million inserts, single-threaded:
Insert rate: UUIDv4 CHAR(36) ~8,000/sec · UUIDv4 BINARY(16) ~12,000/sec · ULID BINARY(16) ~18,000/sec
Page splits: ~450K · ~420K · ~12K
Final table size: 4.2 GB · 2.1 GB · 1.9 GB
Buffer pool hit rate: 74% · 82% · 96%
ULID in BINARY(16) inserts 2.25x faster than UUIDv4 in CHAR(36). Page splits drop by 97%. The buffer pool hit rate jumps because sequential access means the database reads ahead correctly.
These numbers will vary by hardware, concurrency, and row size. But the trend is consistent: time-sorted keys dramatically outperform random keys in B-tree indexes.
What about UUIDv7?
UUID version 7 (RFC 9562, finalized in 2024) solves the same problem as ULID - it puts a Unix timestamp in the most significant bits. If your ecosystem has native UUIDv7 support, it’s a perfectly valid alternative to ULID.
The practical differences are minor:
Timestamp precision: both millisecond (48 bits)
Random bits: ULID 80 · UUIDv7 62
String format: ULID 26 chars (Crockford Base32) · UUIDv7 36 chars (hex with dashes)
Ecosystem support: ULID has libraries in most languages · UUIDv7 growing, native DB support coming
Monotonic within ms: both optional (library/RFC-dependent)
Both solve the page split problem. Pick whichever your stack supports better. If you’re starting fresh and can choose, ULID’s 26-character string is shorter and URL-friendlier. If you need to stay compatible with UUID-expecting systems, UUIDv7 drops right in.
Migration path
If you’re sitting on a table with millions of UUIDv4 primary keys, don’t panic. A full migration is rarely worth the downtime. Instead:
For new tables: Start with ULID or UUIDv7 in BINARY(16). No legacy to worry about.
For existing tables with UUIDv4 CHAR(36): Add a BINARY(16) column, backfill with UUID_TO_BIN, swap the primary key during a maintenance window. This cuts storage and improves buffer pool efficiency even without changing the ID format.
For existing tables with UUIDv4 where performance matters: Consider a surrogate auto-increment primary key with the UUID as a unique secondary index. The clustered index becomes sequential again. The UUID is still there for external references.
ALTER TABLE orders
ADD COLUMN pk BIGINT AUTO_INCREMENT,
DROP PRIMARY KEY,
ADD PRIMARY KEY (pk),
ADD UNIQUE INDEX idx_uuid (id);This is the nuclear option - it changes your table structure significantly. But for tables where insert performance is critical and you can’t change the ID format, it works.
Quick decision guide
Use auto-increment when you don’t need distributed ID generation and the IDs don’t leave your database.
Use ULID when you need distributed, sortable, unique IDs. Best for: event logs, time-series adjacent tables, any table where you regularly query by creation time.
Use UUIDv7 when you need UUID compatibility with time-ordering. Best for: systems that already expect UUID format, APIs with UUID contracts.
Use UUIDv4 when sort order genuinely doesn’t matter and you need maximum collision resistance. Best for: tokens, session IDs, anything where randomness is a feature, not a bug.
Never use CHAR(36) for storing any of these in a database. BINARY(16) always.
Found this useful? Subscribe to Podo Stack for weekly data engineering patterns and Cloud Native tools ripe for production.
How does your team handle primary keys? Still on auto-increment, or have you made the jump to ULID/UUIDv7? I’d love to hear what works in your setup.