
Change Data Capture: Stop Copying 50M Rows to Move 5K Changes
Three CDC methods compared - timestamps, triggers, and log-based - with trade-offs and real examples

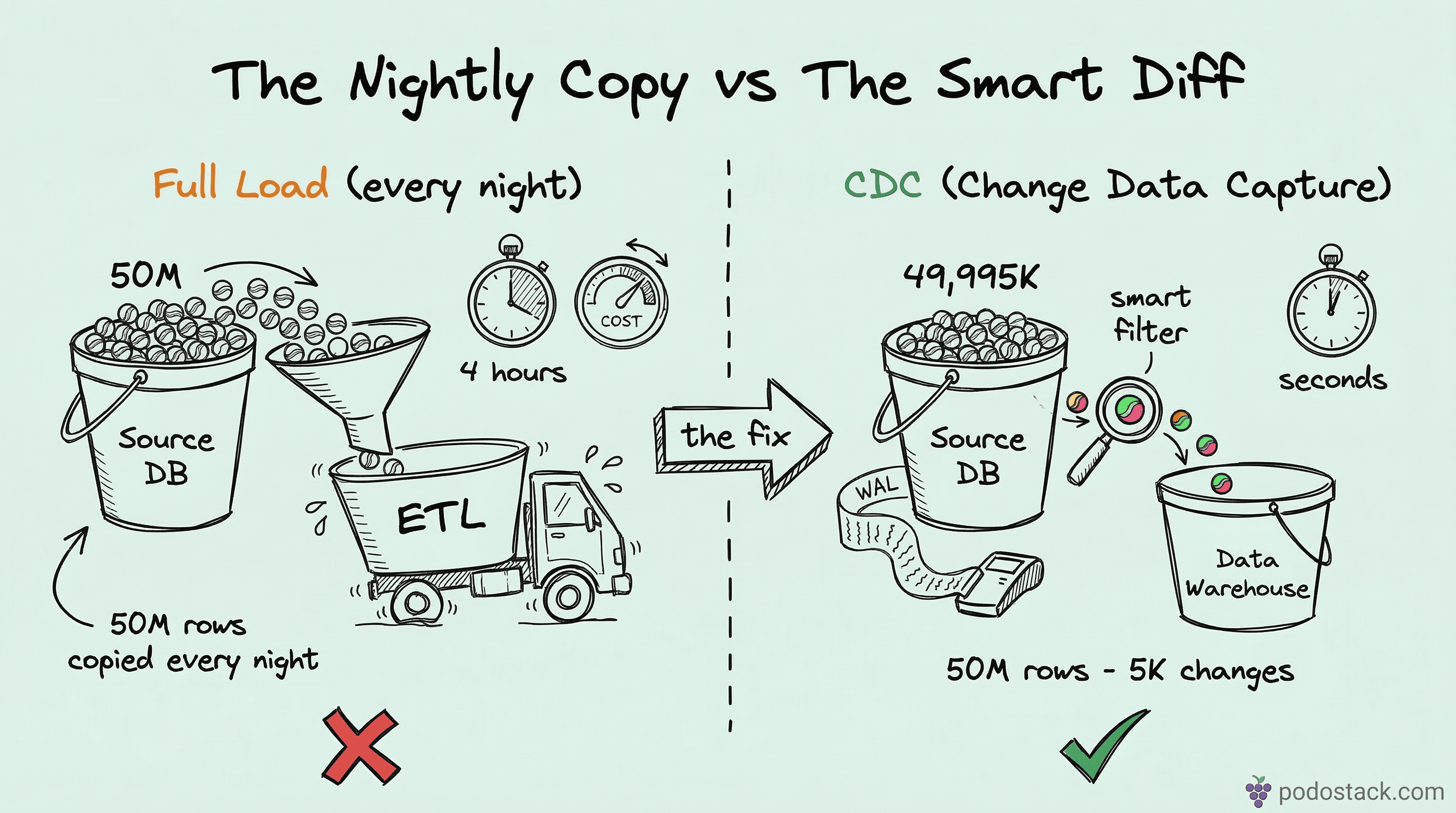
Your ETL copies 50 million rows every night. Only 5,000 changed. The other 49,995,000 rows are identical to yesterday. You’re burning compute, network, and storage to move data that hasn’t moved.
I’ve seen this pattern at three different companies. The nightly batch job runs for 4 hours, the data warehouse is “fresh” by 6 AM, and everyone accepts this as normal. It isn’t. Change Data Capture (CDC) exists specifically to solve this - track only what changed, move only the deltas. The difference between copying a full table and streaming 5K changes is the difference between hauling the entire library and borrowing one book.
What CDC actually does
CDC captures INSERT, UPDATE, and DELETE events as they happen (or shortly after) and delivers them downstream. Instead of asking “what does the table look like right now?” you ask “what changed since last time I checked?”
The result is the same - your target stays in sync with the source. But the cost drops dramatically. Less data transferred, less compute on both sides, and the target can be minutes behind the source instead of hours.
There are three main approaches, each with different trade-offs.
Method 1: Timestamp-based
The simplest form. Add created_at and updated_at columns to your table, then query for rows modified since the last sync.
-- Source table
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
status VARCHAR(20),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
-- CDC query: get everything that changed since last run
SELECT *
FROM orders
WHERE updated_at > '2026-03-07 00:00:00';Your ETL runs this query every 15 minutes, processes the results, and records the latest updated_at as the watermark for the next run.
Pros: Dead simple. No special infrastructure. Works with any database. You can implement it in an afternoon.
Cons: It misses hard deletes. If someone runs DELETE FROM orders WHERE id = 42, there’s no row left to have an updated_at. The row just disappears, and your target never finds out. You’d need a soft-delete pattern (is_deleted flag) or periodic full reconciliation to catch these.
It also struggles with bulk updates that don’t touch the timestamp column. If someone does ALTER TABLE orders ADD COLUMN priority INT DEFAULT 0, every row now has the same value but updated_at didn’t change. Schema changes are invisible.
Good for: simple sync scenarios where deletes are rare and you control the source schema.
Method 2: Trigger-based
Database triggers fire on every INSERT, UPDATE, and DELETE and write the change to a shadow table.
-- Shadow table to capture changes
CREATE TABLE orders_changes (
change_id BIGSERIAL PRIMARY KEY,
operation CHAR(1), -- 'I', 'U', 'D'
changed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
order_id BIGINT,
customer_id INT,
amount DECIMAL(10,2),
status VARCHAR(20)
);
-- Trigger function (PostgreSQL)
CREATE OR REPLACE FUNCTION capture_order_changes()
RETURNS TRIGGER AS $$
BEGIN
IF TG_OP = 'DELETE' THEN
INSERT INTO orders_changes (operation, order_id, customer_id, amount, status)
VALUES ('D', OLD.id, OLD.customer_id, OLD.amount, OLD.status);
RETURN OLD;
ELSE
INSERT INTO orders_changes (operation, order_id, customer_id, amount, status)
VALUES (
CASE WHEN TG_OP = 'INSERT' THEN 'I' ELSE 'U' END,
NEW.id, NEW.customer_id, NEW.amount, NEW.status
);
RETURN NEW;
END IF;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER orders_cdc_trigger
AFTER INSERT OR UPDATE OR DELETE ON orders
FOR EACH ROW EXECUTE FUNCTION capture_order_changes();Your ETL reads from orders_changes, processes the deltas, and deletes or marks the consumed rows.
Pros: Catches everything - inserts, updates, and deletes. No row is missed. You get the before and after state if you capture both OLD and NEW.
Cons: Triggers are synchronous. Every INSERT INTO orders now also does an INSERT INTO orders_changes within the same transaction. On a table with 10,000 writes per second, that’s 10,000 extra inserts. Your OLTP workload just got heavier.
Triggers are also database-specific. The PostgreSQL trigger above won’t work on MySQL or SQL Server. You’re writing and maintaining CDC logic per database engine. And triggers can be fragile - they silently break when someone alters the table structure without updating the trigger.
Good for: moderate-write workloads where you need to catch deletes and don’t want external tooling.
Method 3: Log-based (the gold standard)
Every transactional database maintains a write-ahead log (WAL in PostgreSQL, binlog in MySQL, redo log in Oracle, transaction log in SQL Server). This log records every change before it hits the actual data files. It’s how databases survive crashes - replay the log, recover the state.
Log-based CDC reads this log directly. No queries against the table, no triggers, no impact on OLTP performance. The log is already being written - CDC just tails it.
PostgreSQL WAL → Debezium → Kafka → your data warehouse
MySQL binlog → Debezium → Kafka → your data warehouse
SQL Server CDC → Fivetran → SnowflakeDebezium is the most popular open-source tool for this. It connects to the database’s replication slot (PostgreSQL) or binlog (MySQL), reads every committed transaction, and produces change events as JSON:
{
"op": "u",
"before": {"id": 42, "status": "pending", "amount": 99.99},
"after": {"id": 42, "status": "shipped", "amount": 99.99},
"source": {
"db": "production",
"table": "orders",
"ts_ms": 1709827200000
}
}You get the operation type (c = create, u = update, d = delete, r = read/snapshot), the before state, the after state, and metadata about where the change came from. Everything you need to replay the change downstream.
Pros: Asynchronous - zero impact on OLTP performance. Catches everything including DDL changes. Near real-time (seconds of latency, not hours). Works at any scale because you’re reading a sequential log, not scanning a table.
Cons: More infrastructure to run. Debezium needs Kafka (or Kafka Connect), you need to manage connectors, handle schema evolution, monitor lag. It’s not an afternoon project.
The database also needs to be configured for logical replication (PostgreSQL) or row-based binlog (MySQL). In managed services like RDS or Cloud SQL, this is usually a checkbox. On-premise, it might mean changing database parameters and restarting.
Good for: anything in production. If you’re serious about keeping a data warehouse or downstream service in sync, log-based CDC is the answer.
Comparing the three
Timestamp-based: Doesn’t catch deletes. Adds query load to OLTP. Minutes of latency. Low setup complexity. Can’t catch DDL changes. Medium scale ceiling. Tools: any SQL client.
Trigger-based: Catches deletes. Adds write overhead. Seconds of latency. Medium complexity. Can’t catch DDL. Medium scale ceiling. Tools: DB-native triggers.
Log-based: Catches deletes. Zero OLTP impact. Seconds of latency. High setup complexity. Catches DDL changes. High scale ceiling. Tools: Debezium, Fivetran, Striim.
CDC and Slowly Changing Dimensions
If you’re building a data warehouse, CDC pairs naturally with Slowly Changing Dimensions. CDC tells you what changed. SCD defines how to store that change in your dimension tables.
A Type 2 SCD workflow with log-based CDC looks like this:
Debezium captures an update: customer moved from New York to Austin
Your ETL receives the change event
It closes the current dimension row (
valid_to = today,is_current = false)It inserts a new row for the Austin version (
valid_from = today,is_current = true)
Without CDC, you’d scan the entire customer table every night to detect this one address change. With CDC, the change arrives within seconds and your dimension is always current.
Getting started
If you’re running on timestamp-based sync and it works - don’t fix what isn’t broken. Add it to your migration backlog and prioritize based on pain.
If you’re feeling the pain - stale data, missed deletes, long batch windows - here’s the progression:
Start with timestamp-based if you just need to prototype. Add
updated_atcolumns, write a simple sync script, validate the approach.Move to log-based when you need reliability. Set up Debezium with Kafka Connect, point it at your database, and let it stream changes. Skip the trigger phase - it adds complexity without the benefits of log-based CDC.
Monitor lag. CDC is only useful if the stream keeps up with the source. Track consumer lag in Kafka, alert on it, and scale consumers if needed.
The tools are mature. Debezium has been in production at thousands of companies for years. Fivetran and Striim handle the infrastructure for you if you don’t want to run Kafka yourself. The hard part isn’t the tooling - it’s deciding to stop copying 50 million rows when you only need 5,000.
Found this useful? Subscribe to Podo Stack for weekly data engineering patterns and Cloud Native tools ripe for production.
Already using CDC in production? Still on nightly batch ETL? I’d love to hear what your setup looks like - reply to this email or leave a comment.
Useful article, thanks. Your point about Debezium needing Kafka is not quite right - check out Debezium Server (https://debezium.io/documentation/reference/stable/operations/debezium-server.html).