
Tools From the Future
Dapr distributed runtime, Kargo GitOps promotion, WasmEdge vs containers, Koordinator scheduling, and OpenFeature

Welcome back to Podo Stack. This week: five tools that feel like they’re from the future. A runtime that abstracts away infrastructure. A GitOps promotion engine by the Argo CD team. WebAssembly challenging containers. A scheduler that squeezes real money out of idle nodes. And a CNCF standard that makes feature flags vendor-neutral.
Here’s what’s good this week.
🚀 Sandbox Watch: Dapr - The Standard Library for Microservices
The problem
You’re building microservices. Every service needs state management, pub/sub, service discovery, secrets, and retries. So you import SDKs - one for Redis, one for Kafka, one for Vault, one for your cloud provider’s queue. Suddenly, your business logic is buried under infrastructure glue code. And switching from RabbitMQ to Kafka? That’s a rewrite.
The solution
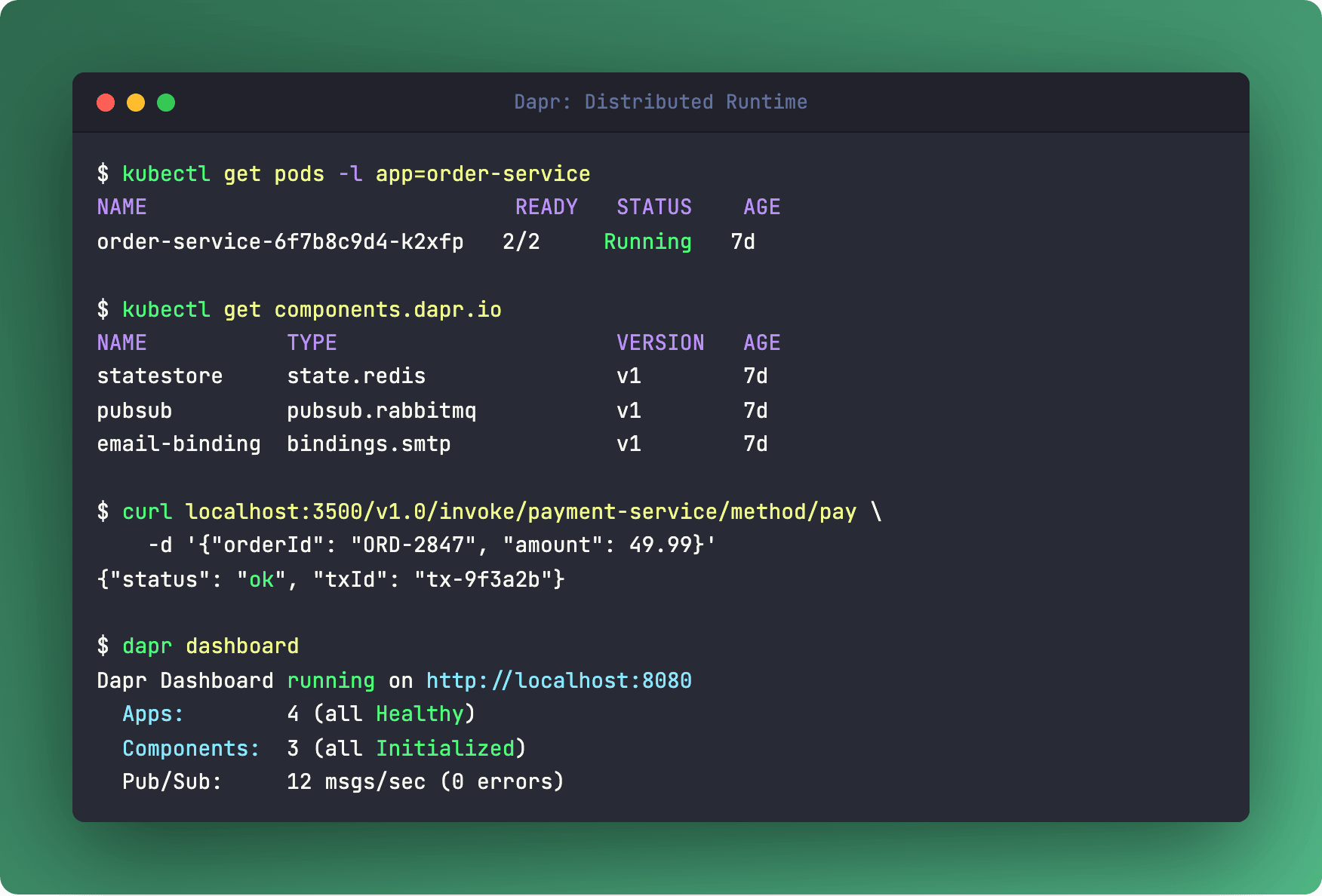
Dapr (Distributed Application Runtime) runs as a sidecar next to your app and exposes all those patterns through simple HTTP/gRPC APIs. Need to save state? POST /v1.0/state/mystore. Publish an event? POST /v1.0/publish/mytopic. Invoke another service? POST /v1.0/invoke/service-b/method/checkout.
Your code doesn’t know (or care) whether the state store is Redis, PostgreSQL, or CosmosDB. That’s a YAML config swap, not a code change.
Started at Microsoft, now a CNCF Incubating project. The building blocks cover the greatest hits of distributed systems: service invocation with mTLS, state management, pub/sub, input/output bindings, actors, and distributed lock.
What it’s NOT
Dapr isn’t a service mesh. Istio and Linkerd handle L7 traffic routing and network policies. Dapr handles application-level concerns - state, events, secrets. They’re complementary. You can run both. In fact, if you’re already on Cilium for networking, Dapr slots right in on top.
The catch
The sidecar adds latency - a few milliseconds per call. For most microservices, that’s nothing. For ultra-low-latency trading systems, it’s a dealbreaker. Also, debugging gets trickier when every call goes through a sidecar. Good observability (Dapr exports OpenTelemetry traces by default) helps, but it’s still another moving part.
Links
💎 Hidden Gem: Kargo - GitOps Finally Gets Promotion Right
GitOps has a dirty secret: nobody agrees on how to promote changes between environments. You’ve got Argo CD syncing your clusters from Git. Beautiful. But who updates that Git repo when a new image passes staging tests? A janky CI script, that’s who.
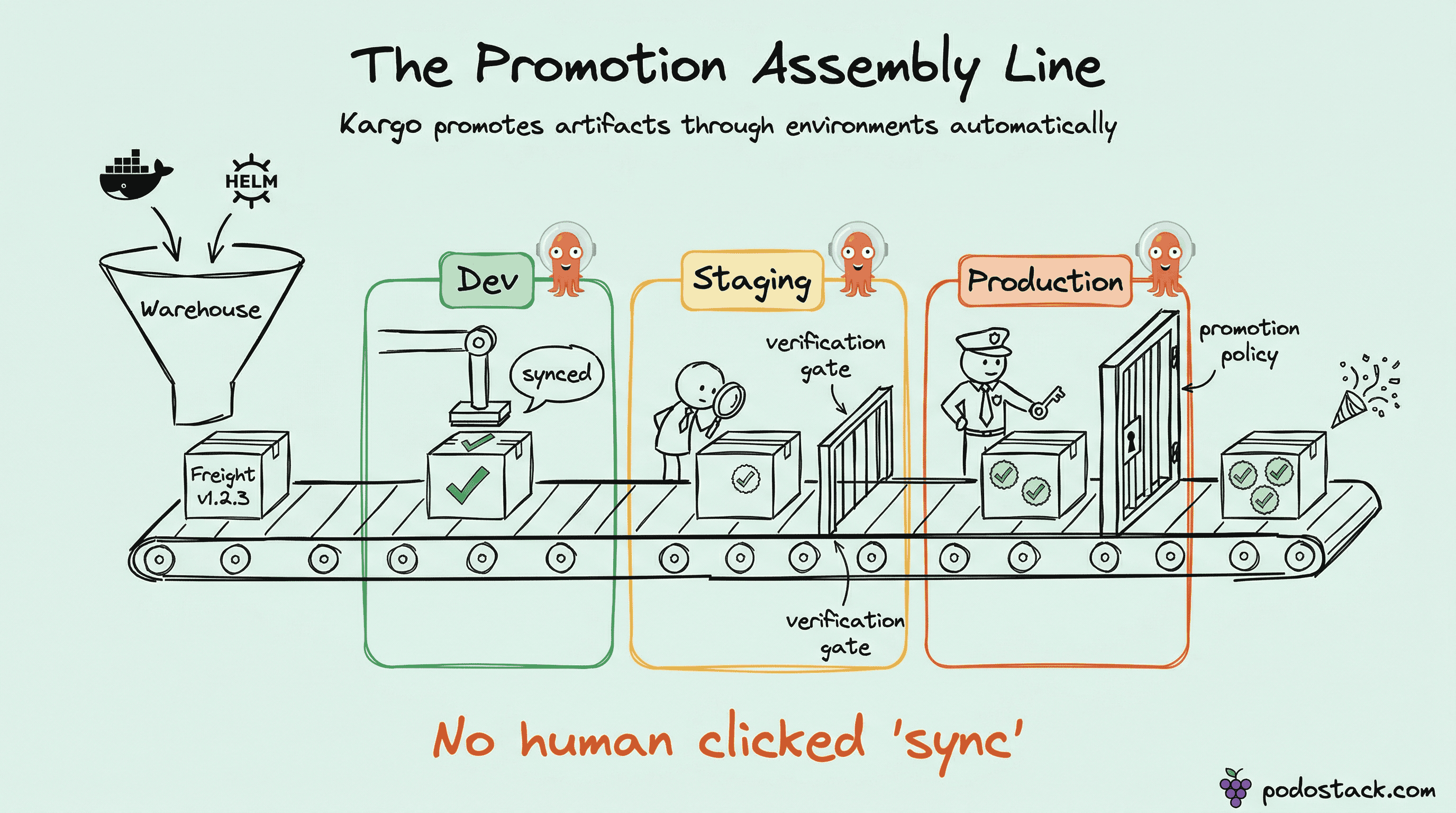
Enter Kargo
Built by the creators of Argo CD (yes, the same team), Kargo is purpose-built for continuous promotion. It introduces four concepts that make the whole thing declarative:
Warehouse - watches for new artifacts (Docker tags, Helm chart versions, Git commits)
Freight - a specific bundle of artifacts, like
myapp:v1.2.3+chart:0.5.0Stage - represents an environment (dev, staging, prod)
Promotion - the act of moving Freight from one Stage to the next
The flow: Warehouse detects a new image tag. Creates Freight. Auto-promotes to dev. Dev passes verification. Kargo shows a “Promote to Staging” button in its UI. QA clicks it. Kargo updates the Git repo. Argo CD syncs. Done.
No shell scripts. No sed -i in CI pipelines. No “who changed that image tag in the values.yaml?”
Why it matters
If you adopted Crossplane for infrastructure-as-code and Argo CD for deployment, Kargo closes the last gap. It’s the missing piece between “CI built a new image” and “that image is running in production.”
Links
⚔️ The Showdown: WasmEdge vs Containers
Solomon Hykes (Docker’s co-founder) tweeted it back in 2019: “If WASM+WASI existed in 2008, we wouldn’t have needed Docker.” Bold claim. Let’s see where we are.

WasmEdge is a CNCF Incubating runtime for server-side WebAssembly. It compiles Wasm modules ahead-of-time to near-native speed. And the numbers are hard to ignore.
Containers:
Cold start: seconds
Image size: 100s of MB
Isolation: Linux namespaces + cgroups
Language support: anything that runs on Linux
Ecosystem: massive, battle-tested
WasmEdge:
Cold start: milliseconds
Module size: single-digit MBs
Isolation: Wasm sandbox (no syscalls by default)
Language support: Rust, C/C++, Go (TinyGo), JS, Python (growing)
Ecosystem: early but expanding fast
The verdict
It’s not either/or. Wasm shines for edge computing, serverless functions, and plugin systems where you need thousands of isolated instances with instant startup. Containers win for complex apps with deep OS dependencies, mature debugging tools, and the massive Docker Hub ecosystem.
The practical move today: use containers for your main workloads. Explore WasmEdge for FaaS, edge processing, and SaaS plugin sandboxing. Kubernetes already supports both through OCI-compatible runtimes like crun.
Links
🔬 The Pattern: Koordinator - Make Idle CPUs Pay Rent
The problem
Your Kubernetes nodes are 15-20% utilized. You’re paying for 100% of them. The scheduler sees requested resources, not actual usage. So those 80% “reserved but idle” CPUs just sit there, burning money.
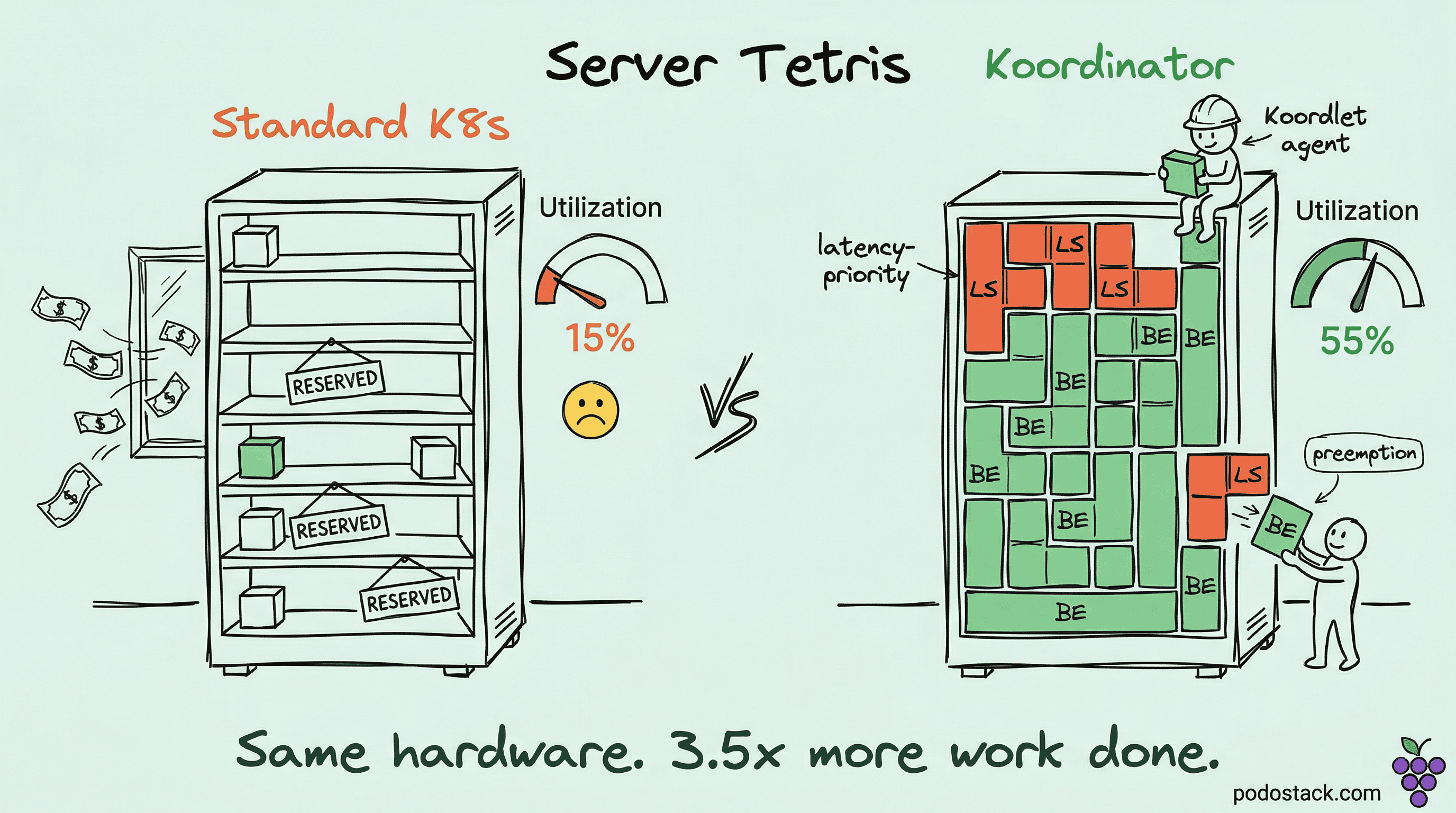
The fix
Koordinator, from Alibaba and now a CNCF project, introduces colocation - running best-effort (BE) batch jobs on the resources your latency-sensitive (LS) services reserved but aren’t using.
The key: when the LS service actually needs those resources back, Koordinator’s node agent (Koordlet) instantly throttles or evicts the BE workloads. No performance degradation for your production services. It monitors real-time metrics - CPU cycles per instruction, cache contention, memory bandwidth - and reacts in milliseconds.
The isolation goes deeper than standard cgroups. Koordinator manages LLC (Last Level Cache) allocation and memory bandwidth to prevent “noisy neighbor” problems at the hardware level.
Real numbers
Alibaba reports going from ~15% to 50%+ cluster utilization in production. That’s not a rounding error. On a 1000-node cluster, that’s potentially hundreds of nodes you don’t need to buy.
The catch
This isn’t plug-and-play. You need a solid understanding of Linux kernel scheduling, NUMA topology, and your workload patterns. It’s a power tool for platform teams that have already outgrown basic Kubernetes resource management.
Links
🛠️ One-Liner: OpenFeature - Feature Flags Without Vendor Lock-in
Feature flags are everywhere. But every provider (LaunchDarkly, Flagsmith, Split, PostHog) has its own SDK. Switch providers, rewrite your integration code. Sound familiar?
OpenFeature is a CNCF standard that does for feature flags what OpenTelemetry did for observability: one API, swap the backend anytime.
client := openfeature.NewClient("my-app")
enabled, _ := client.BooleanValue(ctx, "new-checkout", false, evalCtx)That code works with LaunchDarkly today and Flagsmith tomorrow. You change one line - the provider initialization - not the hundreds of flag checks scattered through your codebase. SDKs exist for Go, Java, Python, TypeScript, .NET, PHP, and more.
Links
🔥 The Hot Take: Cloud-Native Is Accelerating, Not Stabilizing
Look at this week’s tools. Dapr abstracts distributed patterns into HTTP calls. Kargo makes GitOps promotion declarative. WasmEdge challenges the container model itself. Koordinator squeezes 3x more value from existing hardware. OpenFeature standardizes yet another fragmented space.
Five years ago, we were still arguing about whether Kubernetes was production-ready. Now we’re building abstraction layers on top of abstraction layers - and they’re actually good. The CNCF landscape isn’t just growing, it’s maturing into composable building blocks.
My take: the teams that win in 2026 aren’t the ones running the most tools. They’re the ones picking the right abstractions early. One good choice (like adopting OpenTelemetry in 2022) saves years of migration pain later.
What’s your bet? Reply and tell me which tool here you’d adopt first.
Questions? Feedback? Reply to this email. I read every one.