
Prefix Indexes: Stop Indexing 255 Characters When 16 Is Enough
When VARCHAR(255) is in the WHERE clause but only the first 16 characters matter

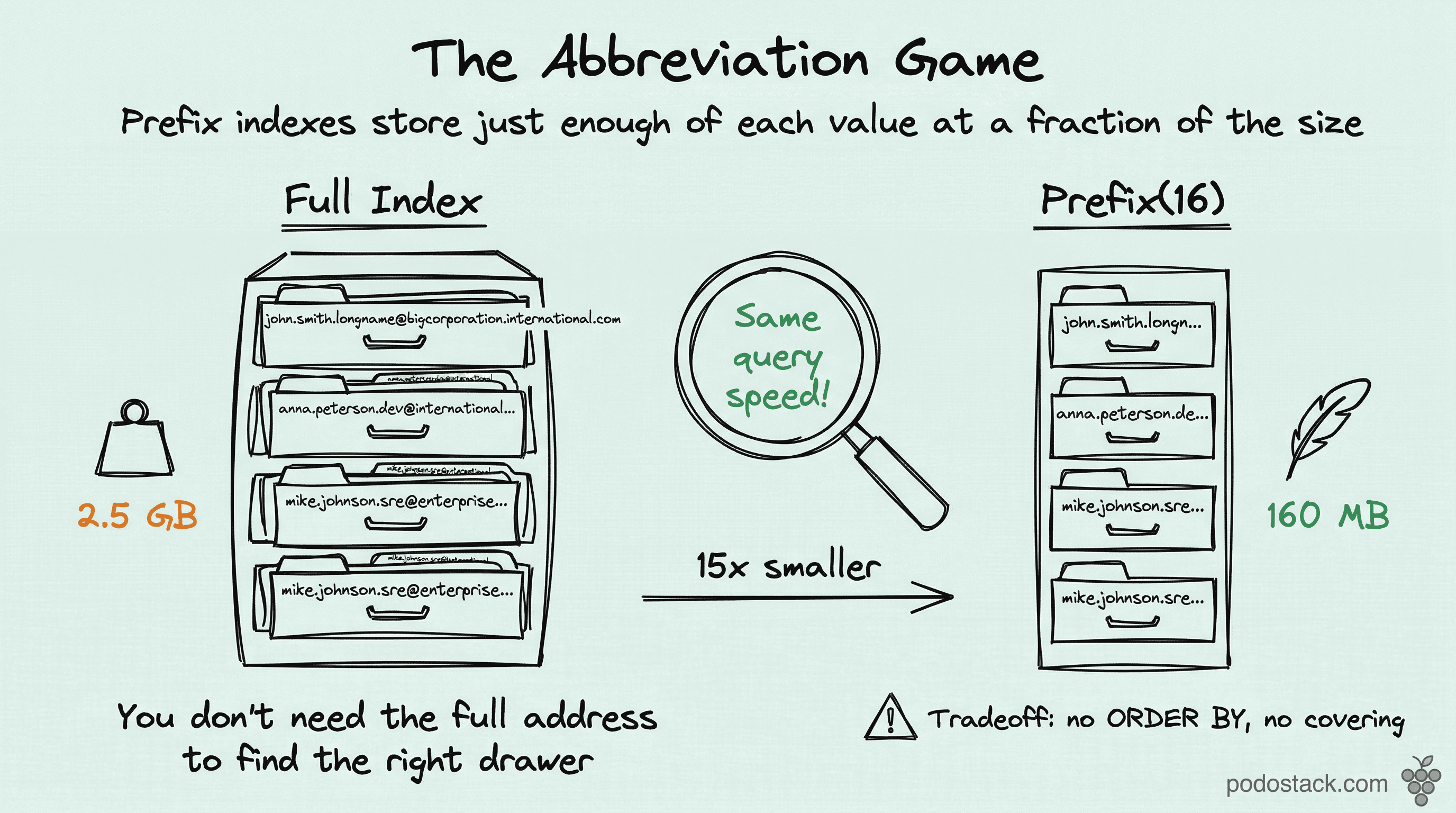
Your VARCHAR(255) column has an index. That index stores every byte of every value. For 10 million rows of email addresses, that’s roughly 2.5GB of index data.
But here’s the thing - most email lookups match on the first 12-16 characters. The rest of the string is dead weight in the index. You’re paying storage and memory for bytes the query optimizer never needs.
Prefix indexes fix this. Instead of indexing the full string, you index only the first N characters. The index shrinks by 5-10x. Queries stay fast. And your InnoDB buffer pool stops wasting RAM on index pages that don’t earn their keep.
The syntax
It’s one keyword away from a regular index:
CREATE INDEX idx_email_prefix ON users (email(16));That (16) tells MySQL: store only the first 16 characters. For a VARCHAR(255) column, that’s roughly 6% of the maximum length. The index is dramatically smaller.
You can do this on CREATE TABLE or as an ALTER TABLE. Works on VARCHAR, CHAR, TEXT, BLOB - any string type.
Choosing the right prefix length
Too short and the index isn’t selective enough - too many rows share the same prefix, so MySQL still scans thousands of entries. Too long and you lose the size benefit.
The trick is measuring selectivity. You want the prefix that captures most of the uniqueness:
-- Full column selectivity (baseline)
SELECT COUNT(DISTINCT email) / COUNT(*) AS full_selectivity
FROM users;
-- Test different prefix lengths
SELECT
COUNT(DISTINCT LEFT(email, 8)) / COUNT(*) AS sel_8,
COUNT(DISTINCT LEFT(email, 12)) / COUNT(*) AS sel_12,
COUNT(DISTINCT LEFT(email, 16)) / COUNT(*) AS sel_16,
COUNT(DISTINCT LEFT(email, 20)) / COUNT(*) AS sel_20
FROM users;If full selectivity is 0.98 and LEFT(email, 16) gives you 0.95 - that’s close enough. You’re keeping 97% of the uniqueness at 6% of the size.
A rule of thumb: aim for 90-95% of full-column selectivity. Beyond that, you’re paying more storage for diminishing returns.
Where prefix indexes shine
The sweet spot is long strings with high uniqueness at the front:
Email addresses -
user@is usually unique enough in the first 16 charsURLs -
https://example.com/pathdiverges earlyUUIDs stored as VARCHAR - the first 8 characters of a UUID v4 give strong selectivity
File paths -
/data/region/tenant/...branches early in the treeJSON string fields - when you’re filtering on a text column that holds serialized data
For columns like country_code (2 chars) or status (5-10 chars), prefix indexes don’t make sense - just index the full column.
Composite indexes with prefixes
You can mix prefix and full columns in a composite index:
CREATE INDEX idx_type_email ON users (account_type, email(16));MySQL uses account_type fully, then narrows within each type using the email prefix. This is powerful for queries like WHERE account_type = 'business' AND email LIKE 'john%'.
The trade-offs
No ORDER BY optimization. MySQL can’t use a prefix index for sorting. ORDER BY email won’t benefit from email(16) - the optimizer doesn’t know the full order. If you need sorted results, you need the full-column index.
No covering index. A prefix index can’t “cover” a query because it doesn’t store the complete value. If your query is SELECT email FROM users WHERE email LIKE 'john%', MySQL still has to look up the full row to return the complete email. Pair this with a covering index if you need both.
No exact UNIQUE constraint. A prefix index on email(16) can’t enforce uniqueness on the full email - two different emails might share the same 16-character prefix. If you need uniqueness, keep a full UNIQUE index alongside the prefix index for queries.
UTF-8 prefix length is in characters, not bytes. In utf8mb4, one character can take up to 4 bytes. email(16) means 16 characters, which could be up to 64 bytes. This matters for index size calculations if your data has multi-byte characters.
Prefix indexes in PostgreSQL
PostgreSQL doesn’t support prefix indexes directly - there’s no CREATE INDEX ... (column(N)) syntax. But you get the same result with a functional index:
CREATE INDEX idx_email_prefix ON users (LEFT(email, 16));Your queries need to use the same expression: WHERE LEFT(email, 16) = LEFT('john@example.com', 16). It’s less ergonomic than MySQL’s approach, but the performance benefit is identical.
Honestly, for PostgreSQL, partial indexes often solve the same underlying problem - a large index where most entries aren’t useful - through a different mechanism.
Quick validation
After creating a prefix index, always check two things:
-- 1. Verify the optimizer uses it
EXPLAIN SELECT * FROM users WHERE email = 'john@example.com';
-- 2. Check index size vs full index
SELECT
index_name,
ROUND(stat_value * @@innodb_page_size / 1024 / 1024, 2) AS size_mb
FROM mysql.innodb_index_stats
WHERE table_name = 'users'
AND stat_name = 'size';If EXPLAIN shows your prefix index and the size is 5-10x smaller than the full-column index - you’re done. If EXPLAIN ignores the prefix index, your prefix might be too short. Bump it up by 4 characters and test again.
Found this useful? Subscribe to Podo Stack for weekly database patterns, Kubernetes internals, and Cloud Native tools ripe for production.
Still indexing full VARCHAR(255) columns when only the first 16 characters matter? One ALTER TABLE is all it takes.