
Issue #021 - Talos Linux: the Kubernetes-only OS that removed SSH entirely
read-only rootfs, API-only management, no shell, fleet drift elimination, image-based upgrades

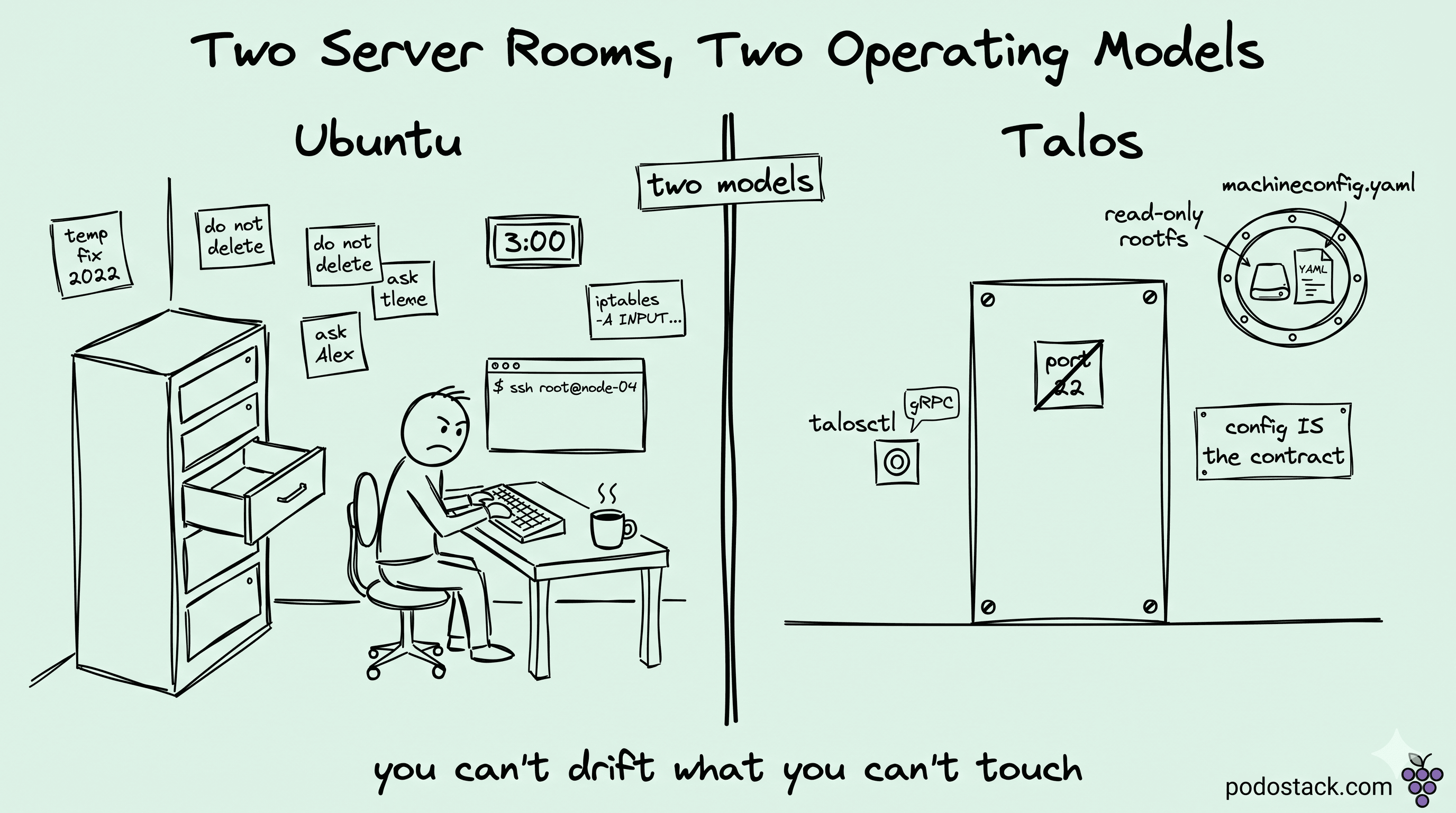
Two years ago, on a cluster that wasn't even mine to fix, I tracked a scheduling failure down to a hand-rolled iptables rule dated 2022 - owner long gone, comment in the rule unhelpful, traffic on the new CNI's port quietly dropped. Two of the other thirteen nodes had the same rule. Eleven didn't. Nobody knew when the cluster had turned into fourteen subtly different operating systems, but it had, one 4am fix at a time.
Talos's answer is to make that story impossible. You can't SSH into a Talos node - there's nothing listening on port 22. No sshd, no shell, no package manager, no /etc you can hand-edit. The node accepts one thing: an authenticated gRPC call to talosctl. Everything else - manual patching, ad-hoc rules, drift - gets removed at the source by removing the surfaces that enable it.
This issue is the closer for the 4-week cycle. Issue #18 moved cluster state out of Git into OCI. Issue #19 looked at the silent failure of expiring tokens. Issue #20 made image pulls disappear from cold starts. This one is about the node itself becoming an artifact you replace rather than a server you log into.
🏗️ Architectural Pattern: OS as immutable image
What Talos actually is
Strip a Linux distribution down to "the things a kubelet needs to run, and not one binary more," then refuse to let anyone add anything else. That's Talos. The whole OS lives in a single compressed image, around 80 MB. The rootfs is squashfs, mounted read-only at boot. There's no /usr/bin/bash because there's no bash. No apt or dnf because there's nothing to install. No /etc/passwd to edit because there are no users to log in as. The init system isn't even systemd - it's a Go binary called machined that's also the API server for the node.
When you boot a Talos node, three things happen in order. The kernel loads, machined starts, and machined reads a single file called machineconfig.yaml. That file is the entire configuration: which cluster to join, what control-plane endpoints exist, what the disks look like, which CNI to use, what NTP servers to trust, which kernel modules to load. One file, declarative, applied at boot. No cloud-init, no Ansible playbook, no role assignment over SSH after the fact.
The shape of that config matters. Here's the minimum needed to register a worker:
version: v1alpha1
machine:
type: worker
token: <cluster-token>
ca:
crt: <base64-ca-cert>
certSANs:
- 10.0.0.10
kubelet:
extraArgs:
rotate-server-certificates: "true"
network:
hostname: worker-01
interfaces:
- interface: eth0
dhcp: true
cluster:
controlPlane:
endpoint: https://10.0.0.10:6443
network:
cni:
name: ciliumThat's the whole machine. No layer of templated cloud-init over the top, no role-based provisioning that fills in different bits depending on whether this node ended up in the gpu pool or the data pool. The config is the contract. If two nodes have the same config, they are the same node, byte for byte, after they boot.
The COSI resource model
There's a piece of Talos that doesn't get mentioned enough, and it's the part that makes the rest hang together. Talos exposes everything on the node as resources in a Kubernetes-style model called COSI (Common Operating System Interface). Network interfaces, mounted disks, kubelet status, running services - all the things you'd normally inspect with five different CLI tools - show up as one queryable resource tree. You read it with talosctl get, the same way you'd kubectl get a pod.
$ talosctl get nodeaddresses
NODE NAMESPACE TYPE ID VERSION ADDRESSES
10.0.0.21 network NodeAddress default 3 ["10.0.0.21/24"]
$ talosctl get services
NODE NAMESPACE TYPE ID VERSION RUNNING HEALTHY
10.0.0.21 runtime Service apid 2 true true
10.0.0.21 runtime Service kubelet 3 true true
10.0.0.21 runtime Service etcd 2 true trueIt's the same architectural move Kubernetes itself made for workloads - everything is a resource, everything is observable through a uniform API, no special tooling per subsystem. Linux's whole "everything is a file" pitch is the historical version of this idea, but in practice you ended up with iproute2 for one thing and systemctl for another and cat /proc/whatever for a third. COSI puts it all under one query interface, and that interface happens to be the only way to look at the node at all.
Upgrades that don't drift because they can't
Traditional node lifecycle looks like this. Ubuntu 22.04 LTS as the base, apt update && apt upgrade on a weekly cron, kubelet from one Kubernetes repo, container runtime from another, kernel patches that mean rolling reboots one node at a time. Six months in, two of your fifty nodes end up on a slightly different containerd because some repo cached weirdly during one rollout. You don't know about it. You find out during an incident.
Talos doesn't have that loop because there's nothing to update incrementally. An upgrade is a new image. Period.
$ talosctl upgrade --nodes 10.0.0.21 \
--image ghcr.io/siderolabs/installer:v1.8.2What happens under the hood is straightforward: Talos has two root partitions on disk, A and B. The running OS is on A. The upgrade command writes the new image to B, flips the bootloader entry, and reboots. If the new image fails to come up healthy within a timeout, the bootloader falls back to A on the next reboot. The on-disk state for the cluster - etcd data, mounted volumes - lives on its own partition that survives the swap. The OS itself is a sealed artifact that gets replaced atomically.
This is the same A/B partition pattern ChromeOS pioneered for laptops and that Android adopted years later. Talos brings it to Kubernetes nodes. The bet is identical: if the OS is small, sealed, and replaced as one unit, there is no surface for drift. There's no concept of "this node has been patched 47 times and the next one has been patched 49 times." There's the version of the installer image you booted from. That's the node's identity.
Compare that to the Ubuntu-or-RHEL alternative. The system was designed to be modified after install - that's the whole point of a general-purpose distro. Package managers exist to add things. systemd-resolved gets a config flag. cron gets an entry. A junior on-call adds a tc qdisc to "fix" a latency problem at 4am. None of it is recorded anywhere except in the running kernel's state, and none of it survives a reinstall, so the reinstall is the thing you're terrified of doing.
Talos inverts that fear. The reinstall is the cheap operation. The hand-edit is the expensive one, because there is no hand-edit. You change the config and reapply; the node converges. Same config, same node. Different config, different node. The state isn't hidden in seventeen places.
This connects directly back to Issue #18. GitOps without Git wasn't really about Git - it was about taking what used to be in-band (manifests fetched from a Git remote, rendered on the cluster) and moving it to a content-addressed artifact in a registry. Talos is the same rearrangement at the node layer. What used to be in-band (configuration changes made over SSH against a long-lived server) becomes a content-addressed artifact: an installer image and a config file. The cluster pulls both, the cluster applies both. The arrow shortens.
Links
Talos: image-based upgrades
🔥 Hot Take: SSH is a fleet-scale anti-pattern
The honest version of "for debugging"
Every team that runs Kubernetes at any scale ends up with a Slack message somewhere that reads "can you SSH into node-04 and check if /var/lib is full." It's so normal the question feels harmless, and it isn't.
What happened on node-04 between login and logout isn't recorded anywhere. The time it bit me, someone had tweaked /etc/sysctl.conf months earlier to chase a TIME_WAIT problem off a 2019 Stack Overflow answer, logged out, and never wrote it down; I lost a week to it. The audit log gives you two timestamps - in at 03:14, out at 03:41 - and nothing in between. Stretch that across forty nodes and two years of on-call and the cluster on paper quietly stops being the cluster that booted. The third time that drift was the root cause of a Sev-2, I quit calling it a flaw. It is the model, not a bug in it.
So Talos removes the entry point. Not made-it-opt-in. Not feature-flagged-off. The sshd binary isn't shipped. There's nothing to disable because there's nothing to enable, and you can't add it back without rebuilding the installer image from source. The bet underneath: no debugging case is important enough to justify owning that drift forever.
What replaces it
The objection writes itself: "Sometimes you need to look inside the node." Sure. Here's what Talos gives you instead.
Four talosctl verbs cover most of what people used SSH for. dashboard opens a curses-style live view of CPU, memory, interfaces, services, kernel messages - a read-only window onto the COSI tree, and it covers about 80% of normal-day investigations. logs <service> streams the journal for kubelet, containerd, etcd, or machined itself, over a gRPC channel authenticated with mTLS. read opens files from a sandboxed allowlist (/proc/<pid>/status, parts of /sys/class/net/*, and so on); /etc/shadow is on the deny side, but Talos doesn't ship one anyway.
talosctl pcap is the one worth pausing on. It runs a tcpdump-equivalent against any interface and streams the capture file back to your laptop. Cluster-wide packet capture without any node having a shell - the kind of thing that traditionally forced an SSH session, and now happens through the same API as everything else.
And if you really need an interactive shell on the host, kubectl debug node/... from upstream Kubernetes creates an ephemeral pod with nsenter privileges into the host namespace. That session shows up in the K8s audit log under a real identity, stays scoped to the pod, and disappears the moment you exit. An auditor gets a paper trail that raw SSH never left.
The 10% that pushes you somewhere better
What's left is a short list: a kernel panic on a node so dead the API server can't reach it, a failing disk you want to read sensors off, the case where apid itself has crashed.
Two of those still happen inside the model. A panicked node boots to a serial console in "maintenance mode" with the same API, no cluster joined, enough to hand-recover it; failing-disk sensors come through COSI block-device and SMART resources, queried like any other service. The crashed-apid case is the one with no trick to it - you reboot the node, and that's the whole recovery procedure. No Houdini act on a half-dead box, which is the price of every other node looking exactly like its config says it should.
Then there's what Talos does to a team's debugging habits. The crew that lived in SSH had a hundred small workflows leaning on it - a one-liner that listed iptables rules across the fleet, a shell script that rotated logs in some bespoke directory, an overnight cron that snapshotted the whole config tree to "catch drift." None of that survives the move, because the surfaces those scripts touched don't exist anymore, so each one has to be rebuilt around whatever it was really solving. Drift-catching turns into an assertion that machined enforces continuously, the running config measured against the declared one with nothing left to babysit. Logging stops being a cron job and becomes real observability. The host-shell reflex ends up as a distroless debug container the team checks into the repo like any other tool. Each rewrite hands the cluster something it owns outright, instead of something that only lived in the team's heads.
The migration is real friction. But the friction is bounded - you do it once, you write the right tools, and then you have a fleet where every node is provably the same as the others. The traditional setup has unbounded friction: every incident teaches the team a new way to make the cluster slightly different from itself, and the bill comes due in some 4am that nobody can fully reconstruct afterwards.
This is the same dynamic Issue #19 was about, just at a different layer. Bound SA tokens fail silently because the legacy assumption (a token lives forever once minted) was already the failure mode - the cluster had been quietly compensating for a broken expectation for years, and one upgrade exposed it. Drift is the silent-failure version of that for nodes. The cluster looks fine, the workloads run, until one day they don't and you find out node-04 has been running a different kernel for eighteen months.
Links
Talos: talosctl CLI reference
Kubernetes: debugging a node with kubectl debug
🆚 Showdown: Talos vs Kairos vs Flatcar
Three immutable-OS projects, three different bets, three different ideas about how much of the traditional Linux you're willing to throw away.
Talos: K8s-only, no userland, API-driven
Talos is the most opinionated of the three. The userland is gone. Not minimized - gone. The OS is a kernel, an init binary, the kubelet, containerd, etcd if it's a control-plane node, and a small handful of supporting services. There is no shell of any kind on the running system. The interface to the node is talosctl, full stop.
Configuration is one YAML file. Upgrades are image swaps. Networking can use KubeSpan, Talos's built-in WireGuard mesh that gives every node-to-node link a wire-encrypted tunnel without you wiring up the mesh yourself. The control plane runs etcd directly on the host with sane defaults, no need to babysit it as a separate concern.
The clusters where this pays off are the ones where the team owns the whole stack and wants production to match its config byte for byte - managed fleets, edge boxes that are a four-hour drive away when they go AWOL, platform teams whose contract with their users is "the cluster works the same way every Tuesday."
Where it fails is more specific, and I've hit it more than once. A team had a legacy operator that mounted /var/log from the host and shelled out to rotate something; on Talos that whole assumption evaporates, and there's no flag to bring it back. Custom kernel modules and non-containerized compliance agents are the same problem one layer down - the escape hatches you were relying on are simply gone. For the teams Talos fits, that absence is the whole point; the ones it doesn't fit usually find out on day two.
Kairos: meta-distribution with a userland
Kairos starts from the opposite direction. You give it a container image of any base Linux distro - Ubuntu, openSUSE, Alpine, Rocky, whatever your team already knows - and it wraps that into an immutable OS using the same A/B partition pattern, with K3s or full K8s baked in. The userland of your starting distro comes along for the ride, which is the entire reason to pick it.
The first time you SSH into a Kairos box it feels like a normal Linux system, and you edit /etc the way you always did. Then you reboot and the edits are gone, because the rootfs is immutable and your changes lived in an overlay that the next image upgrade wipes. That's the whole bargain in one gesture: immutability guarantees on the storage layer, the familiar shape of a Linux box on the operational layer. Configuration is a YAML file here too, but Kairos runs cloud-init under the hood, and upgrades are container-image pulls unpacked to the inactive partition the same way Talos does it.
Migration is where I'd actually reach for it. A team moving off a traditional distro that wants to keep its runbooks, muscle memory, and SSH habits intact for a while can do exactly that. The same forgiveness covers edge boxes where one hardware-diagnostic SSH session a year is genuinely useful, and mixed workloads with a pod that talks to host-level userland nobody wants to containerize - A/B atomic upgrades without signing up for the full Talos paradigm shift.
That forgiveness comes with a bill. Kairos is more flexible than Talos, and flexibility cuts both ways: the door is open, so eventually somebody walks through it, and the drift surface is smaller than Ubuntu's but a long way from zero. The image is your base distro plus Kairos's overlay, bigger and more complex than Talos's 80 MB. I've watched people pick Kairos expecting it to tighten into Talos over time and end up frustrated - the off-ramp is the feature, not a stepping stone. Immutability you can ease into is the right call if you signed up for migration, and the wrong one if you wanted the strict regime from day one.
Flatcar: the CoreOS lineage, with auto-update
Flatcar is the most familiar of the three to anyone who ran CoreOS Container Linux back in the day - because it's the same thing, forked when Red Hat sunsetted CoreOS, kept alive by Kinvolk and now Microsoft.
It looks like a minimized traditional node, and that's deliberate. The /usr partition is read-only and there's no package manager, but /etc and /var are small and writable, SSH is right there (gated on systemd, configured through Ignition, the declarative provisioning tool Flatcar inherited from CoreOS), and a container runtime ships in the box. The userland sits between the two extremes - leaner than Ubuntu, nowhere near Talos's nothing.
What sets it apart is auto-update. Flatcar nodes phone home to a public update server (or your own mirror) on a schedule, stage new versions into the inactive partition in the background, and reboot when Locksmith or FLUO say it's time. You're not running apt update on a cron; the OS does the equivalent on its own clock, with A/B safety the whole way.
Reach for it when you want immutable-ish without giving up SSH or systemd - the "I just want a CoreOS that's still maintained" case, or a cluster run as managed cattle rather than locked down, where you trust the team not to drift the nodes and also trust them to know what to do when one breaks. It's production K8s with sensible immutability and zero appetite for a paradigm shift.
The cost is that it's still shaped like a traditional node. The drift surfaces are smaller but they're there: anyone with SSH can hand-roll an iptables rule, and Flatcar's writable paths mean that rule rides through the next update. Auto-update carries a tail of its own - every so often a release breaks something on your specific hardware, you pin a version to recover, and the moment you do you've reintroduced the "is everyone on the same version?" question that Talos's strict regime had eliminated.
The trade-off axis
Pick any axis you like - drift surface, learning curve, debuggability, operational risk, how much your old runbooks still apply. They all map onto the same gradient.
Talos is at one end: maximum paradigm shift, minimum familiarity, smallest possible attack and drift surface, requires you to rebuild your operational tooling, gives you the strongest guarantees in return. Kairos is in the middle: immutability with an off-ramp, you keep your userland, you give up some of the strictness, the tradeoff is "easier migration, slightly worse guarantees." Flatcar is at the familiar end: immutable rootfs, but the shape is still a Linux box you can SSH into, the migration is cheap, the drift surface is small but real.
There's no objectively right answer. The honest question is which side of that axis your team's incidents come from. Drift from someone fixing things over SSH at 3am? Talos's strict regime is the cure. Worst outages mostly operational unfamiliarity, runbooks that won't survive a paradigm change? Flatcar lets the runbooks live. And if it's somewhere in between with the door deliberately left open, Kairos is the answer.
For Podo Stack readers running platform teams of any size, I'd bias toward Talos for new clusters and Kairos for migrations. Flatcar is the right call when "immutable-ish CoreOS replacement" is literally what you set out to find. All three are CNCF-relevant and production-tested at scale - this isn't a "pick one carefully or you'll regret it" choice, it's "pick the one that matches the cultural change you're willing to make."
Links
Sidero Labs: Talos Linux on GitHub
Flatcar: Ignition provisioning
What this cycle was about
Four issues - Gitless GitOps, silently-expiring SA tokens, image preload, immutable OS. Different layers, but the same argument kept surfacing underneath each one.
It comes down to a single question: what does the cluster actually trust, and where does that trust come from? Gitless GitOps moved the answer off a Git branch anyone could rewrite and onto an OCI artifact pinned by digest, signed by a CI workflow you can verify. The bound-token postmortem was the same lesson dragged out of a real incident - the only credential worth anything is the one the kubelet rotated 30 seconds ago, and the copy your operator cached back in 2024 is just lying there on the floor. Then preload pushed the question one hop further: trust that the bytes are already on disk before you schedule, not the registry's tail latency under load. Talos is where it bottoms out. The node is the bytes in its installer image, full stop - not whatever some on-call typed into a shell at 3am.
I didn't plan for the four issues to rhyme. It only clicked around the preload draft, when I caught myself making the same move a third time - pushing the thing the cluster trusts one step closer to the thing it actually runs. By this issue there's no gap left to close, since the node is its own installer image. Funny how a month of separate topics turns out to have been one topic wearing four hats.
Next cycle picks up a different thread. See you Tuesday.
- Ilia