
Issue #020 - Image Preload Operator: zero-second cold start, even for 8GB images
pre-cache DaemonSet, image warm pool, Stargz callback, sub-second startup for 8GB images

Your inference pod schedules onto a fresh node. The image is 8GB. The pod sits in ContainerCreating for ninety seconds while the kubelet pulls it. Issue #15 was about why those ninety seconds are the way they are. This issue is about how to skip them.
This is the closer for the image-distribution series. Issue #3 looked at Stargz, which made cold start fast by being lazy - read what the container actually touches, ignore the other 94%. Issue #1 looked at Spegel, which turned every node into a peer and let the cluster share layers over its own network instead of hammering the registry. Both bet on a different shape of the same problem. Image Preload Operator makes a third bet, the most boring and the most effective one: have the bytes already on the node before any pod that needs them gets scheduled.
💎 Hidden Gem: Image Preload Operator
A DaemonSet that pulls images you haven't asked for yet
If you've ever run kubectl describe pod on a stuck inference workload and watched the Pulling image event sit there for over a minute, you already know the shape of the problem. The kubelet's pull is sequential, the registry is far, and your pod's startup latency is whatever number sits between the request and the first byte of the container being usable on disk.
The trick the operator pattern uses is not clever in the technical sense. It runs a DaemonSet on every node (or on a labeled subset), the DaemonSet calls into the container runtime - containerd, CRI-O, or Docker, whichever the cluster runs - and asks it to pull a configured list of images. The runtime stores those images in its local image cache, the same cache the kubelet would use anyway. When a pod for one of those images lands on the node later, the kubelet finds the image already present, sees imagePullPolicy: IfNotPresent, and skips the pull entirely. The container starts in whatever time it takes to set up cgroups and namespaces. For most workloads that's under a second.
The most popular implementation of this pattern is kube-fledged, which exposes the warm cache as a Kubernetes-native CRD called ImageCache. You write an ImageCache resource, the operator reconciles it into a Job that runs against the right nodes, the Job pulls the images, the operator tracks per-node status, and a kubectl get imagecache tells you whether every node in the pool has the bytes. There are a handful of other implementations - the OpenKruise project ships a similar primitive called NodeImage, and several teams just roll their own DaemonSet around a one-line crictl pull loop. They all have the same shape underneath.
What it's not
People keep filing it next to things it only resembles. A registry mirror is Spegel's job - the operator never sits in the pull path or proxies anything, it just kicks the kubelet's runtime into pulling early.
Stargz is the lazy-filesystem one, and the operator isn't that either. It doesn't touch how the image gets unpacked or read; the bytes land on disk exactly as they always would, and the only thing that shifts is the timing.
A baked AMI buries the image inside the node image itself, so the node has to be rebuilt whenever the image changes. The operator pulls dynamically instead. Push a new tag at noon and the next reconcile cycle lands it on every node, node image untouched.
Why the bet pays
The bet pays when image pulls are predictable. AI/ML inference is the textbook case. You run the same model server image on dozens of GPU nodes, the image is 6-12GB, and the cold start delta between "pull and run" and "already there, just run" is the difference between an autoscaler that responds in two minutes and one that responds in five seconds. The same logic holds for Spark executors and CI runner pools, or stateful databases that share a base image - anywhere the image set stays small and you know it ahead of time.
The bet doesn't pay when the image set is large and unpredictable. A multi-tenant cluster with five hundred different application images per node pool will not benefit from preloading - you'd burn the disk and most of the cached images would never be used. That's the Stargz case. Or the Spegel case, if you've got enough nodes that one will already have the image when another needs it.
The thing nobody mentions
The operator hands you a side benefit that sounds boring until you've needed it: a programmatic way to ask whether a given node has a given image. Once ImageCache.status carries per-node state, an admission policy can refuse to schedule a workload onto a node that's missing its declared image. Pre-flight checks before scaleup get easy the same way, and the Grafana panel that screams when warm-pool drift turns real basically writes itself.
Without the operator, that question lives in ssh-into-the-node-and-grep-crictl-images territory. The operator turns it into a kubectl get. Boring on a normal day - but I've reached for it at 3am more than once.
Links
🔬 Trace: how the warm cache actually fills
The first ImageCache we wrote
Ours came out of a model rollout that kept missing its autoscaling target: new inference pods sat in ContainerCreating long enough that the request queue backed up before any of them were ready to serve. The fix was an ImageCache, and this is close to the one we started with:
apiVersion: fledged.kubefledged.io/v1alpha2
kind: ImageCache
metadata:
name: ml-inference-models
namespace: kube-fledged
spec:
cacheSpec:
- images:
- registry.example.com/inference/llama-3-70b:v2.4.1
- registry.example.com/inference/mistral-large:v1.8.0
nodeSelector:
node-role.kubernetes.io/gpu: "true"
- images:
- registry.example.com/runtime/triton:24.05-py3
nodeSelector:
node-role.kubernetes.io/gpu: "true"
imagePullSecrets:
- name: registry-creds
Writing it, the only real decision was the cacheSpec list, which maps image sets to node selectors. We pointed the model images at the GPU pool and kept them off everything else, so no node would burn disk on an image it was never going to run. Auth I'd braced for and it turned out to be nothing: imagePullSecrets is the same field the pod specs already used, so the private registry just worked.
Then we applied it and watched what happened. The controller picked up the new ImageCache, spun one Job per node-image pair pinned to its node, and each Job reached into that node's CRI socket and asked the runtime to pull. The part I hadn't expected was the bookkeeping. Every node wrote its result back into .status.nodes[], so checking whether the pool was warm became one query instead of an ssh-and-grep tour of the whole fleet.
Inside the Job
When I went digging into how the Job actually pulled, there was less to it than I'd assumed. The socket is the containerd one under /run/containerd on most of our nodes, or the CRI-O equivalent on the rest, and the DaemonSet mounts it as a hostPath volume and shells out to crictl pull. It's the exact code path the kubelet itself takes when a pod creates demand for an image, same socket and same content store. The only thing that changes is when it runs.
The question I kept circling back to was why a Job at all, instead of an init container in the workload pod. We tried the init-container version first. It pulled at pod-creation time, which was the one moment we were trying to get ahead of - we wanted the bytes on disk before the pod existed - and every replica ended up pulling on its own, with nowhere to look to see who was warm or to hold a scaleup until the cache caught up. The operator pulls before any pod exists and keeps every node's state in a single object, and that was the whole reason we moved off the init container.
The kubectl describe view, with and without
Without the operator, on a fresh node:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 92s default-scheduler Successfully assigned ml/inference-7c4 to node-gpu-04
Normal Pulling 91s kubelet Pulling image "registry.example.com/inference/llama-3-70b:v2.4.1"
Normal Pulled 14s kubelet Successfully pulled image "registry.example.com/inference/llama-3-70b:v2.4.1" in 1m17s (1m17s including waiting)
Normal Created 13s kubelet Created container inference
Normal Started 12s kubelet Started container inference
77 of those seconds sat inside Pulling. The rest of the events are microseconds next to it.
The same pod, on a node the operator had already warmed:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 3s default-scheduler Successfully assigned ml/inference-7c4 to node-gpu-04
Normal Pulled 2s kubelet Container image "registry.example.com/inference/llama-3-70b:v2.4.1" already present on machine
Normal Created 2s kubelet Created container inference
Normal Started 1s kubelet Started container inference
No Pulling event at all. The kubelet asks the runtime, the runtime says "already there," and the pod moves on. The 60-90 seconds Issue #15 spent dissecting are simply gone.
Where this falls over
Sounds clean. It is, right up until it isn't.
Image GC. We lost a 12GB Llama image to this on a Friday afternoon, and it took an embarrassing while to work out why. The kubelet runs its own garbage collector against the runtime's image store, governed by imageGCHighThresholdPercent (default 85%) and imageGCLowThresholdPercent (default 80%). Once disk on a node crosses the high watermark, the kubelet evicts unused images until usage drops back under the low one, and "unused" here means "not referenced by any running container." A freshly preloaded image, before any pod has landed on it, is exactly that: referenced by nothing. The GC was built to reap it. Tight disk plus a preloaded image, and the bytes you just paid for are gone before the workload that needed them ever schedules.
There's no clean fix upstream. The pragmatic move is a sentinel pause-container: a tiny pause pod per cached image so the GC counts it as in-use. kube-fledged ships this out of the box, and after I watched it save a node sitting at 91% disk that would otherwise have reaped its model image, I stopped thinking about GC thresholds at all. We still lower thresholds and oversize disks, but that's insurance against the wrong contract, not the fix.
Tag mutability. A CVE patch of ours quietly never reached production for two days, and preload was the reason. Push a new image under a tag that's already cached - rebuild nginx:1.25 overnight, say - and the nodes keep serving yesterday's bits. The kubelet sees the tag already present and asks no further questions, so the "rollout" becomes a no-op nobody thought to verify. Ours reported "all nodes cached" the entire time, while every node ran the vulnerable version. Preload by digest where you can, or wire a periodic re-pull on a cadence the security team owns; the :latest-is-evil argument from Issue #1 only gets sharper here, because preload makes the staleness sticky.
Pull storms on rollout. The first time you apply a large ImageCache, every node pulls every listed image at roughly the same moment. A hundred nodes and a 10GB image means a one-terabyte burst landing on your registry at once. Staging is the cheap mitigation: roll the ImageCache out to a subset of nodes, watch the registry breathe, then widen it. The better one is to pair the operator with Spegel, so the first node pulls from upstream and every other node grabs the layer from a peer over the cluster network.
The "warm cache + P2P mirror" pattern is the hybrid most teams who run this seriously end up at. We'll come back to it in the showdown.
Links
🆚 Showdown: Stargz vs Spegel vs Preload
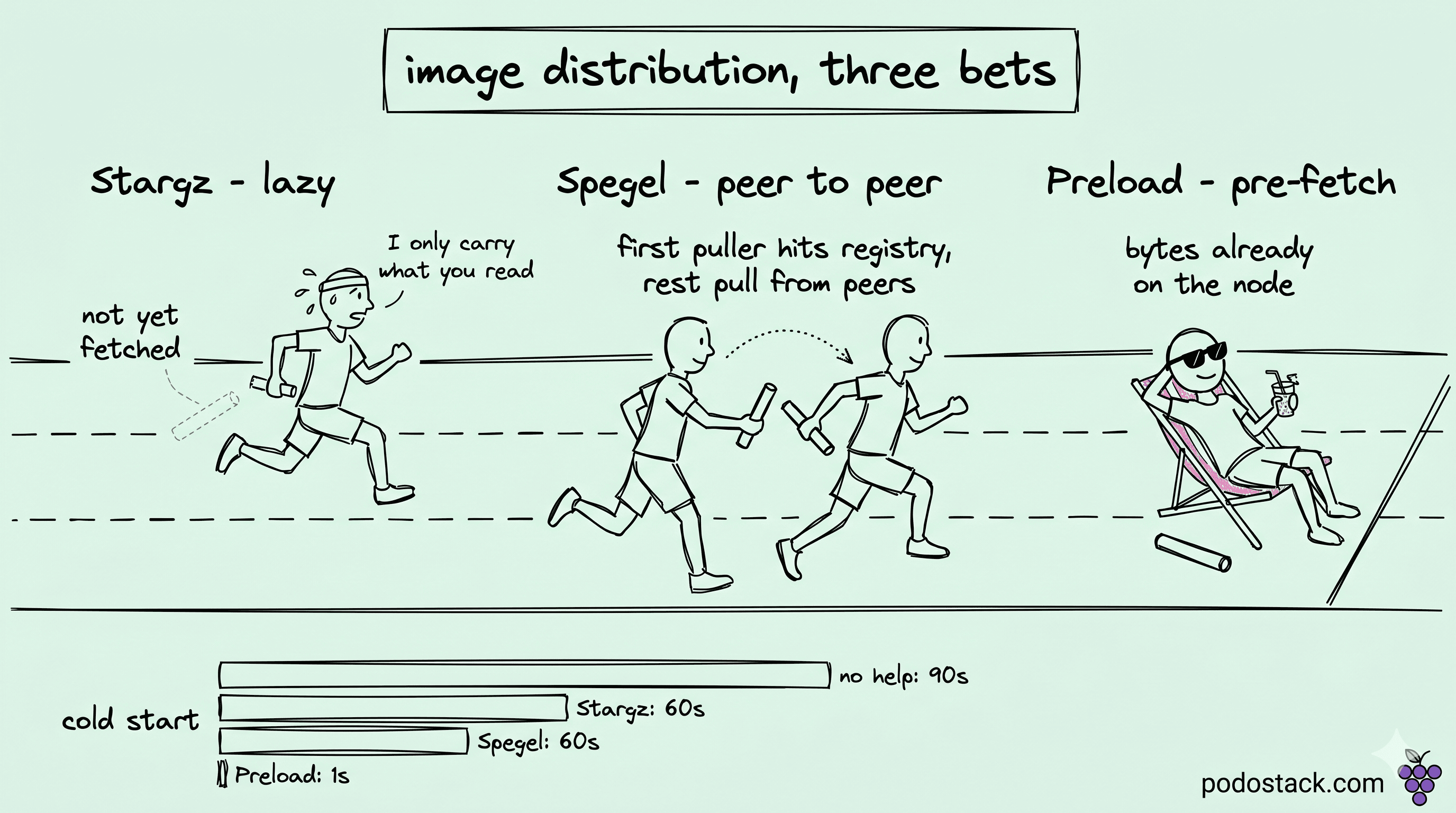
Three bets, one problem
Cold start latency is one problem with three philosophically different bets pointed at it.
Stargz (Issue #3) bets on laziness: don't pull what the container never reads. The image mounts as a lazy filesystem and bytes arrive from the registry on demand, so a container starts in a second or two even on a cold node, even at multi-gigabyte sizes. The price is FUSE in the I/O path and a standing dependency on the registry for chunks you haven't fetched yet.
Spegel (Issue #1) goes after locality instead. If the registry is the bottleneck, turn the nodes into the registry: each one serves layers it already has to its peers over the cluster network. The first pull anywhere still hits upstream, and everything after that runs at LAN speed.
Preload (this issue) is the boring one. The pull still happens, it just happens before a pod wants the image - by the time the scheduler picks a node, the bytes are already sitting there. The bill is disk and the ongoing chore of keeping ImageCache honest against what's actually deployed, and in exchange the whole latency tail disappears.
Where each wins, sharply
We've leaned on all three in production at one point or another, and the dividing lines turned out sharper than the project READMEs let on.
Stargz is the right call when images are small and land on many different nodes for short jobs, the CI-runner and serverless-backend end of the spectrum. The image set there is wide and shallow, you can't predict what to preload, and lazy loading is the only thing that keeps up.
Spegel earns its place on large clusters where the same image set rotates across hundreds of nodes: multi-tenant platforms and big SaaS fleets, where you're already paying for inter-node bandwidth and the registry has quietly become the bottleneck. Once one peer has a layer, the marginal cost of the next node pulling it falls to almost nothing.
Preload, the one this issue is about, pays off in the predictable case: the same big images going to the same nodes over and over. That's our AI inference fleet and the GPU training pools, plus Spark jobs and the stateful databases we keep on dedicated nodes. The set is narrow and stable, a fast cold start is worth real money, and the pre-pull cost can run off-hours when nobody's watching.
The hybrid that actually ships
Most teams that run this at scale don't pick one. They pair Preload with Spegel.
The first time the operator pulls an image, one node in the cluster talks to the upstream registry, pulls the bytes, and caches them. Spegel indexes that node's layers and announces them. When the operator's DaemonSet on every other node starts its pull, Spegel intercepts the request, sees that a peer already has the layer, and serves it over the cluster network instead. The registry sees one pull instead of a hundred. The cluster gets warm everywhere in the time it takes to copy bytes between two nodes over a 10Gbps NIC.
Stargz fits in as a third layer for the long tail. Workloads that don't fit your ImageCache declaration - because they're new, or one-off, or some tenant pushed something the platform didn't know about - still start fast because Stargz makes the cold pull lazy. You've spent zero extra operational effort and you've turned the cold-start tail latency from a multi-minute outlier into a sub-second curve.
That's where the series lands. Issue #3 was the smartest single technique, Issue #1 the smartest distribution model, and this one is just the bluntest instrument in the drawer: have the bytes there already. Put all three together and the "first 60 seconds" problem from Issue #15 stops being a problem at all.
Links
Podo Stack: Issue #3 - Lazy Pull, Smart Scale (Stargz)
Podo Stack: Issue #1 - Spegel, Pixie, and why :latest is evil
Podo Stack: Issue #15 - a pod's first 60 seconds
Issue #21 picks up a parallel thread. If you can preload the bytes onto the node, the next question is what happens when the node itself is the image. Talos and the immutable-OS school of thought treat the whole host as an artifact you replace rather than configure. The arrow keeps shortening, and the cold start keeps moving upstream.
- Ilia