
Cilium Egress Gateway: stable outbound IPs for pods that need them
How eBPF SNAT gives selected pods a predictable egress IP without a cloud NAT gateway

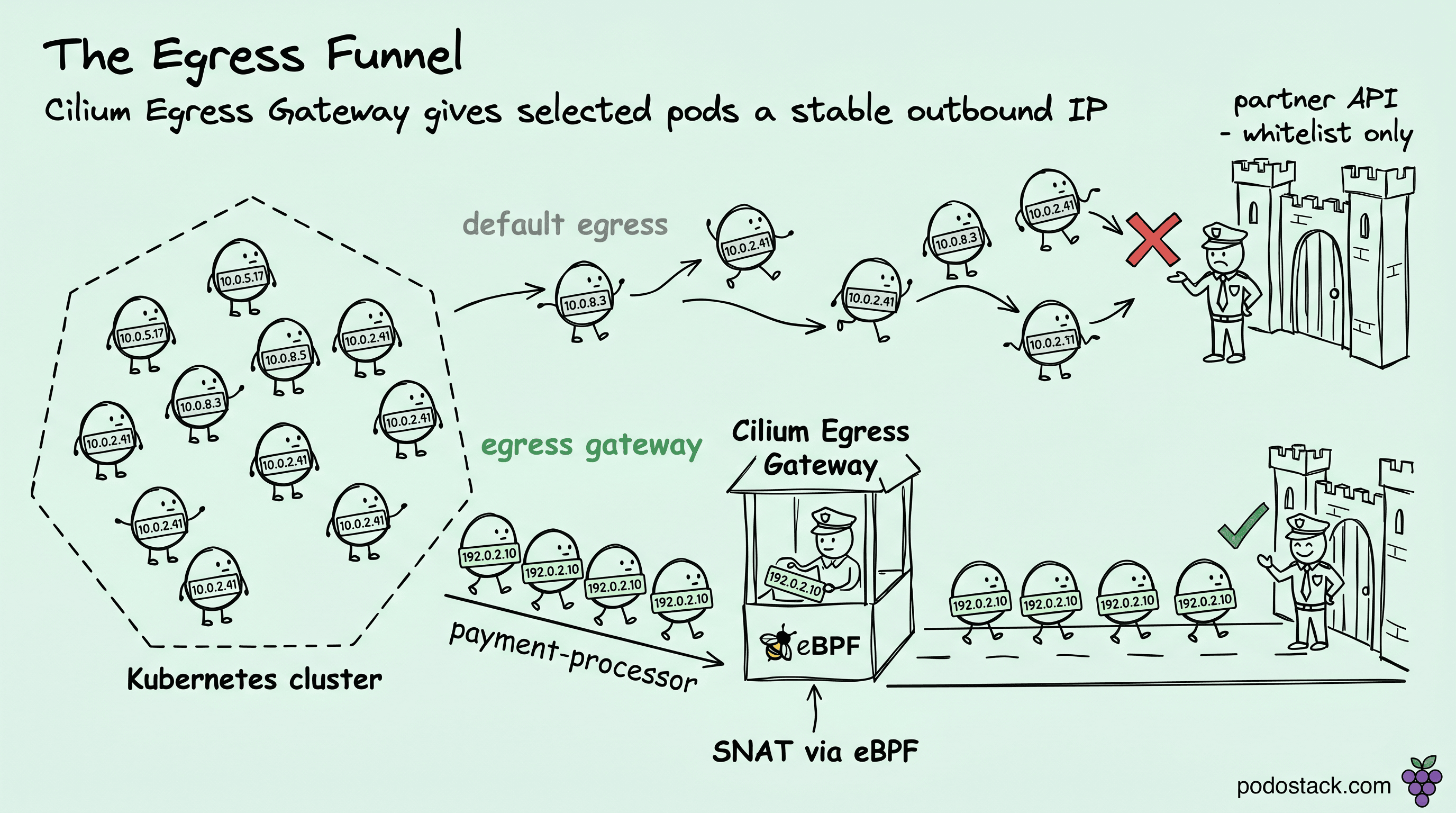
Every platform team eventually gets the same ticket. Team X's service needs to call Team Y's legacy API. Team Y says, "sure, give us your IP addresses and we'll whitelist them." Team X's pods have 47 different IP addresses across 15 nodes across 3 availability zones, any one of which might disappear in the next minute because Karpenter is consolidating. The IPs aren't stable, and cloud NAT gateways apply the whole VPC's egress through one IP, which is too coarse.
Cilium Egress Gateway exists for this exact problem. One feature of the Cilium CNI, usually skipped in intro tutorials, that solves a real integration problem most clusters eventually face.
The problem in concrete terms
Your application needs to reach an external service. The external service is one of:
A partner API that requires IP whitelisting.
A legacy database that sits behind a firewall with an IP-based rule.
A government service that only accepts traffic from registered source IPs.
A SaaS product with per-customer IP allowlists for compliance.
On the pod side, source IPs are ephemeral. They depend on the node, the CNI's IPAM scheme, whether the pod was restarted 30 seconds ago, and a dozen other factors you don't control. Static IPs for pods are either fragile (host network, not safe) or unscalable (assign each pod a reserved IP).
Cloud NAT gateways have the opposite problem. They work at the VPC or subnet level. Every egress from every pod on every node in that subnet gets the same NAT IP. Great for "all my cluster traffic exits through one IP." Terrible if you want to say "only the payment-processor pods should exit through this IP."
Cilium Egress Gateway is the piece that fits between these extremes. Per-pod granularity, stable egress IPs, no dependency on cloud-specific NAT.
How it actually works
Three parts:
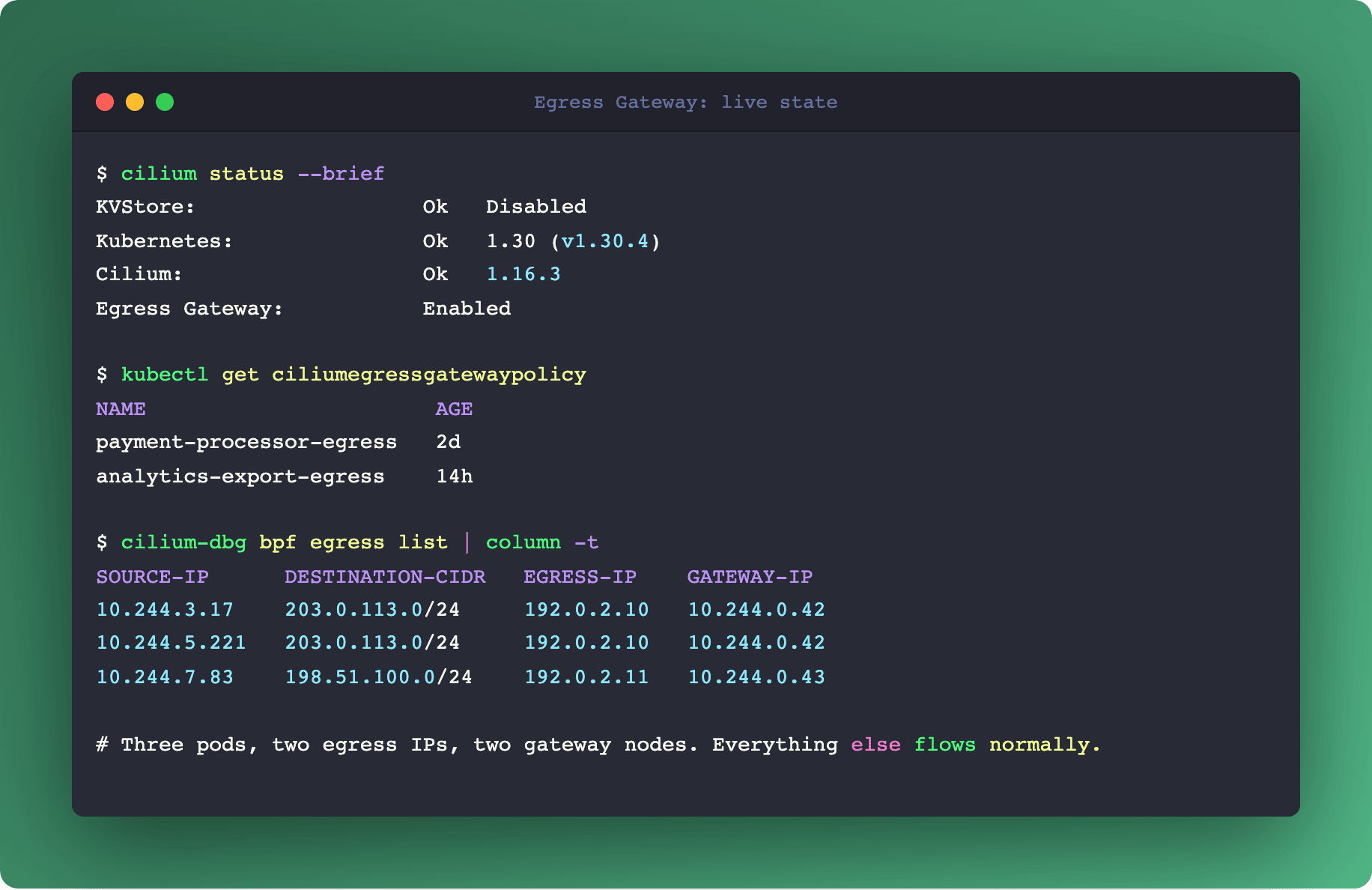
Gateway nodes. Designate one or more nodes in the cluster as egress gateways. They have the stable IPs. You mark them with a label like node-role.kubernetes.io/egress-gateway=true.
CiliumEgressGatewayPolicy resource. A CRD that declares the routing rule. Two key fields:
endpointSelector: which pods (by labels) the rule applies to.destinationCIDRs: which external IP ranges trigger the rule.
eBPF datapath. When a pod matching the selector sends a packet to an IP in the destinationCIDRs, the Cilium eBPF program on the originating node intercepts it. Instead of sending it out the node's default route, it tunnels the packet to one of the gateway nodes. The gateway node does source NAT (SNAT) on the packet, rewriting the source IP to the gateway's stable IP, then forwards to the real destination.
From the external service's perspective, traffic arrives from the gateway IP. The external service has no idea the real client is a pod that started 30 seconds ago.
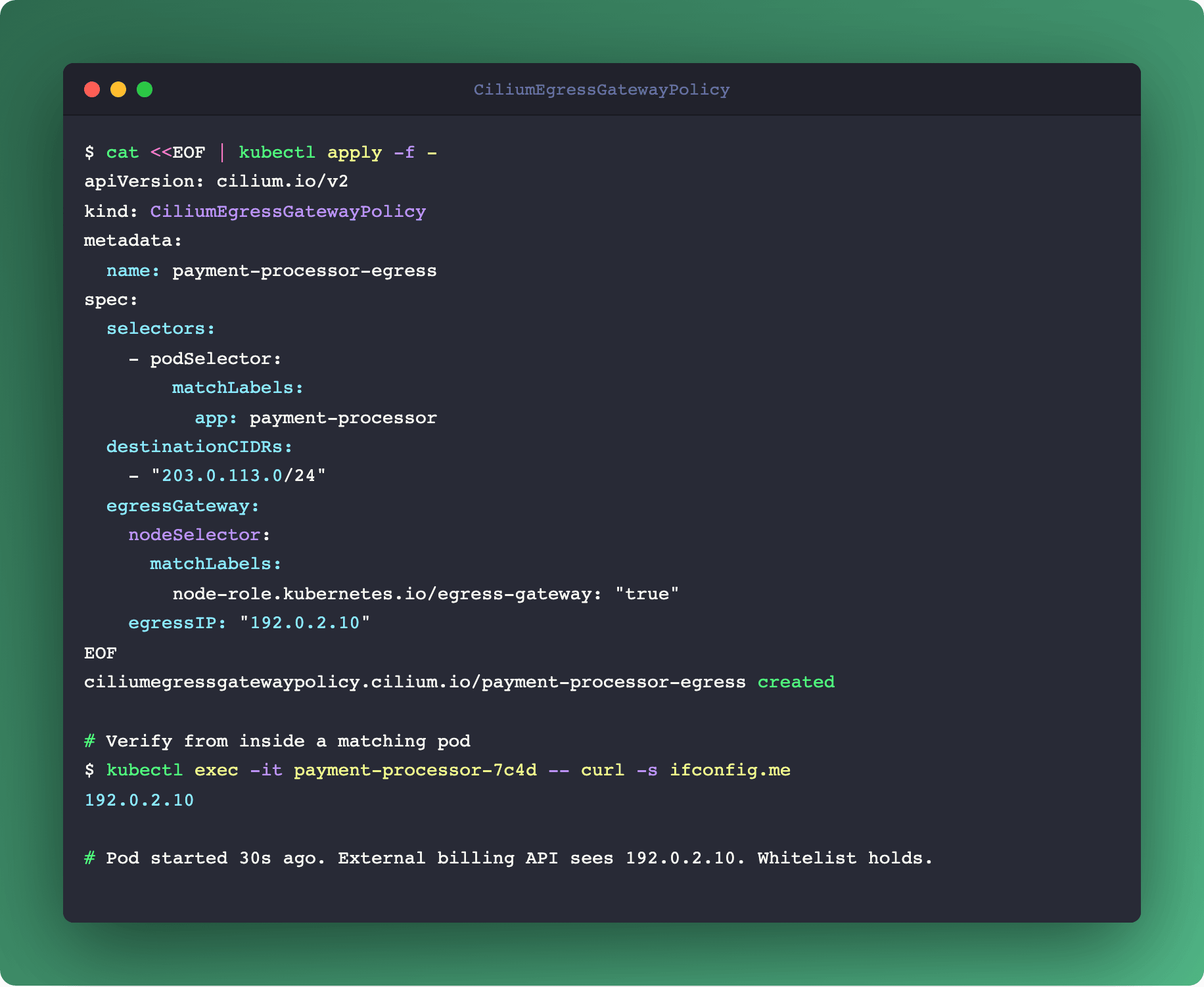
Example policy:
apiVersion: cilium.io/v2
kind: CiliumEgressGatewayPolicy
metadata:
name: payment-processor-egress
spec:
selectors:
- podSelector:
matchLabels:
app: payment-processor
destinationCIDRs:
- "203.0.113.0/24"
egressGateway:
nodeSelector:
matchLabels:
node-role.kubernetes.io/egress-gateway: "true"
egressIP: "192.0.2.10"Pods with app: payment-processor sending to 203.0.113.0/24 exit through 192.0.2.10. Everything else flows normally. Other pods sending to 203.0.113.0/24 flow normally. The rule is both pod-specific and destination-specific.
Links
Why this matters beyond one ticket
Four benefits that compound:
Granularity. Different services can have different egress policies. Frontend traffic goes out the default path. Payment processor traffic goes through gateway A. Analytics exports go through gateway B. Per-service blast radius, per-service audit.
Least-privilege firewalling. Instead of opening the external firewall for the entire IP range of your cluster nodes (which changes every time autoscaling runs), you open it for one or two gateway IPs that don't change. The attack surface shrinks to the ports you actually need.
High availability. Designate multiple gateway nodes. If one fails, traffic reroutes through the next one. Standard Cilium health-checking handles the failover. No external load balancer needed.
Cloud-portability. The mechanism works identically on AWS, GCP, Azure, bare metal, or any mix. Not tied to NAT Gateway, not tied to Route53, not tied to any cloud-specific primitive. Moving clouds, this is one fewer thing to rebuild.
Links
Where this breaks or surprises
Three edge cases to understand before relying on Egress Gateway in production:
Gateway node is a single point of concentration. All matching traffic flows through one or a few nodes. CPU and NIC bandwidth on those nodes matter. For high-throughput egress (bulk data exports, video streaming), gateway nodes need to be sized for the load, not just "whatever was cheap."
Reply traffic uses normal return path, not the gateway. The external service sends its response to the gateway IP. The gateway routes it back through the cluster's internal network to the original pod. If your return traffic pattern is heavy (large response payloads), the gateway has ingress load too.
Tunnel overhead. Traffic between originating node and gateway node is tunneled (VXLAN or similar). Adds some latency and CPU cost. Measurable for latency-sensitive workloads, invisible for batch jobs.
Connection tracking lives on the gateway. If the gateway node restarts, in-flight connections break. Client retries usually handle this, but long-lived TCP connections (database replication, gRPC streaming) can be more sensitive.
Links
Comparison with alternatives
If Egress Gateway doesn't fit, what else is there?
Cloud NAT Gateway (AWS NAT Gateway, GCP Cloud NAT). Whole-VPC scope, not per-pod. Fine if you have one tenant and one outbound identity.
Per-node SNAT via iptables. Works, but every node needs its own stable IP. Scaling a cluster means updating whitelists.
Calico Egress Gateway. Similar feature in Calico's CNI. Same concept, different implementation. If you're already on Calico, use it.
Proxy-based egress (Envoy, Squid). A sidecar or L7 proxy that applies egress policy. Useful for HTTP-layer rules but heavier and more complex than Egress Gateway for simple IP-stability needs.
For the "give this specific service a stable outbound IP" problem, Cilium Egress Gateway is usually the lightest, most granular answer if Cilium is already your CNI.
Links
The operational playbook
If you're rolling Egress Gateway out, a few practical steps:
Designate gateway nodes with taints. Regular workloads shouldn't schedule on egress gateways. The taint keeps them clean.
Size for peak egress plus headroom. 2x expected peak is a reasonable starting point. Monitor eBPF program CPU on gateway nodes.
Start with a single non-critical service. Confirm the SNAT works end-to-end, check the logs at the external service, verify reply traffic routes correctly.
Document the IP allocations. Which gateway IP, which policy, which service. This outlives the engineer who set it up.
Alert on gateway node CPU and connection count. Saturation leads to silent packet drops before failover kicks in.
Links
Summary
Egress Gateway is the Cilium feature that solves a real integration problem most clusters eventually hit. Not flashy, not in the keynote, rarely on best-practice lists. Just a small CRD, a few eBPF programs, and one specific problem (stable outbound IP for selected pods) cleanly solved.
If you've been using a cloud NAT Gateway for too-coarse egress policy, or hacking per-node SNAT rules that break on every autoscale event, this is the cleaner answer.
For the broader Cilium context and why eBPF datapath matters, see Cilium Deep Dive. For the governance side where egress policies get enforced at admission, Kyverno Beyond Admission covers policy-driven outbound control.