
Podo #016: Kyverno Isn't Security. It's Governance - And You're Using 20% of It.
Mutating admission patterns, generate rules for cross-namespace propagation, cleanup policies with kor, CronJob silent failures, and the image hygiene pipeline


Welcome back to Podo Stack. Kyverno shows up in every platform stack these days, and it almost always arrives the same way: some team ships 80 admission policies they copied from a blog post, mostly image-signing and pod-security, and then declares "Kyverno is done." That's the checklist view.
Last week (Podo #015) I walked through how an attacker reads a pod's first 60 seconds and how each step in the pivot chain maps to a defensive control you probably already own. This week is the flip side: the governance engine those controls actually live in, and why most teams are using a fraction of what Kyverno can do.
Five surfaces, five rule types, one engine.
Here's what's good this week.
Mutating admission is where the real power lives
Most teams reach for Validate when Mutate would be safer.
A Validating policy rejects the request. Developer hits the wall, files a ticket, platform team writes an exception, and three releases later the policy rots into a set of exemptions nobody can reason about. A Mutating policy fixes the request silently. Developer never notices. The policy stays clean.
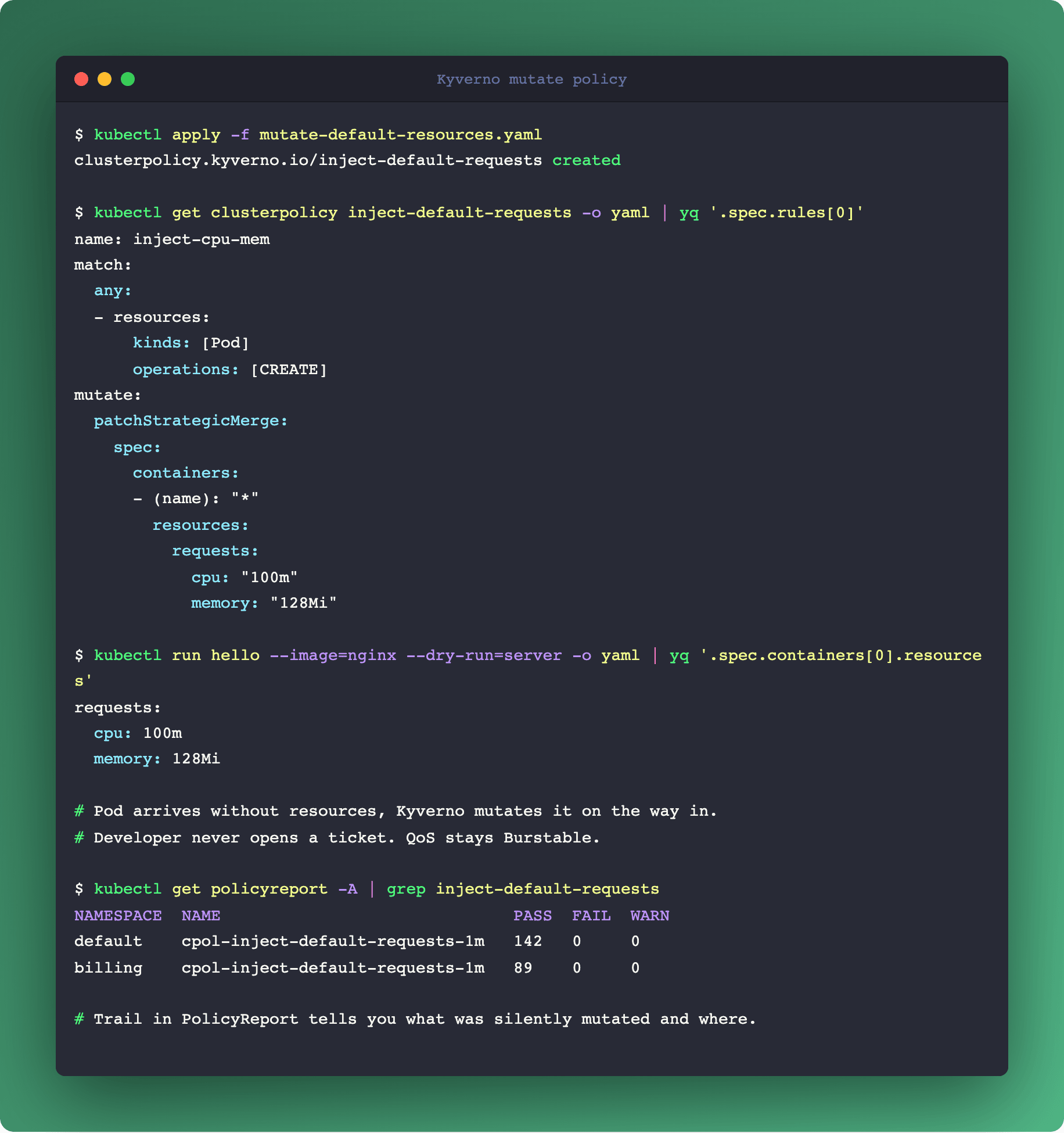
Patterns that belong in Mutate, not Validate:
Inject resource requests when a Pod omits them, so you stop landing in BestEffort QoS by accident.
Add a default securityContext (
runAsNonRoot: true,readOnlyRootFilesystem: true) to legacy charts you don't own.Strip the service account token (
automountServiceAccountToken: false) for workloads that don't call the Kubernetes API. One line of governance closes Step 1 of last week's pivot chain.Add cost-center labels from namespace annotations. FinOps attribution without involving application teams.
Rewrite image references to pull from an internal registry mirror, so egress auditing lives in one place.
The architectural idea: Validate is the loud gate that stops bad things from entering, Mutate is the quiet correction that makes them acceptable on the way in. Both belong in a platform. Most platforms ship only the loud one.
There's a real warning attached. Mutate can hide misconfiguration. A pod arrives malformed, Kyverno silently fixes it, nobody learns. Pair every non-trivial Mutate with a policy report, and pipe it to an OpenTelemetry span or an audit stream. Without that trail, Mutate becomes a shadow config layer that outlives the engineer who wrote it.
Rule of thumb I use: if the fix is objective and the developer has no legitimate reason to object, Mutate. If there's a judgment call or a domain meaning the platform shouldn't override, Validate.
Links
Generate rules make cross-namespace propagation trivial
Stop reaching for reflector-style third-party tools.
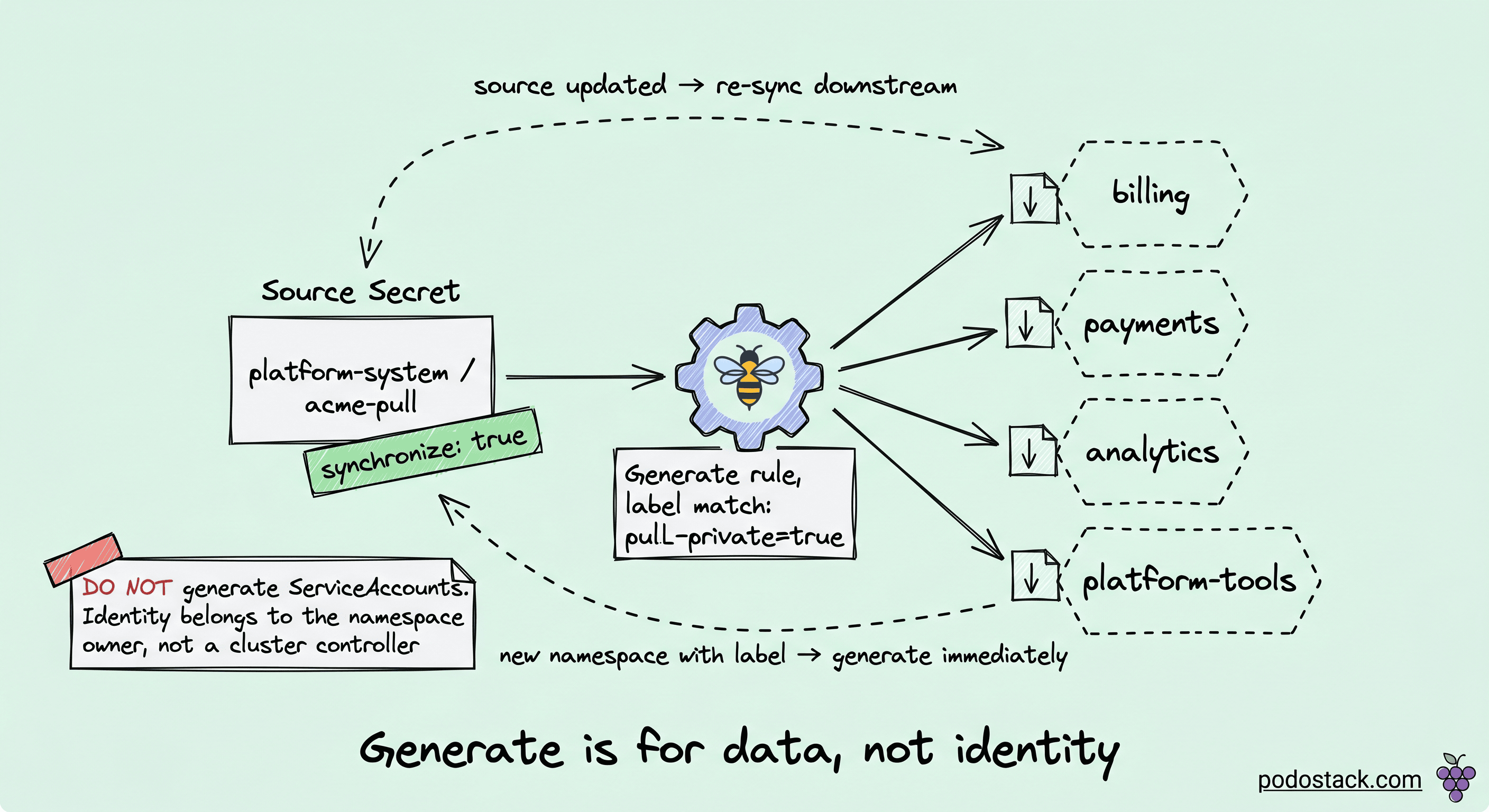
Every platform team eventually has to distribute the same resource across many namespaces. A TLS wildcard cert. A docker-registry pull secret. A default NetworkPolicy baseline. A CA bundle for in-house registries. The usual answers are all wrong:
Helm post-install hooks run once, drift after any change.
Argo CD ApplicationSets get ugly for dozens of tenants.
Reflector (the third-party controller) is one more binary in your supply chain.
Kyverno Generate rule is the clean answer. Declare one source resource, declare a destination selector, Kyverno watches both. On source change, downstream copies update. On namespace create, generate fires immediately. With synchronize: true, it becomes bidirectional: manual edits on a downstream copy get reverted back to source.
Concrete examples worth building:
Docker-registry pull secret in
platform-system, copied into every namespace with labelpull-private: true.cert-manager-issued wildcard TLS secret in
cert-manager, copied into every tenant namespace that needs ingress.A baseline NetworkPolicy in
policy-templates, instantiated in every new namespace as the default-deny starting point. This alone closes an entire class of lateral-movement attacks from last week's Step 3.
One anti-pattern worth calling out: don't generate ServiceAccounts with broad permissions via Generate rules. Technically it works. It also breaks RBAC reasoning because the identity that holds a privilege was created by a cluster-scope controller rather than declared by the namespace owner. Generate is for data. RBAC still belongs in the hands of the team that owns the namespace.
Links
Cleanup policies plus kor: making orphans visible
Governance is also about what leaves the cluster.
Every cluster accretes orphans. ConfigMaps from deleted Deployments. Secrets from rotated workloads. Services pointing at Pods that are gone. ServiceAccounts with no RoleBindings. Roles that nothing binds to. It's the kind of debt nobody wants to own and everyone pays for.
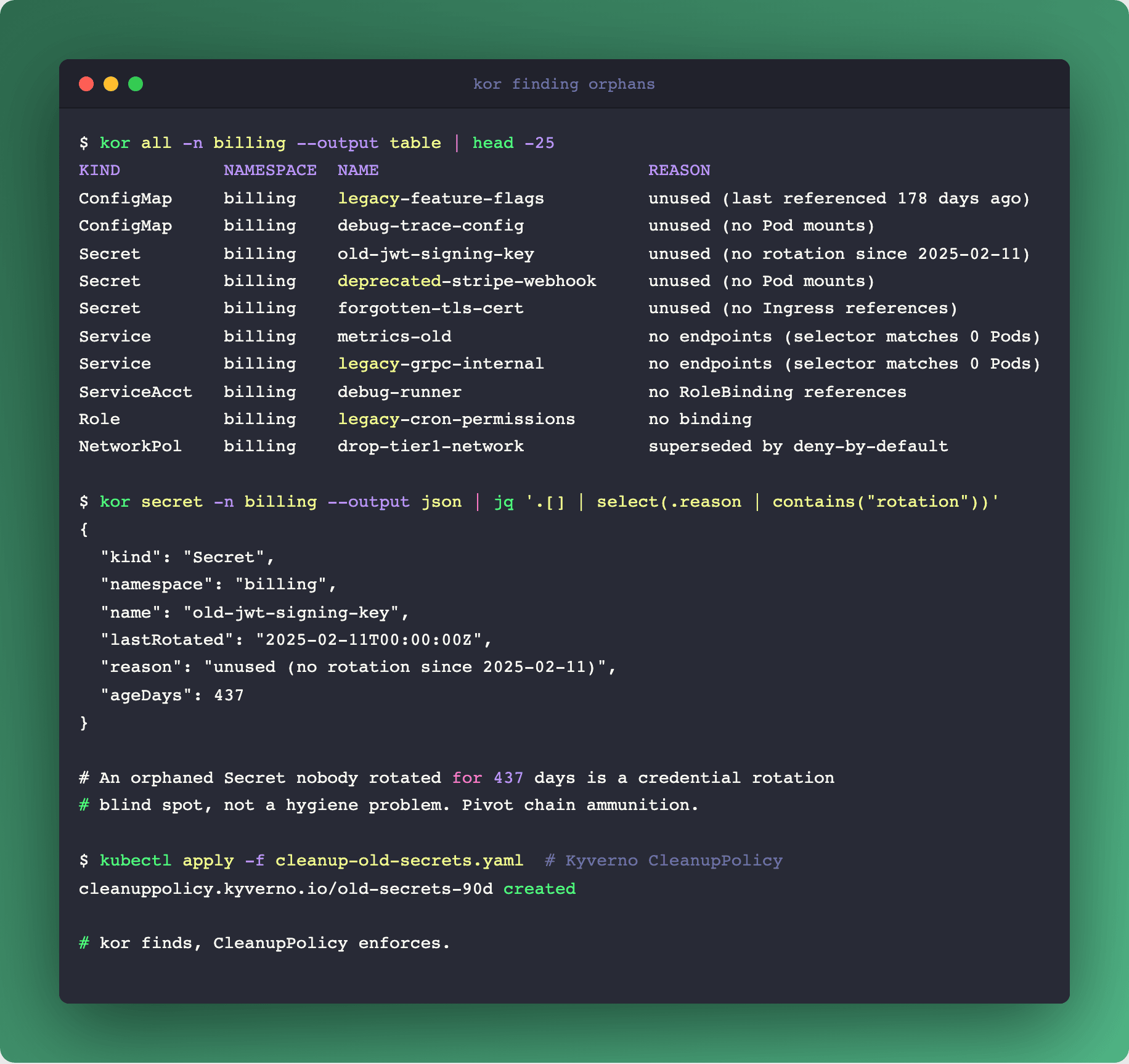
Two tools that compose cleanly.
Kyverno CleanupPolicy (built-in since 1.10) gives you declarative TTL. "PVC untouched for 30 days, delete it." Scheduled cleanup via cron expression, or on-event triggers. Always run in auditing: true mode for a week before switching to enforce, because the first cleanup policy a team writes is almost always too eager.
kor (github.com/yonahd/kor) is a CLI that finds orphans Kubernetes-native tools miss. It doesn't just list unused ConfigMaps, it finds Secrets that aren't mounted, Services whose selectors match zero Pods, ServiceAccounts that nothing references, ClusterRoles with no bindings. Output in table|json|yaml|csv so it slots into any pipeline.
A workflow that earns its keep:
Run
kor all --output jsonas a scheduled Job in each namespace.Pipe findings to a Slack channel per team. Namespace owners decide what's safe to delete.
Promote high-confidence categories (abandoned Secrets older than 90 days, Services with no endpoints for 30 days) into Kyverno CleanupPolicy as enforced rules.
Why this matters beyond cost: an orphaned Secret is a credential-rotation blind spot. The pentester's view from last week (Podo #015, Step 1) lists SA tokens as the primary pivot. If nobody knows that Secret exists, nobody rotates it, and the pivot path stays open indefinitely. Hygiene is security.
Links
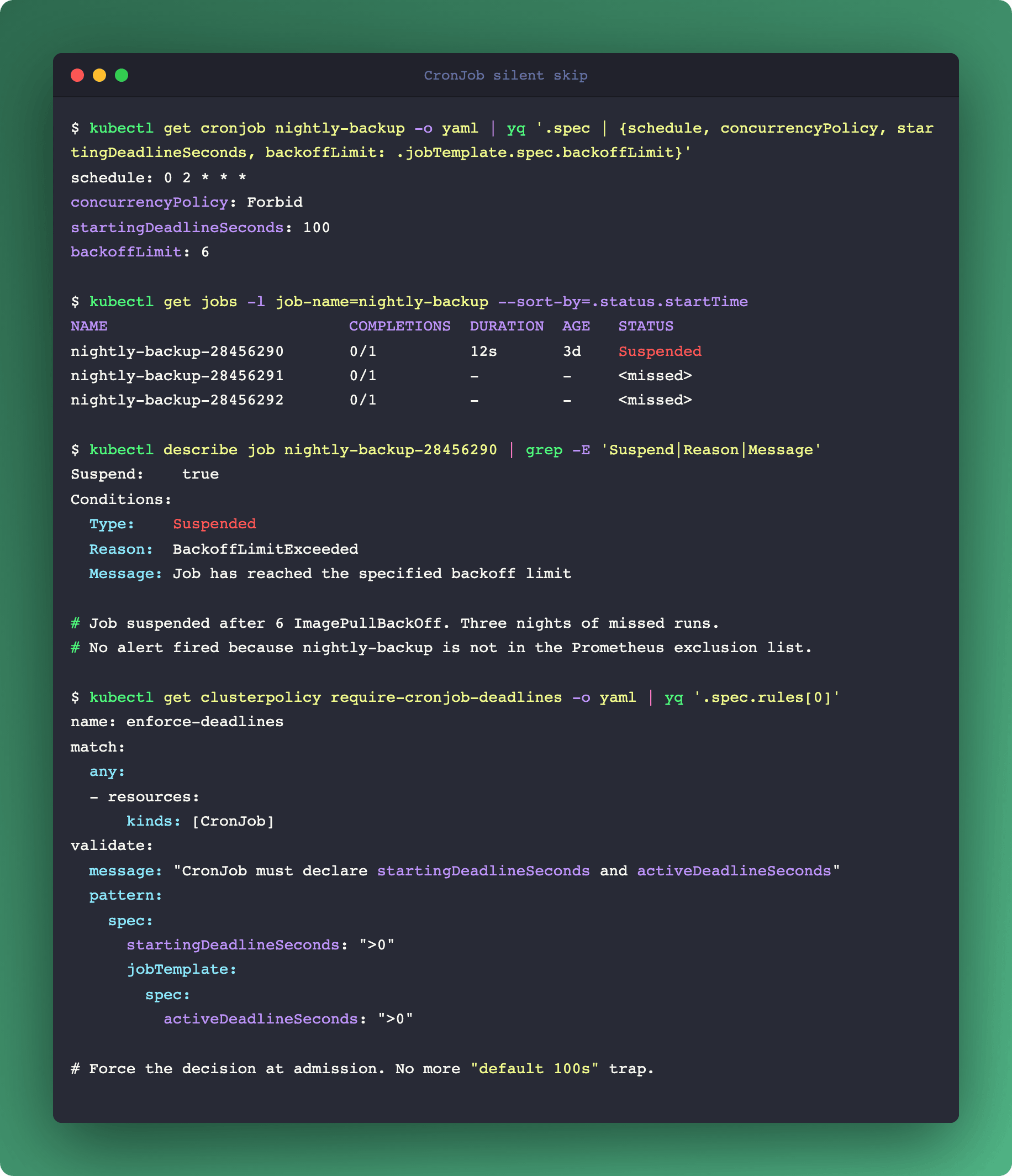
CronJob has seven failure modes nobody warned you about
The quietest workload in Kubernetes has the loudest silent failures.
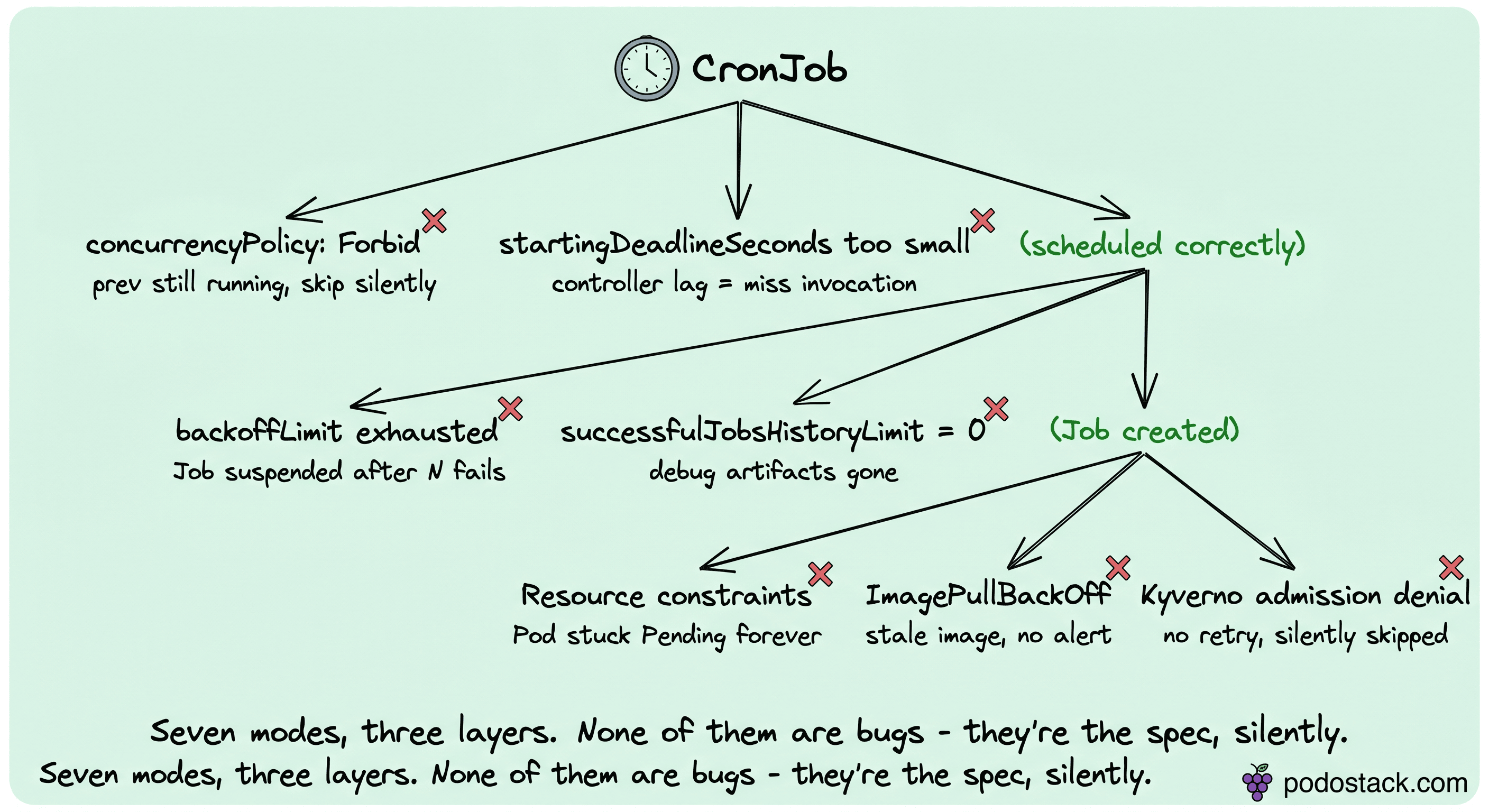
CronJob looks simple. You write a cron expression, you get a scheduled Job. No syslog-style notification when it fails. No on-call alert when it stops running. Three layers (CronJob → Job → Pod), each with its own silent-failure mode.
Seven modes, ordered by frequency in real clusters:
concurrencyPolicy: Forbid. Default is Allow, but many charts flip this to Forbid to avoid overlap. If the previous Job is still running when the next schedule fires, the new one is silently skipped. No error, no event, just a missed run.
startingDeadlineSeconds too small. If the controller lags behind (busy apiserver, scheduler backlog) beyond this window, the invocation is skipped. Set it too short, you miss runs under load. Leave it null, it's valid forever. Some charts ship a 100-second default that is a trap on busy clusters.
backoffLimit exhausted. After N Pod failures (default 6), Kubernetes suspends the Job. The next scheduled time creates a fresh Job, but the suspended one lingers in
kubectl get jobsas confusing noise, and nobody alerts you that your nightly backup stopped three days ago.successfulJobsHistoryLimit and failedJobsHistoryLimit. Set to zero, you lose debug artifacts the moment something breaks. Set too high, etcd pays the bill.
Resource constraints, Pod stuck Pending. No Node fits the requests. CronJob itself doesn't time out a Pending Pod.
activeDeadlineSecondson the Job is the watchdog; set it explicitly.ImagePullBackOff on a stale image reference. Nobody notices that the nightly backup hasn't pulled a fresh image in three weeks because the registry auth rotated. The Job fires, can't pull, backs off, cycles through retries, exhausts backoffLimit, goes silent.
Kyverno-blocked Job. An admission denial returns no retry. The CronJob controller marks the invocation complete without ever creating a Pod. Your policy is doing the right thing and your scheduler is doing the right thing, and together they silently skip a workload.
Vendor-neutral monitoring, because there's no native answer:
kube_cronjob_next_schedule_timefrom kube-state-metrics. Alert whentime() - last_schedule_time > expected_interval * 2.A heartbeat beacon emitted from inside the Job container to an external endpoint. Independent of Kubernetes state, so you notice when Kubernetes lies to you.
A Kyverno validate rule that rejects CronJobs without an explicit
startingDeadlineSecondsandactiveDeadlineSeconds, forcing the author to make the decision.
CronJob is the surface where Kyverno governance earns its keep at the architectural layer. The failure modes aren't bugs, they're the K8s API doing exactly what it said in the spec, silently.
Links
The image hygiene pipeline
Seven vendor-neutral tools, one lifecycle.
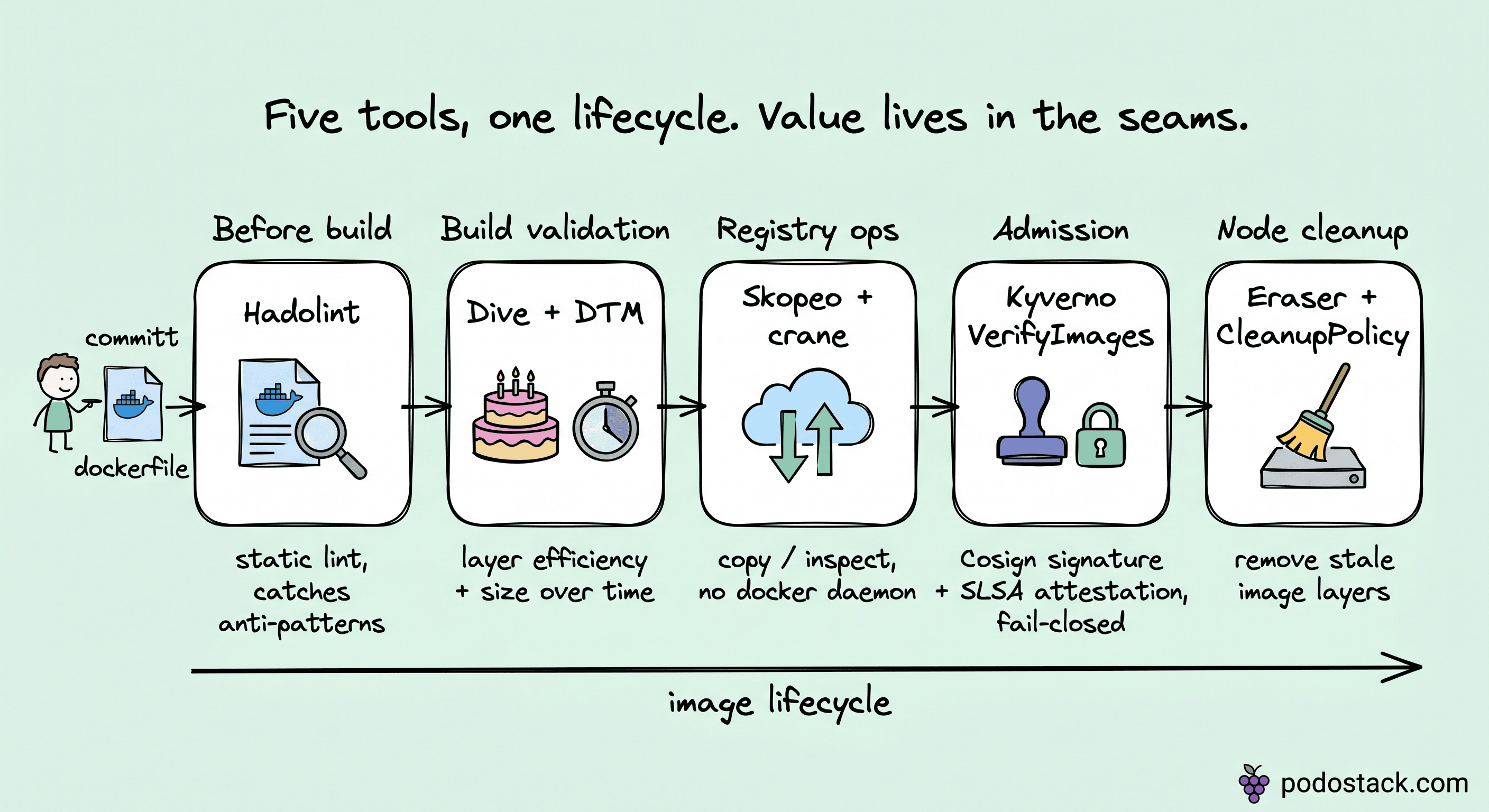
This could be seven compilation blocks. It's more useful as one pipeline. Each stage has a tool that does one thing well, and the seams between stages are where platforms earn their quality.
Stage 1 - before build. Hadolint lints the Dockerfile statically. Catches anti-patterns (ADD instead of COPY, apt-get without cleanup, wildcard tags) before a single byte of CI compute burns. Runs in pre-commit and in CI, identical rules.
Stage 2 - build validation. Dive walks the layered image and scores efficiency. "Your image is 1.2 GB and 40% is wasted in inter-layer churn" is a blameless ticket nobody fights. Docker Time Machine adds the time axis: how did this image grow across 20 commits, which PR bloated it by 300 MB. dtm registry myapp --last 20 plots the curve. commit-bisect finds the culprit. Small caveat: DTM has 64 stars and slowed down in late 2025, so check repo pulse before baking into your pipeline. If it stalls, Dive alone still earns Stage 2.
Stage 3 - registry operations. Skopeo and Google's crane both do registry ops without a Docker daemon. Skopeo copies, inspects, and deletes across registries. crane reads partial layers, does content addressing, and fits in slim CI containers. Both CRI-agnostic, both safe to run in ephemeral build agents.
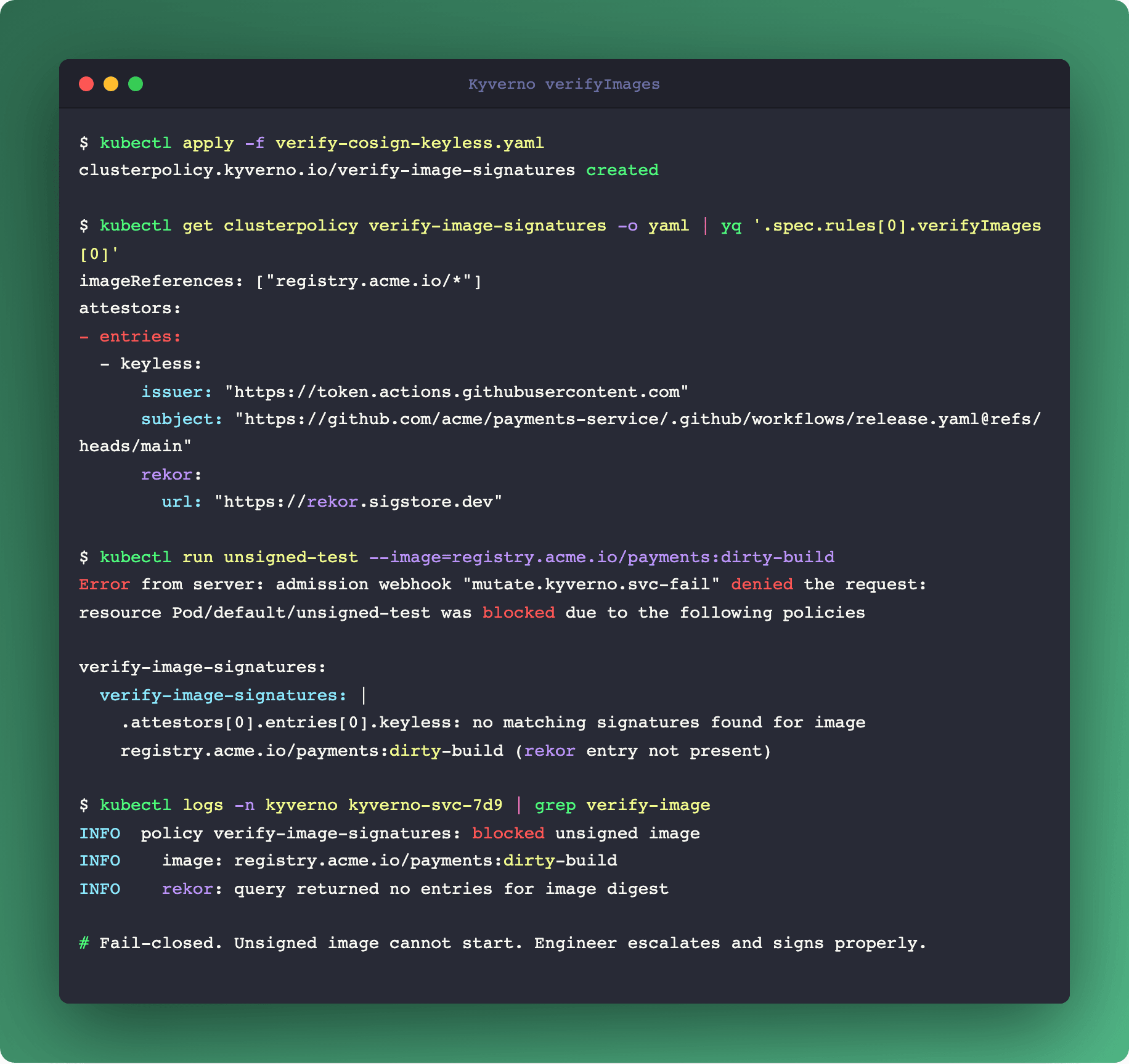
Stage 4 - admission (Kyverno VerifyImages). This is the supply-chain gate. Kyverno checks Cosign signatures (keyless flow via OIDC, signatures anchored in the rekor transparency log) and SLSA provenance attestations before allowing a Pod to start. Fail-closed: unsigned image, Pod rejection, human escalation. Podo #005 walked through why you want this, and the Sigstore/SLSA ecosystem has matured since. If you implemented #005 already, this is where Kyverno enforces the artifact you produced then.
Stage 5 - node cleanup. Eraser removes stale images from nodes. Kyverno CleanupPolicy scrubs workloads that use imagePullPolicy: Always on tags that no longer exist in the registry. Together they close the loop on images that otherwise accumulate quietly on every node forever.
The architectural point: this is one pipeline, not seven tools. A team that adopts Dive without Eraser fixes their build efficiency and still ships nodes with 40 GB of dead image layers. A team that enforces VerifyImages without Hadolint blocks a lot of things at admission that should have been caught in CI. The value is in the seams.
Links
Closing
Kyverno as a governance engine, not an admission controller:
Mutate for objective corrections, not just Validate for loud gates.
Generate for cross-namespace propagation, retire the third-party reflectors.
CleanupPolicy plus kor for the orphan debt nobody else owns.
CronJob rules for the failure modes nobody alerts on.
VerifyImages at the end of a pipeline, not as a standalone policy.
Five rule types, one engine. If your platform ships 80 Kyverno policies and they're all Validate plus VerifyImages, you have four surfaces left to explore.
Which rule type did your team reach for last? Most platforms hit Validate and stop. Generate usually clicks next. CleanupPolicy is the one teams discover after a quarter of orphan debt.
Next week: Postgres on Kubernetes - five places where the control plane and the database fight over the same recovery, and what running CloudNativePG actually buys you.
- Ilia