
Debezium in production: the failure modes the docs don't lead with
Fail-fast on broker outages, poison messages, schema evolution traps, and the Postgres replication slot that will eat your database


Debezium is the CDC tool of record for most teams running event-driven architectures on top of traditional databases. The docs make it look straightforward: deploy Debezium Server, point it at your database, connect a sink, watch change events flow. It does work that way. Until one of three things happens and nobody warned you they were possible.
This isn't a getting-started post. Assumption: you've deployed Debezium, you know what CDC means, you understand the basic WAL/binlog reading model. This is the operational underside: the failure modes that define whether your CDC pipeline survives contact with production.
Fail-fast is a feature, not a bug
Debezium's first operational surprise for new operators: the moment the downstream broker is unreachable, Debezium halts. Not "log an error and retry." Not "buffer and continue." Literally stops reading the transaction log. Consumer lag (we'll use the word "lag" but the Debezium metric is MilliSecondsBehindSource) climbs linearly until the broker comes back.
This looks broken. It isn't. It's correct behavior, and once you understand why, you want it that way.
Debezium's design guarantee is that every committed database transaction produces exactly one downstream event, in order, without loss. The moment you weaken that guarantee, CDC stops being a reliable event stream and becomes best-effort logging. If the broker is down and Debezium were to buffer in memory and later dump, you've just introduced reorder, duplication, and possible loss (when Debezium itself OOMs during the buffering).
Fail-fast preserves the guarantee. When the broker comes back, Debezium resumes from exactly where it stopped. Zero loss, zero reorder, zero duplication. The cost is visible lag, which is exactly what you want your monitoring to catch.
The operational corollary: alert on MilliSecondsBehindSource. If it grows beyond your recovery-time objective, the broker or the pipeline is broken, not Debezium.
Links
Poison messages: the DLQ is mandatory
A CDC event format that a consumer can't parse (wrong type, unexpected null, schema mismatch) is a poison message. A naive consumer NACKs with requeue=true. The message goes back to the queue head. The consumer picks it up, fails again, NACKs again. Thousands of times a minute. The queue blocks behind one bad event.
The fix at the broker layer is a Dead Letter Exchange (DLX). Configure the main queue with x-dead-letter-exchange pointing to a DLX, and configure your consumer to NACK with requeue=false after N retries. RabbitMQ routes the failed message to the DLQ where an engineer can inspect it, while new events keep flowing.
The pattern applies uniformly. Kafka has dead-letter topics. Pulsar has dead-letter topics. NATS JetStream has similar constructs. Whatever broker you use, declare the dead-letter path at queue-create time, never as an afterthought.
Common causes of poison messages in Debezium pipelines:
Consumer code written against an older schema version.
A SMT (Single Message Transform) bug on the Debezium side produces malformed output.
A database column changed from one type to another and consumers assumed the old type.
The third one brings us to the next failure mode.
Links
Schema evolution: the quiet breaker
Databases aren't static. Eventually a DBA runs ALTER TABLE. Three cases, three different failure shapes:
ADD COLUMN. Debezium sees the DDL, picks up the new column, starts including it in the after block of JSON events. Consumers that ignore unknown fields (forward compatibility) keep working. Consumers that strictly validate schema fail on the first message.
DROP COLUMN. The field disappears from new messages. Consumers that require the field fail. Consumers with backward compatibility (default missing field to null or skip) keep working.
ALTER COLUMN TYPE. The most dangerous. If the database changes INT to TEXT, Debezium starts sending strings where consumers expected numbers. Validators pass (the schema says string), but application code breaks on type mismatch. Consumers without strict schema validation crash.
Without a Schema Registry (which Kafka has and RabbitMQ doesn't), the responsibility for compatibility lands entirely on consumer developers. Operational rule: every DDL in the source database must be reviewed against the CDC consumer list. Breaking changes (type changes, renames, drops of required fields) need a migration plan, not a deploy-and-hope.
Links
The replication slot that will eat your database
This one is Postgres-specific and it's the one that takes databases down.
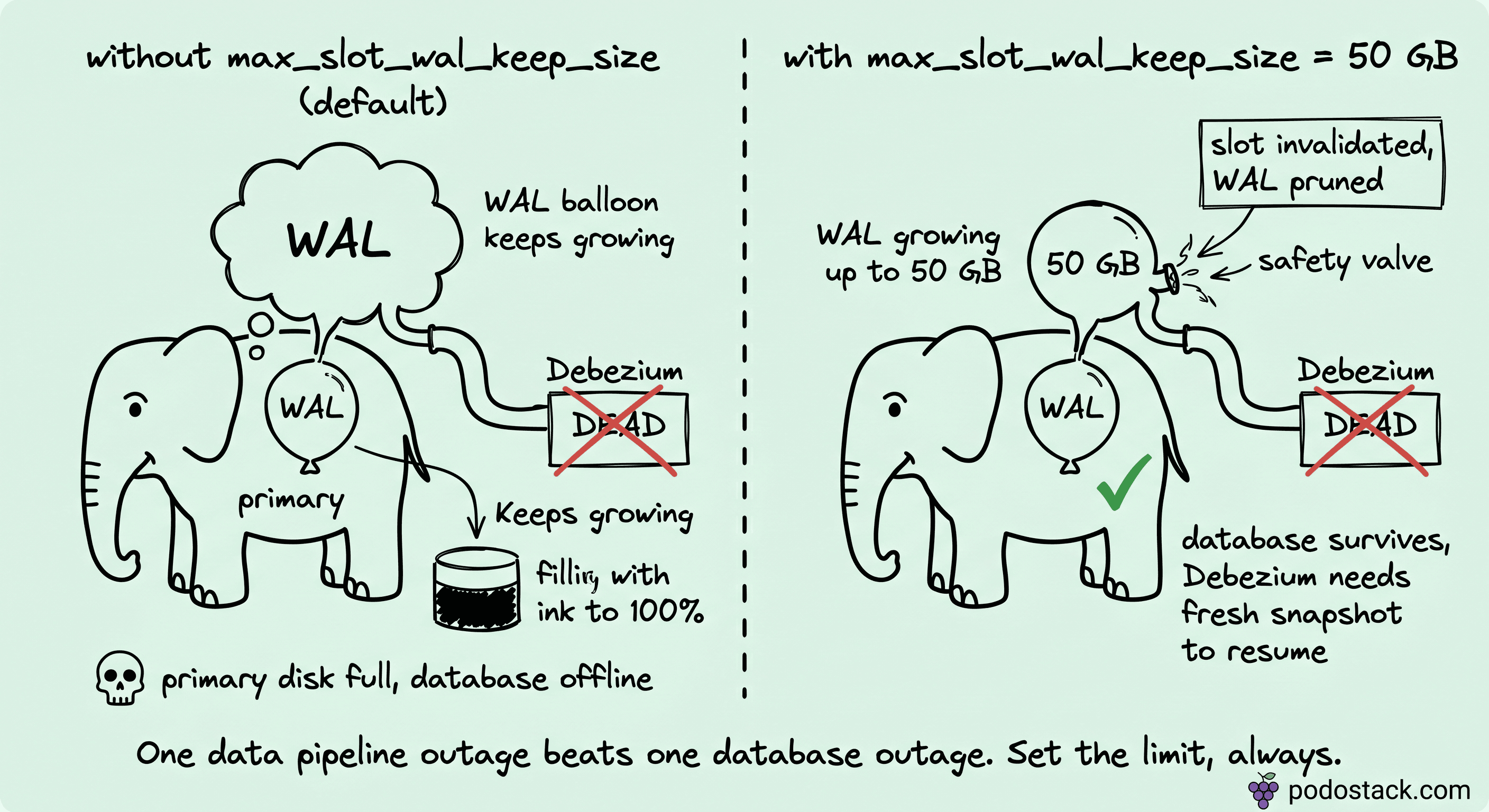
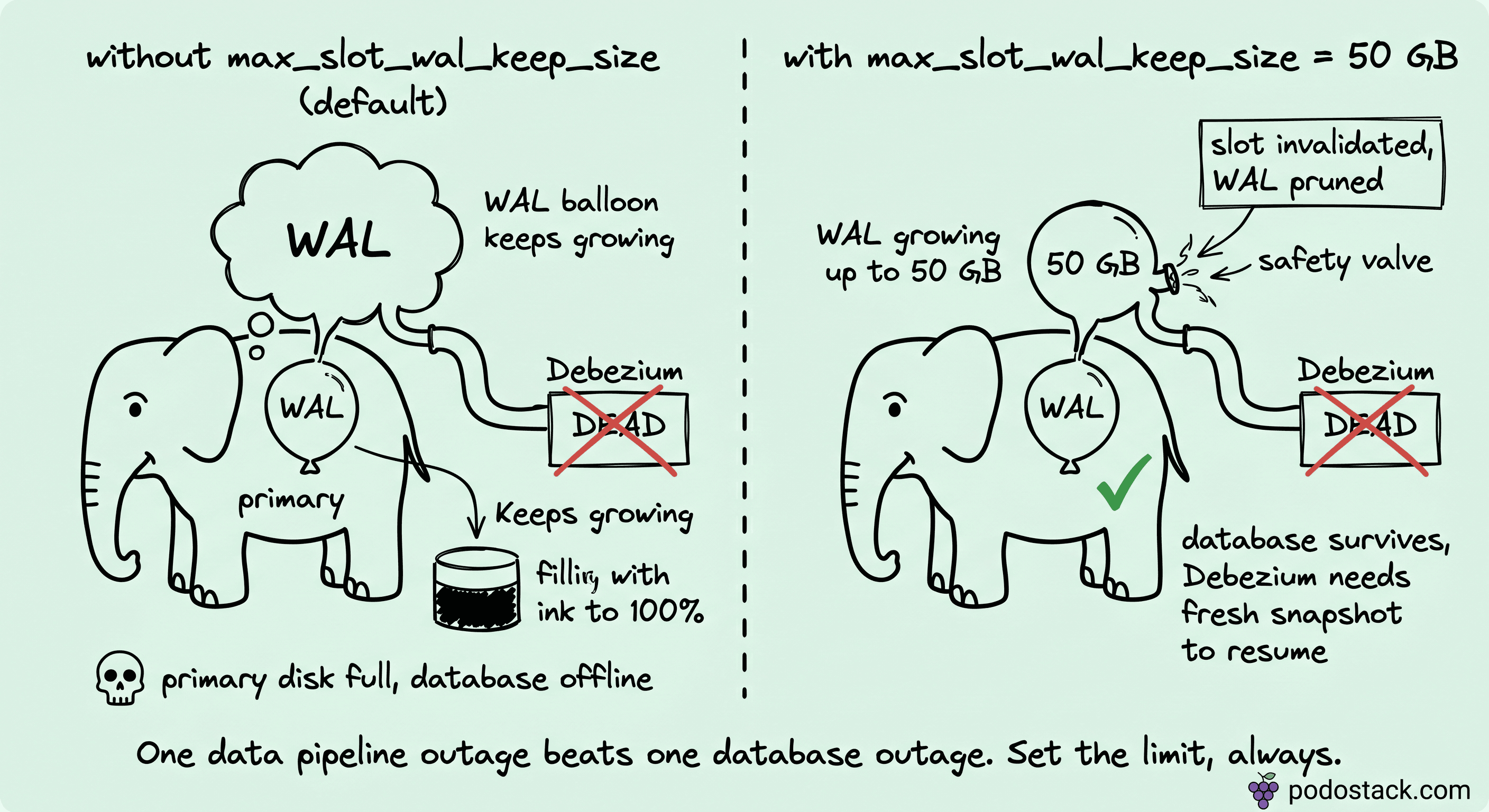
Debezium for Postgres uses logical replication slots. A slot is a Postgres object that tracks where a particular replica (Debezium, in this case) is in the WAL stream. As long as the slot exists, Postgres will not delete WAL segments beyond the slot's position. That's the whole point of slots: they guarantee no WAL is discarded before the replica consumes it.
The failure mode: Debezium Server dies (OOM, network partition, the RabbitMQ downtime from the first section, a misconfiguration). The slot stays. Postgres keeps WAL because the slot says "the replica will come back for these." WAL volume grows. Disk fills. Postgres, eventually, can't write anymore. The main database goes offline. Every application that depends on it fails.
I've seen this take down payment systems. It's not theoretical.
The saving parameter, introduced in Postgres 13, is max_slot_wal_keep_size. Set it (50 GB is a reasonable starting point) and Postgres enforces a hard limit. When unclaimed WAL exceeds the threshold, Postgres invalidates the slot, deletes the WAL, and keeps itself alive. Debezium loses its position and requires a fresh snapshot to resume. That's the correct trade: one data pipeline outage, resolved by reinitialization, versus a database outage that takes the whole business down.
Every Debezium-on-Postgres deployment needs max_slot_wal_keep_size set. The default is unlimited, which is the wrong default. Set the limit explicitly.
Links
The metrics dashboard that matters
JMX metrics from Debezium plus the broker's own metrics form the operational dashboard. The ones that earn their space:

From Debezium:
MilliSecondsBehindSource: the lag metric. Normal is milliseconds. Alert on seconds.TotalNumberOfEventsSeen: throughput. Used for capacity planning and anomaly detection (sudden drop = upstream stopped).SnapshotRemaining: when initial snapshot is running, how many tables or chunks are left.
From the broker (RabbitMQ in the example, same concepts on Kafka):
messages_unacknowledged: consumer activity. Growing = consumer stuck.messages_ready: queue depth. Growing = consumers slower than producers.
From the database:
pg_replication_slots.confirmed_flush_lsnvspg_current_wal_lsn: the gap tells you exactly how much WAL is waiting for Debezium to consume. Growing = Debezium can't keep up or is down.
Three layers of metrics, one pipeline. If any layer degrades, you need the signal before consumers notice.
Links
Summary
Debezium works, and Debezium is deterministic about how it fails. The difficulty is that the failures aren't the kind docs lead with. They're operational: broker outages freeze the pipeline, bad events can block queues without DLQs, schema changes break consumers silently, and most dangerously, a dead Debezium can take your database down if Postgres slot limits aren't set.
None of these are bugs. They're the cost of the "exactly once, in order, no loss" guarantee Debezium provides. Running it in production means understanding the trade and configuring around it.
Checklist for a Debezium-on-Postgres deployment:
Set
max_slot_wal_keep_sizeto a sane limit (default is unlimited).Declare Dead Letter Exchanges or dead-letter topics on every downstream queue.
Monitor
MilliSecondsBehindSourcewith page-level alerts.Treat every source-database DDL as a consumer contract event.
Accept that a cold restart after slot invalidation requires a fresh snapshot.
For CDC concepts and when to use it at all, see the published Change Data Capture deep dive. For the broker side specifically, RabbitMQ in Production covers the message-delivery guarantees that pair with Debezium's.