
Podo #017: Postgres on Kubernetes: Five Places the Control Plane and the Database Fight Over Recovery
CloudNativePG quorum failover, local vs replicated storage, quorum-aware PDB, connection pooler placement, and backup primitives

Welcome back to Podo Stack. Running Postgres on Kubernetes stopped being controversial a while ago. The right operators exist, the storage stack works, people actually do this in production. What hasn't changed is that every team that tries it rediscovers the same five decisions, usually under pressure, usually in the wrong order.
This issue walks through those five. Not "should you run Postgres on K8s." Assume yes. The interesting question is what the control plane and the database should do differently than a VM setup, and where their recovery instincts collide.
Here's what's good this week.
CloudNativePG quorum failover and the K8s recovery race
When the control plane and the database both try to fix the same outage.
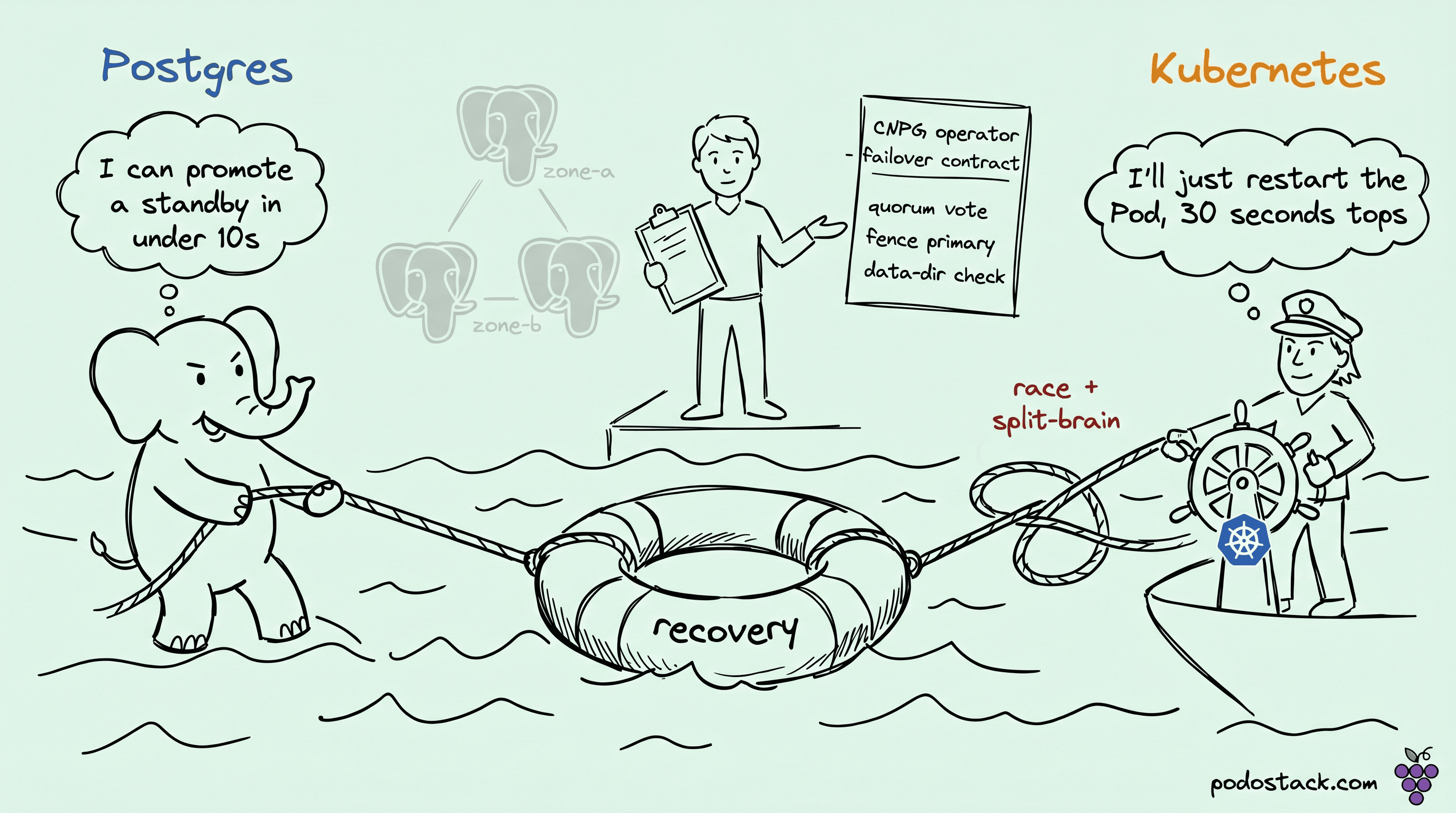
CloudNativePG (CNCF incubating) is the Postgres operator most teams converge on. The reason it earned that position is the quorum-based failover introduced in v1.28, which solves a problem every HA database on Kubernetes eventually hits: the control plane and the data plane both want to recover the same outage, and they don't coordinate.
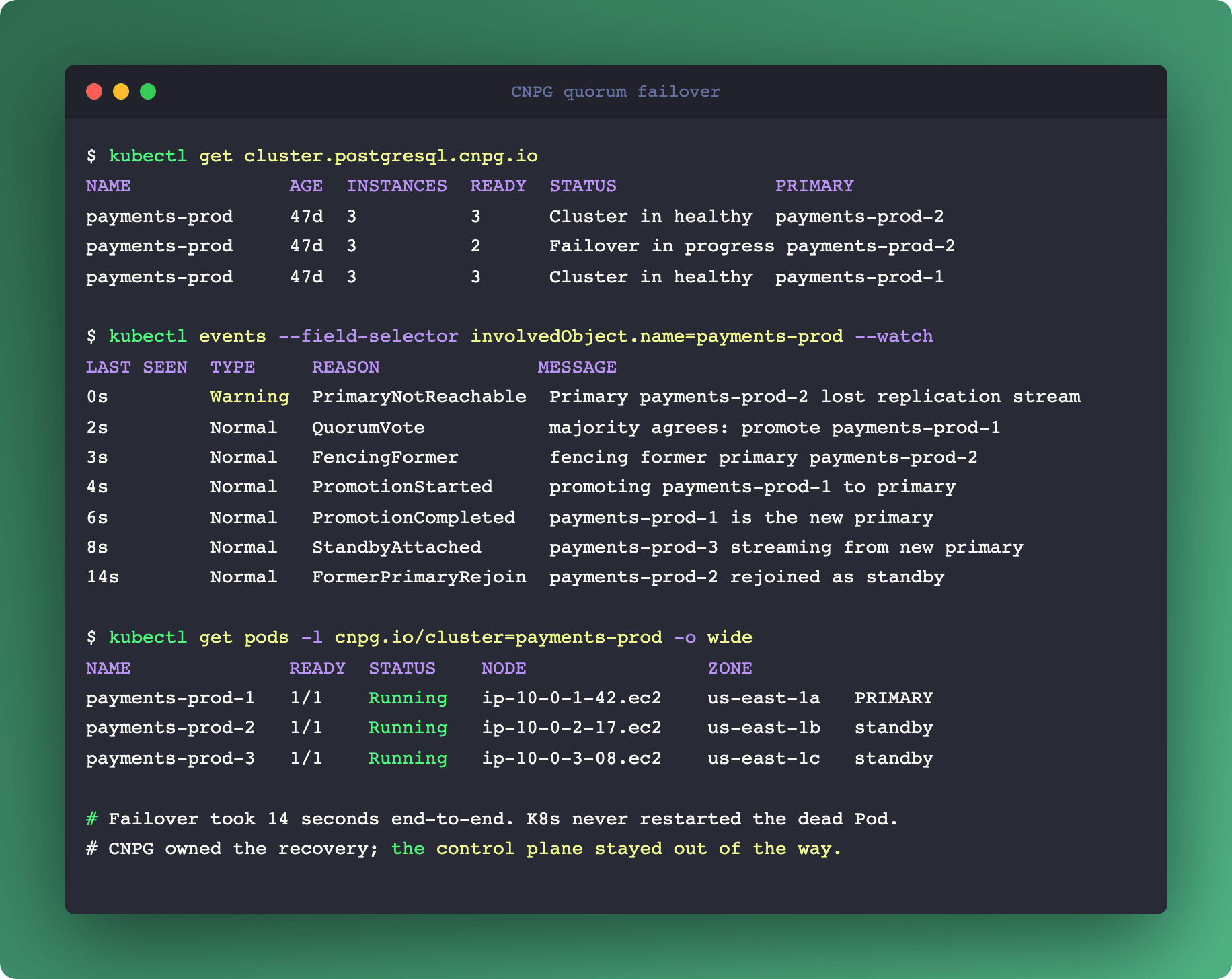
A standard three-replica CNPG cluster is one primary plus two standbys, synchronous replication, quorum write-ack. When the primary Pod stops responding, two recovery paths kick in:
Kubernetes side: the kubelet on that node marks the Pod NotReady. After the configured
terminationGracePeriodSecondsplus the controller reconcile delay, K8s attempts to restart the Pod. Expected downtime: 30-60 seconds.CNPG side: the instance manager inside the surviving standbys detects primary loss through replication stream health checks. If the quorum majority agrees, it promotes a standby to primary. Expected downtime: under 10 seconds.
Both are trying to help. They also can't see each other. K8s thinks "my Pod is unhealthy, I will restart it." CNPG thinks "the primary is down, I will promote a standby." Two recovery paths, one cluster, competing endings.
The race shows up concretely as split-brain attempts. K8s successfully restarts the original Pod. It comes back up expecting to be primary, reconnects, and discovers a different Pod has been promoted. If fencing isn't configured or the instance manager doesn't correctly demote, you can briefly have two Pods accepting writes. That's unrecoverable corruption.
CNPG handles this with instance-manager health checks that explicitly fence the former primary before promotion, and with a data directory consistency check at startup. The operator tells K8s, through StatefulSet ordering and specific annotations, not to race.
The architectural rule: if your database has opinions about recovery, the control plane should defer. CNPG's operator pattern registers this preference explicitly. Running Postgres under a bare StatefulSet without an operator (or under a naive operator) is what produces the race.
Links
Local vs replicated storage: let whoever replicates better own it
Database-level replication and storage-level replication compete.
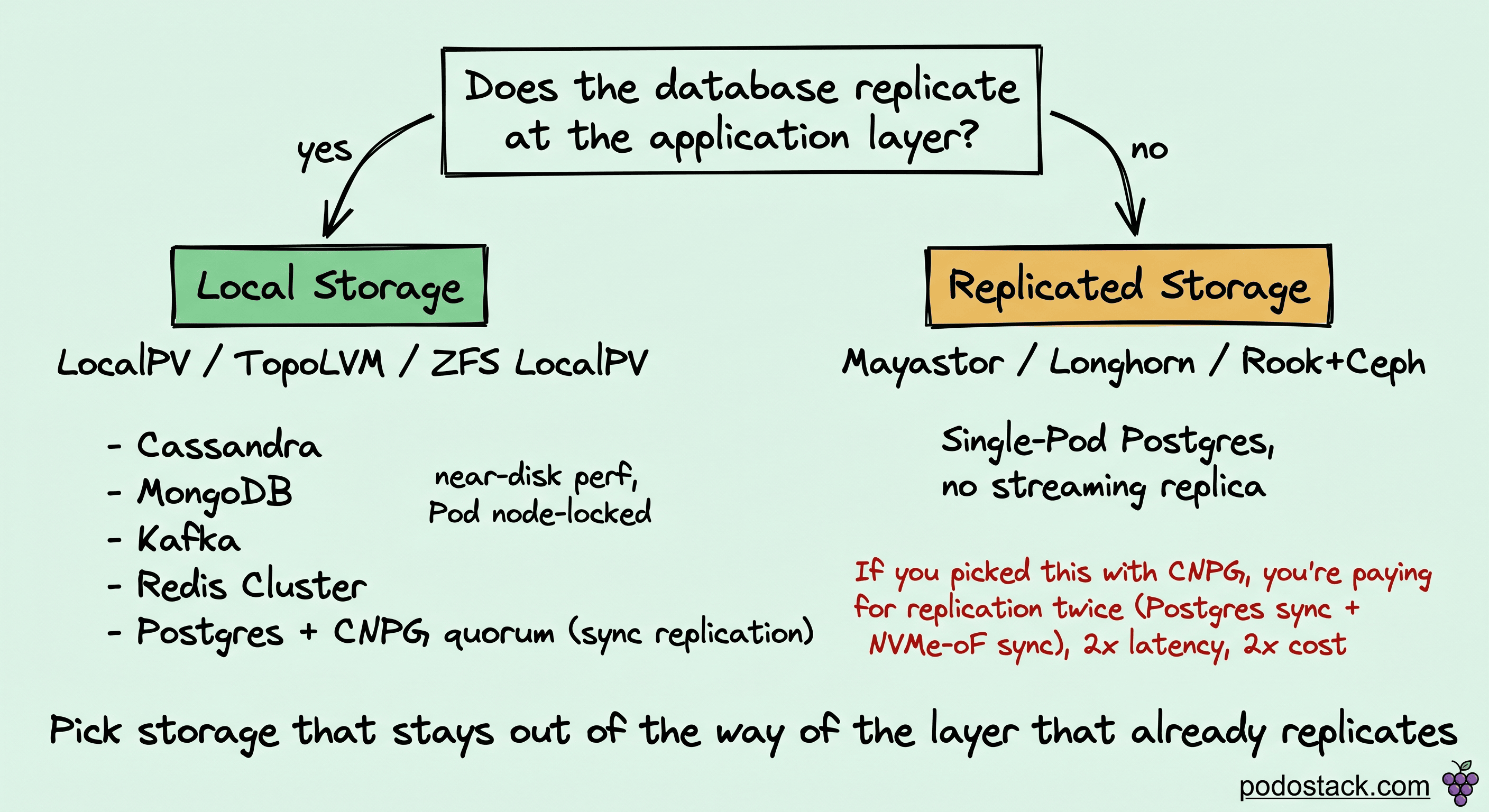
Kubernetes gives you two broad storage models:
Local storage (hostpath, LocalPV, TopoLVM, ZFS LocalPV). Near-disk performance, no network layer on the hot path. Pod is pinned to the node that holds the data.
Replicated storage (Mayastor/OpenEBS, Longhorn, Rook/Ceph). Storage replicates across nodes at the block or volume layer through NVMe-oF or similar. Pod can reschedule to any node.
The instinct is to always pick replicated storage because "we need durability." That instinct is often wrong.
The question is: which layer knows more about your data? For workloads that already replicate at the application level, storage-level replication is a second, unaware copy of the same work, paying latency and cost twice.
Cassandra, MongoDB, Elasticsearch: replicate at the application layer. Local storage is the right pick. Storage-level replication adds latency without improving durability.
Kafka: in-cluster replication is a first-class feature. Local storage.
Redis Cluster: data already sharded and replicated by the cluster mode. Local storage.
Postgres with CNPG streaming replication + quorum: the database already handles replication. Local storage.
Postgres with a single Pod, no streaming replication: replicated storage is the answer because nothing else is replicating.
The case against replicated storage for a CNPG cluster is concrete. Mayastor replicates through NVMe-oF: every write on the primary Pod becomes a network round-trip to two other hosts before fsync returns. Your synchronous Postgres replication already makes two round-trips to standbys. You're paying for replication twice, through two different mechanisms that don't cooperate.
For a CNPG production cluster, the standard choice is local storage (LocalPV on NVMe) with sufficient replica count at the database layer. Storage is the fastest and simplest component. Durability lives in the replica set.
One asterisk: backup and disaster recovery still need something that reaches across nodes. Covered in block 5.
Links
Quorum-aware PodDisruptionBudgets and zone anti-affinity
The default PDB will cheerfully take down your cluster.
Kubernetes ships PodDisruptionBudgets as a safety against voluntary evictions (node drains, cluster upgrades, Karpenter consolidation). The default pattern (max one unavailable Pod) works for most Deployments. For quorum-based systems it is exactly wrong.
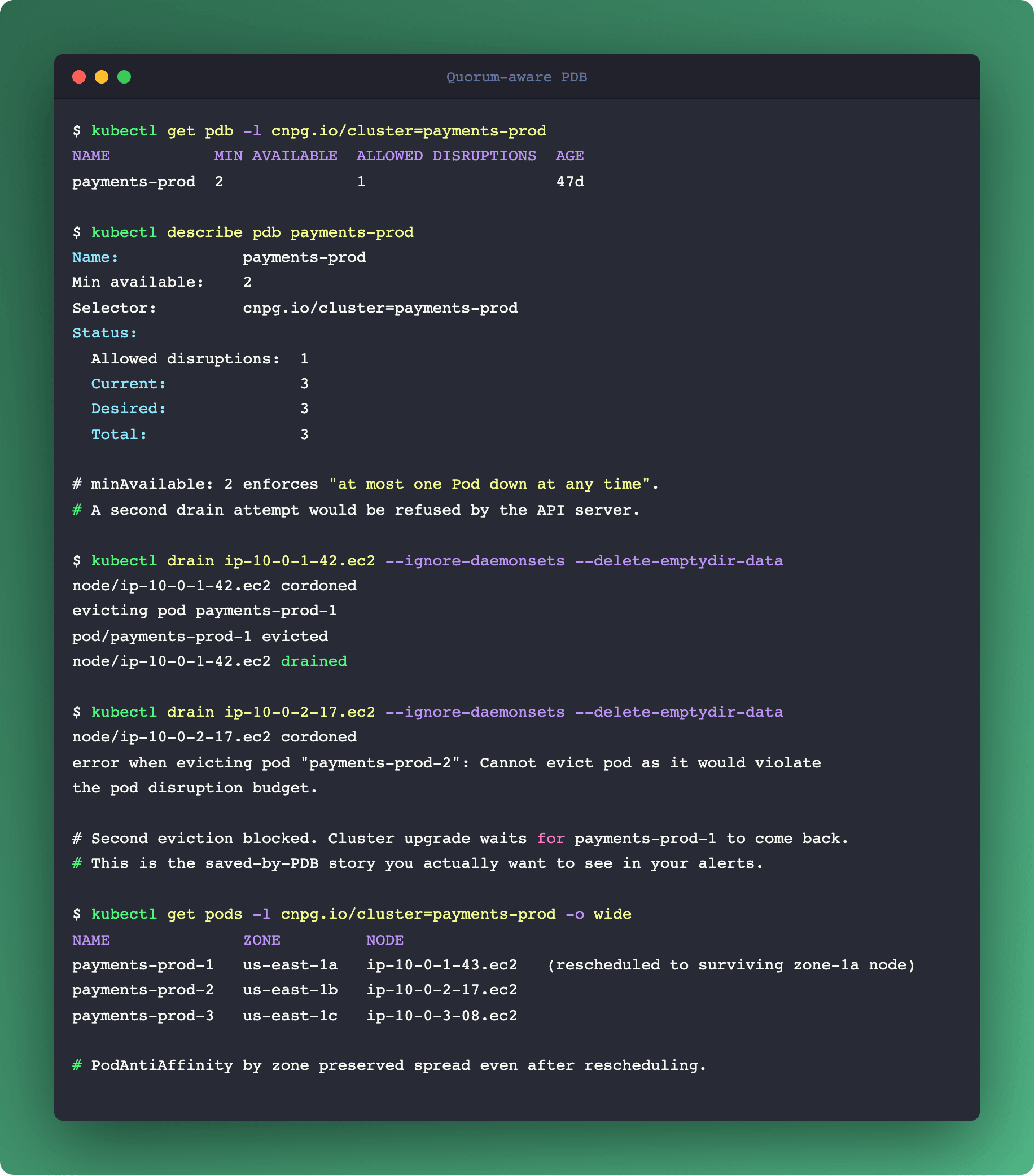
A three-replica CNPG cluster can tolerate one Pod down. Two Pods down is loss of quorum, which is loss of write availability, which is an outage. A PDB with maxUnavailable: 1 allows exactly the disruption pattern that takes you down during a normal cluster upgrade.
The correct PDB for a three-replica quorum system is minAvailable: 2. Kubernetes will refuse to evict the second Pod if only one is still running. Node upgrades now serialize across Postgres Pods, even if the upgrade tool wanted to parallelize.
The second half of the story is placement. If all three Postgres Pods end up on the same physical rack, same zone, or (worst case) the same host, the PDB doesn't save you from a single rack power outage. PodAntiAffinity with zone topology keys is the standard fix:
Required (hard) anti-affinity: one Postgres Pod per zone. If your cluster has fewer healthy zones than replicas, Pods stay Pending until a new zone comes up. Correct for strict HA.
Preferred (soft) anti-affinity: try to spread, fall back to colocation. Correct for dev clusters with fewer zones than replicas.
There's a parallel to Podo #008 (RabbitMQ quorum queues). The same algebra applies: quorum system, N replicas, zone spread, minAvailable ≥ floor(N/2)+1. The shape repeats across every quorum technology.
Kyverno (Podo #016) can enforce this at admission: reject CNPG Cluster resources that don't have a properly-sized PDB and zone anti-affinity. One policy, half the quorum-PDB mistakes prevented at deploy time.
Links
Connection pooler placement: the pod-vs-sidecar question
PgBouncer is a pod, not a library. Where it runs matters.
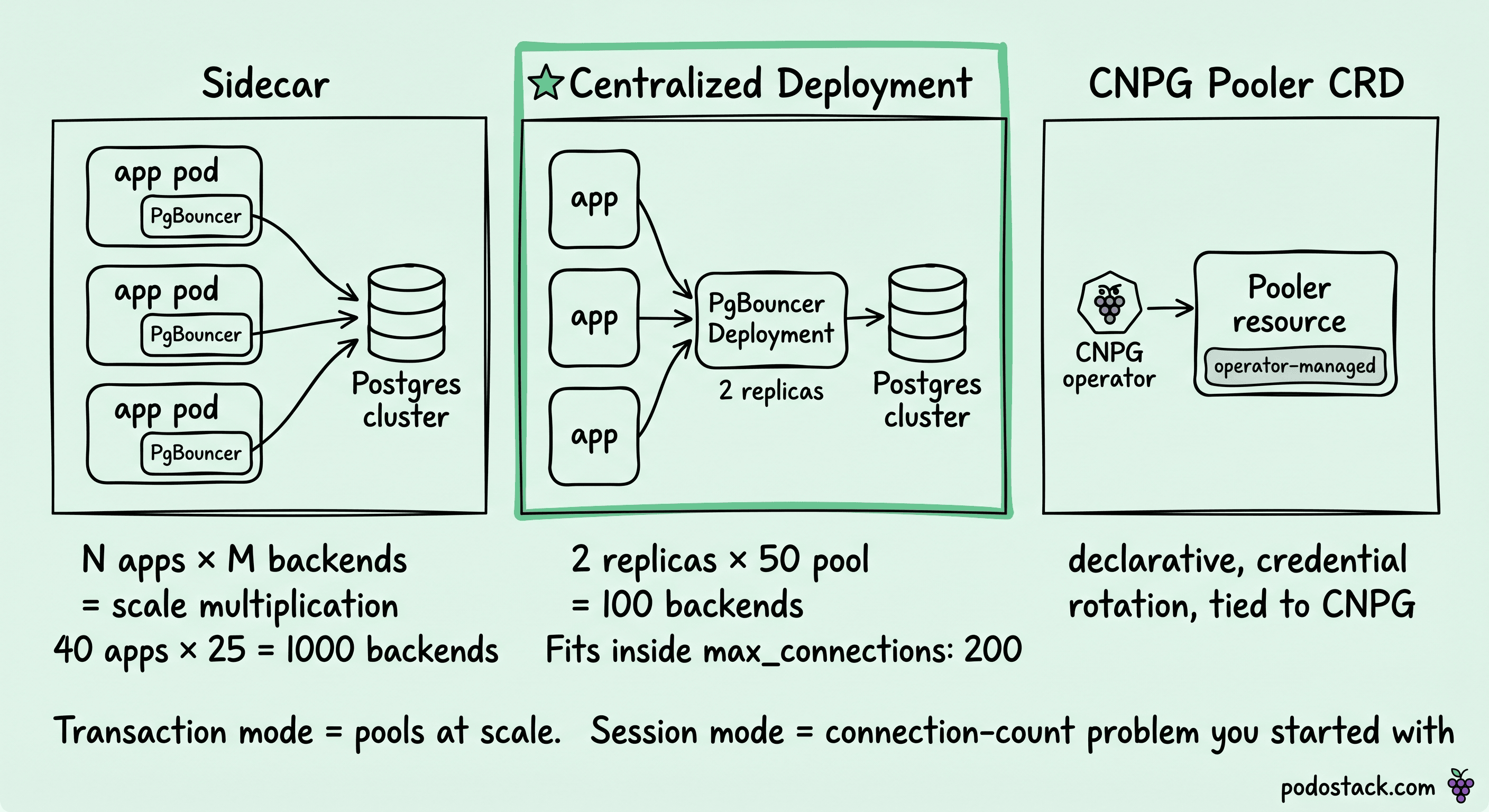
Postgres has a hard limit on concurrent backend connections (default max_connections: 100, typical production tuning: 200-500). Applications that open a connection per request overwhelm this quickly. The standard answer is a connection pooler: PgBouncer (most common) or Pgpool-II (more features, more footprint).

On Kubernetes, the pooler is a Pod. The architectural question is where that Pod lives.
Per-application sidecar. PgBouncer runs as a sidecar in every application Pod. Application connects to localhost:6432. Pros: connection locality, no network hop to reach the pooler. Cons: N application Pods × M backend connections per pooler = scale multiplication. Pool math gets ugly fast.
Centralized pooler Deployment. One PgBouncer Deployment (two or three replicas) in front of the cluster. All applications connect through it. Pros: single place to tune pool sizes, observe activity, rotate credentials. Cons: one more network hop, the pooler is a new failure domain.
CNPG-managed pooler (Pooler CRD). CNPG integrates PgBouncer as a first-class resource. The operator manages configuration, credentials, and rotation. Pros: declarative, operator-managed, consistent with the rest of the cluster. Cons: tied to CNPG, not directly portable.
For most production setups, the answer is centralized pooler, two or three replicas, behind a ClusterIP Service. The connection math is the deciding factor: total backend connections at Postgres equals (pooler replicas × pool size). A pool size of 50 across two pooler Pods gives you 100 backend connections, which fits inside a standard max_connections: 200 with room for replication and admin.
Transaction mode vs session mode is the other choice the docs rarely lead with. Transaction mode is the one that actually pools at scale. Session mode holds a backend connection for the entire client session and gives you the same connection count problem you started with. Transaction mode is the default production choice unless the application uses session-scoped features (prepared statements without protocol: extended, LISTEN/NOTIFY, advisory locks).
Links
Backup primitives: application-layer and storage-layer, both
One backup mechanism is not enough.
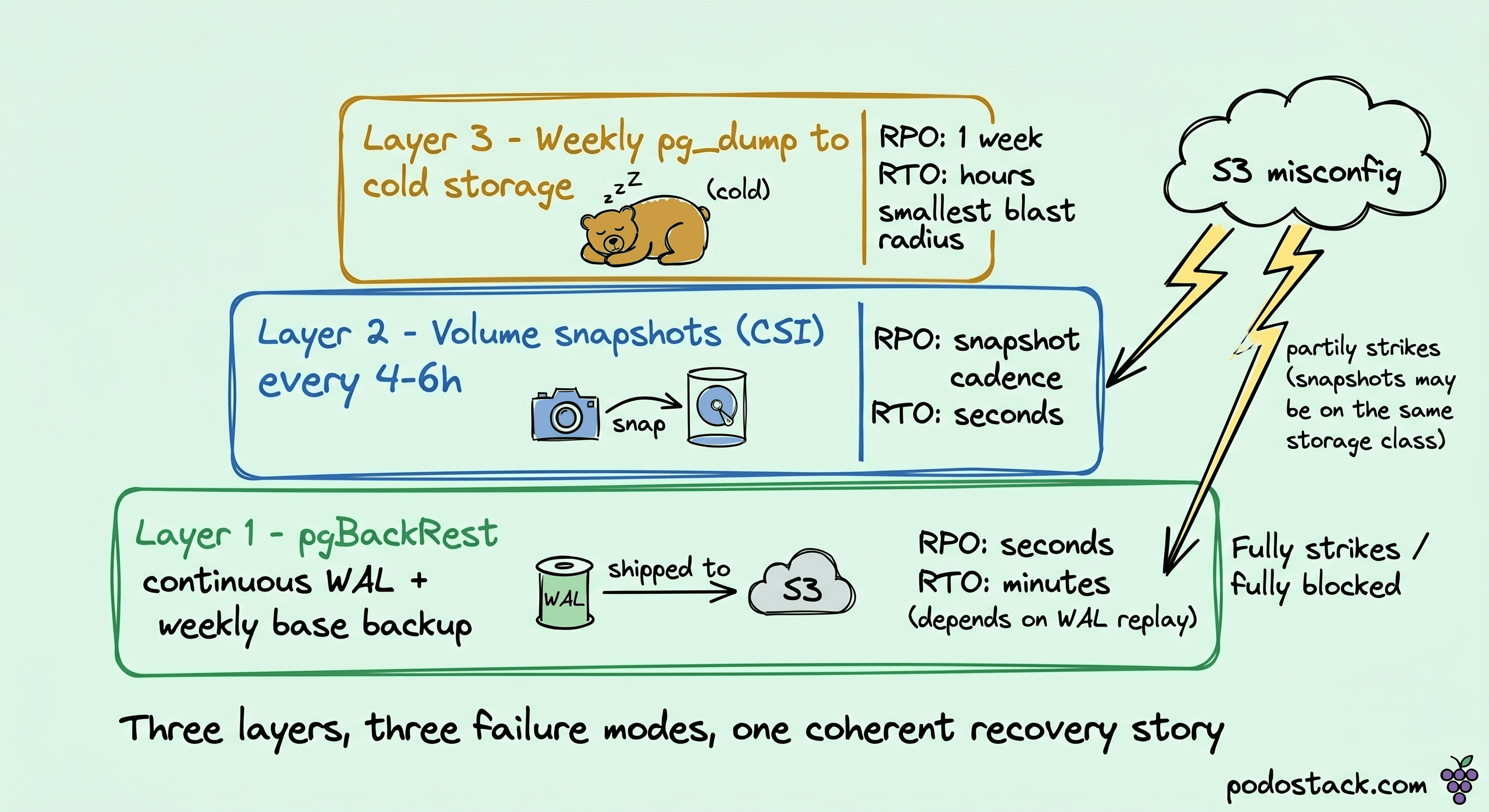
Backup on Kubernetes for a database is usually framed as a choice: Volume Snapshots (CSI-based) vs logical dumps vs application-layer continuous archiving. The framing is wrong. Production databases need two layers, not one.
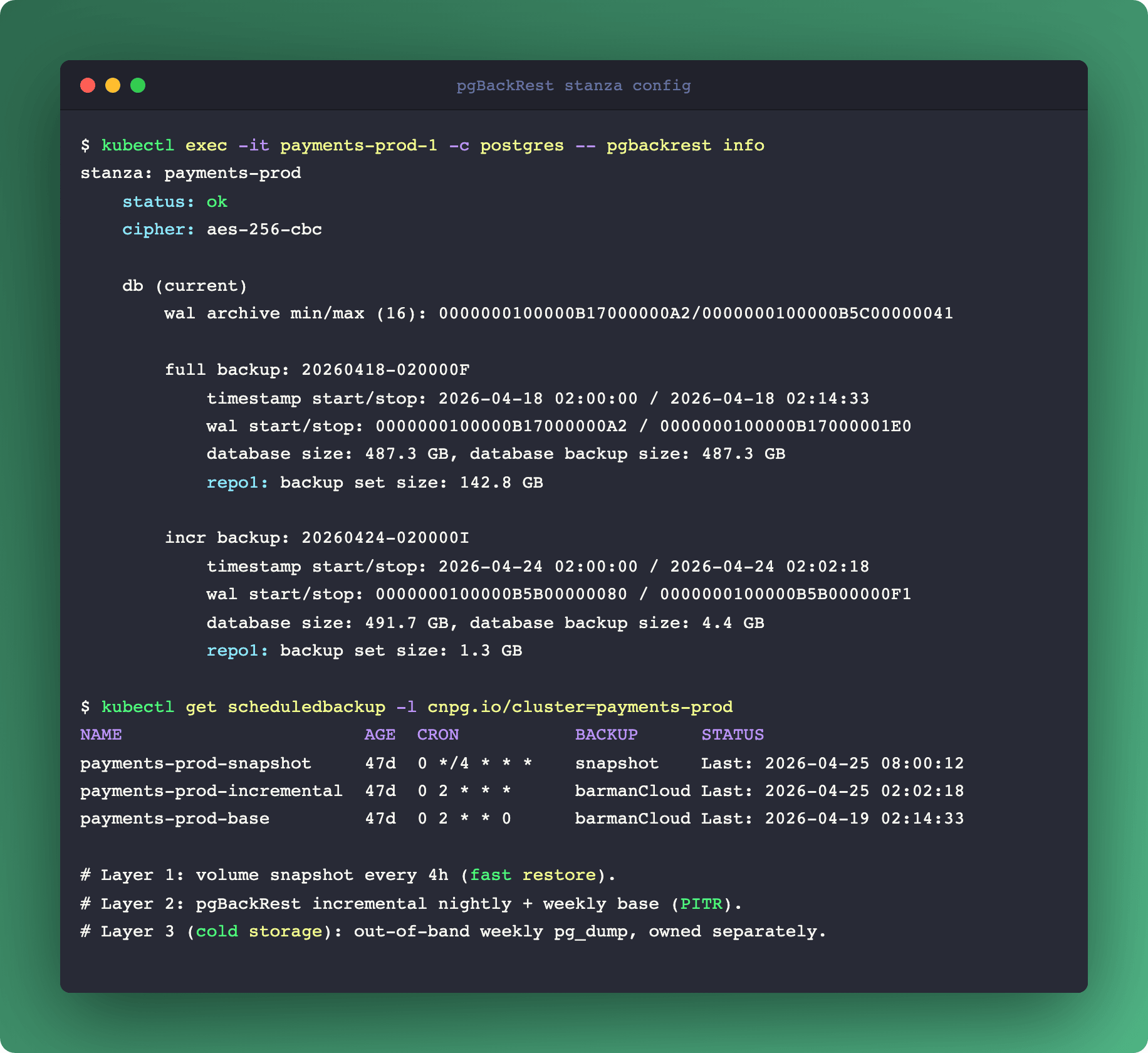
Continuous WAL archiving with pgBackRest (or CNPG's integrated Barman Cloud). Every WAL segment ships to object storage as it closes. Combined with a periodic base backup, you can recover to any point in time within retention. RPO of seconds, RTO proportional to the amount of WAL to replay.
Volume snapshots (CSI) for fast restore. A snapshot of the Postgres data volume taken while Postgres is consistent (via pg_backup_start/pg_backup_stop or CNPG's snapshot-aware API) lets you clone the cluster to a new Pod in minutes instead of waiting for a full base backup restore. RPO is the snapshot cadence. RTO is seconds to minutes.
Logical dumps (pg_dump) are the third layer. Not for disaster recovery, for schema migration portability, cross-version upgrades, and per-schema cloning. Running pg_dump on a primary under load is costly; run it on a standby or against a snapshot clone.
The layered architecture:
Volume snapshots every 4-6 hours. Fast restore for "the index got corrupted" cases.
pgBackRest continuous archive, base backup once a week. Point-in-time recovery for "we dropped the table in production yesterday."
Weekly logical dump to cold storage. Insurance against the other two failing together, plus migration utility.
CNPG integrates the first two through its Backup and ScheduledBackup CRDs. Volume snapshots run via the CSI plugin of your storage driver (most modern CSI plugins support VolumeSnapshot). pgBackRest or Barman Cloud run through CNPG's backup.barmanObjectStore configuration.
One warning: never rely on a single backup layer. An S3 misconfiguration that blocks pgBackRest also blocks your only recovery path. Snapshots live on the same storage class that's probably implicated in whatever caused the outage. Logical dumps have the smallest blast radius and take the longest to restore. Three layers, three failure modes, one coherent recovery story.
Links
Closing
Five decisions, one theme: the control plane and the database can't ignore each other, but they also can't both own the same concern. Every one of these is a boundary question:
Failover: who detects, who promotes, who fences?
Storage: which layer replicates?
Disruption: who guards quorum, who schedules drains?
Connections: where does the pool live?
Backup: which layer is the authority for a given recovery time?
Run Postgres on Kubernetes the way CNPG expects it: K8s handles placement and networking, the operator handles the database state machine, and the two talk through a narrow interface. Run it without that contract and you discover, usually at 3 AM, that both sides are racing to fix the same outage.
Which of these hit your team first? The failover race is the most common. The storage decision is the one that bites cost hardest. The backup one is the one that actually wakes people up.
Next week's evergreens pair well with this story. Cilium Egress Gateway gives database clients a stable outbound IP when your Postgres cluster needs to reach an external service. Linux inode exhaustion is the filesystem-level failure that hits WAL-heavy workloads first.
- Ilia